机器学习-有监督学习-神经网络
线性模型
- 向量版本
y = ⟨ w , x ⟩ + b y = langle w, x rangle + b y=⟨w,x⟩+b
分类与回归
- 懂得两者区别
- 激活函数,损失函数
感知机模型
- 感知机模型的本质是线性模型,再加上激活函数
- 训练数据、损失函数、梯度下降,小批量梯度下降
- 神经网络算法整体流程:
- 初始化网络
- 前向传播
- 计算损失
- 计算微分
- 梯度下降
- 反向传播
- 多轮迭代
激活函数
- 给模型加入拟合非线性功能
- 常见激活函数:
- Sigmoid 0-1 二分类
- Tanh -1-1
- relu:公认的最好用的激活函数之一
维度诅咒
- 神经网络可以很轻松的对隐藏层进行升降维
- 升维后密度呈现指数形式逐渐下降,维度太大会过拟合
过拟合和欠拟合
- 训练误差:模型在训练集上的误差
- 泛化误差:模型在同样从原始样本的分布中抽取的无限多数据样本时模型误差的期望。现实世界不可能有无限多数据,所以只能将模型应用于独立的测试集来估计泛化误差。
- 过拟合:训练误差小,泛化误差大。
- 欠拟合:训练误差大,泛化误差大。
- 解决过拟合:
- 正则化:减少参数的大小
- 数据增强:对原始数据做变化增加数据量
- 降维:特征选择
- 集成学习:多个模型集成在一起
- 早停法:监控训练集和验证集的错误率
- 解决欠拟合:
- 添加新特征
- 增加模型复杂度
- 减少正则化系数
正则
- 正则:约束模型复杂度来防止过拟合现象的一种手段。模型复杂度是由模型参数量大小和参数的可取值范围共同决定的。
- 正则两个方向:约束模型参数量(dropout),约束模型取值范围(weight decay)
- 利用均方范数作为硬性和软性限制
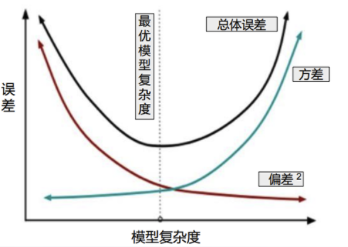
- 衡量模型好坏可以看方差和偏差
| 低方差 | 高方差 | |
|---|---|---|
| 低偏差 | 预测准,且较集中 | 预测准,但较分散 |
| 高偏差 | 预测不准,且较集中 | 预测不准,且比较分散 |
-
L1正则化:使参数稀疏化
损失函数 = 原始损失函数 + λ 2 m ∑ i = 1 n ∣ w i ∣ text{损失函数} = text{原始损失函数} + frac{lambda}{2m}sum_{i=1}^{n} |w_i| 损失函数=原始损失函数+2mλi=1∑n∣wi∣ -
L2正则化:降低参数范围
损失函数 = 原始损失函数 + λ 2 m ∑ i = 1 n w i 2 text{损失函数} = text{原始损失函数} + frac{lambda}{2m} sum_{i=1}^{n} w_i^2 损失函数=原始损失函数+2mλi=1∑nwi2 -
Dropout 对神经网络的节点进行随机的失活,训练时失活,预测是全部节点
-
集成学习是打比赛进行提点的一个很重要的方法
数据增强
- 成功的机器学习应用不是拥有最好的算法,而是拥有最多的数据!
- 当数据到达一定级数后,拥有相近的高准确度。
数值稳定性
- 计算机视觉,模型很大,数据集要好几万、好几亿。模型不大,要需要上百。
- 梯度消失
- 梯度爆炸
- 解决方法:数据归一化
- Z-Score归一化
- 最大最小归一化
- 原因:提升模型精度和收敛速度
神经网络大家族
CNN
- Image Search
- Image Labeling
- Image Segmantation
- Object Detection
- Object Tracking
- OCR
- Video Annotation
- Recommendation
- Image Classification
- Robot perception
- 以上分类不及1/10
RNN
- 语法语义分析
- 信息检索
- 自动文摘
- 文本数据挖掘
- 自动问答
- 机器翻译
- 知识图谱
- 情感分析
- 文本相似度
- 文本纠错
原理:下一层的输入不仅和原始输入有关,还和之前的输出有关
GNN(图神经网络)
- 芯片设计
- 场景分析与问题推理
- 推荐系统
- 欺诈检测与风控相关
- 知识图谱
- 道路交通的流量预测
- 自动驾驶(无人机等场景)
- 化学,医疗等场景
- 生物,制药等场景
- 社交网络
原理:图节点,边和整体进行训练
GAN
- 图像超分辨率
- 艺术创作
- 图像到图像的翻译(风格迁移)
- 文本到图像的翻译
- 图片编辑
- 服装翻译
- 照片表情符号
- 图片融合
- 图片修补
原理:生成器和判别器