【NLP的python库(02/4) 】:Spacy

一、说明
借助 Spacy,一个复杂的 NLP 库,可以使用用于各种 NLP 任务的不同训练模型。从标记化到词性标记再到实体识别,Spacy 还生成了精心设计的 Python 数据结构和强大的可视化效果。最重要的是,可以加载和微调不同的语言模型以适应特定领域的NLP任务。最后,Spacy提供了一个强大的管道对象,有助于混合内置和自定义的分词器,解析器,标记器和其他组件,以创建支持所有所需NLP任务的语言模型。
本文介绍空间。您将学习如何安装库、加载模型以及应用文本处理和文本语义任务,最后学习如何自定义空间模型。
本文的技术上下文是 和 。所有示例也应该适用于较新的版本。Python v3.11Spacy v3.5.3
这篇文章最初出现在博客 admantium.com。
二、Spacy库安装
Spacy 库可以通过 pip 安装:
python3 -m pip install spacy 所有 NLP 任务都需要首先加载模型。Spacy提供了基于不同语料库和不同语言的模型。查看完整的型号列表。一般来说,模型可以区分为其语料库的大小,这在NLP任务期间导致不同的结果,以及用于构建模型的技术,这是一种未知的内部格式或基于变压器的模型,例如Berta。
若要加载特定模型,可以使用以下代码片段:
python -m spacy download en_core_web_lg 三、自然语言处理任务
Spacy 支持以下任务:
文本处理
- 标记化
- 词形还原
文本语法
- 词性标记
文本语义
- 依赖关系解析
- 命名实体识别
文档语义
- 分类
此外,Spacy 还支持以下附加功能:
- 语料库管理
- 词向量
- 自定义 NLP 管道
- 模型训练
3.1 文本处理
当使用其中一个预训练语言模型时,Spacy 会自动应用文本处理基本要素。从技术上讲,文本处理围绕可配置的管道对象进行,该抽象类似于SciKit Learn管道对象。此处理始终从标记化开始,然后添加其他数据结构来丰富解析文本的信息。所有这些任务也可以自定义,例如交换标记器组件。以下说明仅关注使用预训练模型时的内置功能。
3.2 标记化
标记化是第一步,应用起来很简单:将加载的模型应用于文本,标记就会出现。
import spacy
nlp = spacy.load('en_core_web_lg')
# Source: Wikipedia, Artificial Intelligence, https://en.wikipedia.org/wiki/Artificial_intelligence
paragraph = '''Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding (known as an "AI winter"), followed by new approaches, success, and renewed funding. AI research has tried and discarded many different approaches, including simulating the brain, modeling human problem solving, formal logic, large databases of knowledge, and imitating animal behavior. In the first decades of the 21st century, highly mathematical and statistical machine learning has dominated the field, and this technique has proved highly successful, helping to solve many challenging problems throughout industry and academia.'''
doc = nlp(paragraph)
tokens = [token for token in doc]
print(tokens)
# [Artificial, intelligence, was, founded, as, an, academic, discipline3.3 Lematization勒马特化
引理是自动生成的;它们是令牌的属性。
doc = nlp(paragraph)
lemmas = [token.lemma_ for token in doc]
print(lemmas)
# ['artificial', 'intelligence', 'be', 'found', 'as', 'an', 'academic',可配置组件对规则或查找应用词形还原。要查看内置模型使用哪种模式,请执行以下代码:
lemmatizer = nlp.get_pipe("lemmatizer")
print(lemmatizer.mode)
# 'rule'在空间中没有词干。
3.4 、文本语法
3.4.1 词性标记
在 Spacy 中,词性标签有两种形式。该属性是令牌所属的绝对类别,其特征为通用 POS 标记。该属性是一个更细微的类别,它基于依赖项分析和命名实体识别而构建。POSTAG
下表列出了这些类。POS
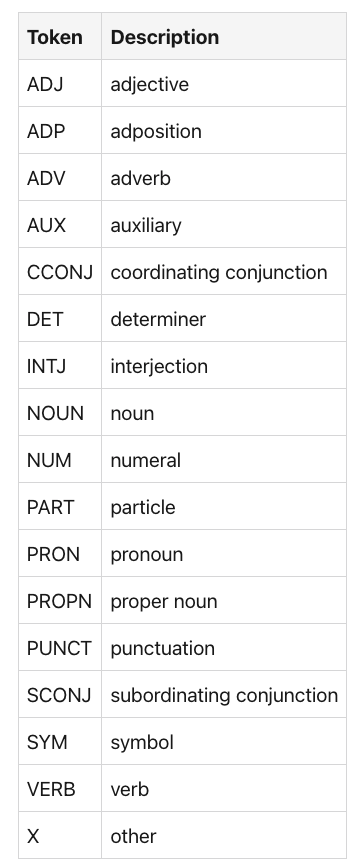
令牌描述 ADJ 形容词 ADP adposition ADV 副词 AUX 辅助 CCONJ 协调结合 DET 确定器 INTJ 感叹词 名词 名词 NUM 数字 部分 助词 PRON 代词 PROP 专有名词 标点符号 SCONJ 从属连词 符号 动词 动词 X 其他
对于这些类,我在文档中找不到明确的解释。但是,这个 Stackoverflow 线程暗示引用了有关依赖项解析的学术论文中使用的类。TAGTAG
若要查看与令牌关联的 和,请运行以下代码:POSTAG
doc = nlp(paragraph)
for token in doc:
print(f'{token.text:<20}{token.pos_:>5}{token.tag_:>5}')
#Artificial ADJ JJ
#intelligence NOUN NN
#was AUX VBD
#founded VERB VBN
#as ADP IN
#an DET DT
#academic ADJ JJ
#discipline NOUN NN3.5 文本语义
3.5.1 依赖关系解析
依赖项分析检查单词和单词块的上下文关系。此步骤极大地增强了机器从文本中获取的语义信息。
Spacy 既提供文本表示,也提供依赖项的图形表示。
doc = nlp(paragraph)
for token in doc:
print(f'{token.text:<20}{token.dep_:<15}{token.head.text:<20}')
# Artificial amod intelligence
# intelligence nsubjpass founded
# was auxpass founded
# founded ROOT founded
# as prep founded
# an det discipline
# academic amod discipline
# discipline pobj as
# in prep founded若要以图形方式呈现这些关系,请运行以下命令。
from spacy import displacy
nlp = spacy.load("en_core_web_lg")
displacy.serve(doc, style="dep", options={"fine_grained": True, "compact": True})它将输出一个结构,如下所示:

请注意,此处理步骤的功能仅限于语言模型原始训练语料库。Spacy 提供了两种方法来增强解析。首先,模型可以从头开始训练。其次,最近发布的 Spacy 提供了转换器模型,这些模型也可以进行微调以与更特定于领域的语料库一起使用。
3.6 命名实体识别
文本中的实体是指人员、组织或对象,Spacy 可以针对已处理的文档进行检测。
识别的实体是已分析文档的一部分,可由属性访问。ents
doc = nlp(paragraph)
for token in doc.ents:
print(f'{token.text:<40}{token.label_:<15}')
# 1956 DATE
# the years DATE
# AI ORG
# the first decades of the 21st century DATE或者,它们可以可视化。

与依赖项解析类似,此步骤的结果非常依赖于其训练数据。例如,如果用于书籍文本,它可能无法识别其字符的名称。为了帮助处理这种情况,可以创建自定义知识库对象,该对象将用于在文本处理期间标识命名实体的可能候选项。
3.7 文档语义
3.7.1 分类
Spacy本身不包括分类或分类算法,但其他开源项目扩展了Spacy以执行机器学习任务。
仅举一个例子:Berttopic 扩展是一个开箱即用的文档分类项目,甚至提供可视化表示。
此项目通过运行 来安装。将此项目应用于一组 200 篇文章会得到以下结果:pip install "bertopic[spacy]"
import numpy as np
import pandas as pd
from bertopic import BERTopic
X = pd.read_pickle('ml29_01.pkl')
docs = X['preprocessed'].values
topic_model = BERTopic()
topics, probs = topic_model.fit_transform(docs)
print(topic_model.get_topic_info())
# Topic Count Name
# -1 30 -1_artificial_intelligence_machine
# 1 22 49_space_lunar_mission3.8 附加功能
3.8.1 语料库管理
Spacy 定义了一个对象,但它用于读取 JSON 或纯文本文件以训练自定义 Spacy 语言模型。Corpus
我可以在文档中找到的所有已处理文本的唯一属性是,一个查找表,用于查找处理文本中遇到的所有单词。vocab
3.8.2 文本矢量
对于类别或的所有内置模型,都包括词向量。在 Spacy 中,单个标记、跨度(用户定义的文档切片)或完整文档可以表示为向量。mdlg
下面是一个示例:
nlp = spacy.load("en_core_web_lg")
vectors = [(token.text, token.vector_norm) for token in doc if token.has_vector]
print(vectors)
# [('Artificial', 8.92717), ('intelligence', 6.9436903), ('was', 10.1967945), ('founded', 8.210244), ('as', 7.7554812), ('an', 8.042635), ('academic', 8.340115), ('discipline', 6.620854),
span = doc[0:10]
print(span)
# Artificial intelligence was founded as an academic discipline in 1956
print(span.vector_norm)
# 3.0066288
print(doc.vector_norm)
# 2.037331438809547该文档没有透露正在使用哪种特定的标记化方法。非标准化标记有 300 个维度,这可能暗示正在使用 FastText 标记化方法:
token = doc[0]
print(token.vector.dtype, token.vector.shape)
# float32 (300,)
print((token.text, token.vector))
#'Artificial',
# array([-1.6952 , -1.5868 , 2.6415 , 1.4848 , 2.3921 , -1.8911 ,
# 1.0618 , 1.4815 , -2.4829 , -0.6737 , 4.7181 , 0.92018 ,
# -3.1759 , -1.7126 , 1.8738 , 3.9971 , 4.8884 , 1.2651 ,
# 0.067348, -2.0842 , -0.91348 , 2.5103 , -2.8926 , 0.92028 ,
# 0.24271 , 0.65422 , 0.98157 , -2.7082 , 0.055832, 2.2011 ,
# -1.8091 , 0.10762 , 0.58432 , 0.18175 , 0.8636 , -2.9986 ,
# 4.1576 , 0.69078 , -1.641 , -0.9626 , 2.6582 , 1.2442 ,
# -1.7863 , 2.621 , -5.8022 , 3.4996 , 2.2065 , -0.6505 ,
# 0.87368 , -4.4462 , -0.47228 , 1.7362 , -2.1957 , -1.4855 ,
# -3.2305 , 4.9904 , -0.99718 , 0.52584 , 1.0741 , -0.53208 ,
# 3.2444 , 1.8493 , 0.22784 , 0.67526 , 2.5435 , -0.54488 ,
# -1.3659 , -4.7399 , 1.8076 , -1.4879 , -1.1604 , 0.82441 ,最后,Spacy 提供了一个选项,为管道提供用户定义的词向量。
四、自定义 NLP 管道
管道的参考模型包含在预训练的语言模型中。它们包括以下内容:
- 分词器
- 标记器
- 依赖关系解析器
- 实体识别器
- 词形还原器
需要在特定于项目的配置文件中定义管道步骤。所有这些步骤的完整管道定义如下:
[nlp]
pipeline = ["tok2vec", "tagger", "parser", "ner", "lemmatizer"] 此管道可以扩展。例如,若要添加文本分类步骤,只需在管道声明后追加 ,并提供实现。textcat
可以使用多个管道组件,以及添加自定义组件的选项,这些组件将与 Paccy 实现的文档表示进行交互并丰富文档表示形式。
此外,外部自定义模型或模型组件可以合并到Spacy中,例如交换词向量表示或使用任何基于PyTorch或外部转换器库的基于变压器的模型。
五、模型训练
基于管道对象和广泛的配置文件,可以训练新模型。快速入门指南包含一个 UI 小组件,可在其中以交互方式创建所需的管道步骤和本地文件路径。训练数据需要具有 Python 数据对象的形式,其中包含应训练的所需属性。下面是用于训练命名实体识别的官方文档中的示例。
# Source: Spacy, Training Pipelines & Models, https://spacy.io/usage/training#training-data
nlp = spacy.blank("en")
training_data = [
("Tokyo Tower is 333m tall.", [(0, 11, "BUILDING")]),
]对于训练数据本身,支持多个转换器,例如 JSON、通用依赖项或命名实体识别格式,如 IOB 或 BILUO。
为了便于训练,可以使用语料库对象来迭代 JSON 或纯文本文档。
六、总结
Spacy是一个最先进的NLP库。通过使用其中一个预训练模型,将应用所有基本文本处理任务(标记化、词形还原、词性标记)和文本语义任务(依赖项分析、命名实体识别)。所有模型都是通过管道对象创建的,此对象可用于自定义这些步骤中的任何一个,例如提供自定义分词器或交换词向量组件。此外,还可以使用其他基于转换器的模型,并使用文本分类任务扩展管道。塞巴斯蒂安