2019_ICML_Domain Agnostic Learning with Disentangled Representations
论文地址:https://arxiv.org/pdf/1904.12347.pdf
代码地址:https://github.com/VisionLearningGroup/DAL
1 研究动机与研究思路
研究动机:之前的研究都有一个强假设,目标数据从同一分布均匀采样。本文提出Domain-Agnostic Learning (DAL)问题,即如何把有标注的源域信息迁移到无标注的任意目标域数据上。这个问题存在两个难点:1)目标数据来自混合的目标域,所以目前主流的特征对齐方法不太适用,2)类无关信息会导致负迁移,特别是当目标域高度异构的时候。
研究思路:一种深层对抗解耦自编码器( Deep Adversarial Disentangled Autoencoder,DADA ),能够将特定领域中分离出特定类的特征。
2 主要工作
本文的主要贡献在于:
- 提出了领域不可知学习的新范式;
- 提出了一个端到端的深层对抗解耦自动编码器( DADA ),更好的学习特征解耦表示;
- 提出用类解耦来去除类无关特征,并最小化互信息来增强解耦。
3 DADA
3.1 符号定义
定义领域无关学习任务如下:给定一个具有 n s n_s ns个标注样本的源域 D ^ s = { ( x i s , y i s ) } i = 1 n s widehat{mathcal{D}}_s=left{left(mathbf{x}_i^s, y_i^sright)right}_{i=1}^{n_s} D s={(xis,yis)}i=1ns ,目标是在没有域标注的情况下最小化 N N N个目标域 D ^ t = { D ^ 1 , D ^ 2 , … , D ^ N } widehat{mathcal{D}}_t=left{widehat{mathcal{D}}_1, widehat{mathcal{D}}_2, ldots, widehat{mathcal{D}}_Nright} D t={D 1,D 2,…,D N} 上的风险。我们将有 n t n_t nt个未标注样本的目标域记为 D ^ t = { x j t } j = 1 n t widehat{mathcal{D}}_t=left{mathrm{x}_j^tright}_{j=1}^{n_t} D t={xjt}j=1nt。最小化目标风险 ϵ t ( θ ) = Pr ( x , y ) ∼ D ^ t [ θ ( x ) ≠ y ] epsilon_t(theta)=operatorname{Pr}_{(mathbf{x}, y) sim widehat{mathcal{D}}_t}[theta(mathrm{x}) neq y] ϵt(θ)=Pr(x,y)∼D t[θ(x)=y],其中 θ ( x ) theta(mathrm{x}) θ(x)为分类器。
3.2 DADA总框架
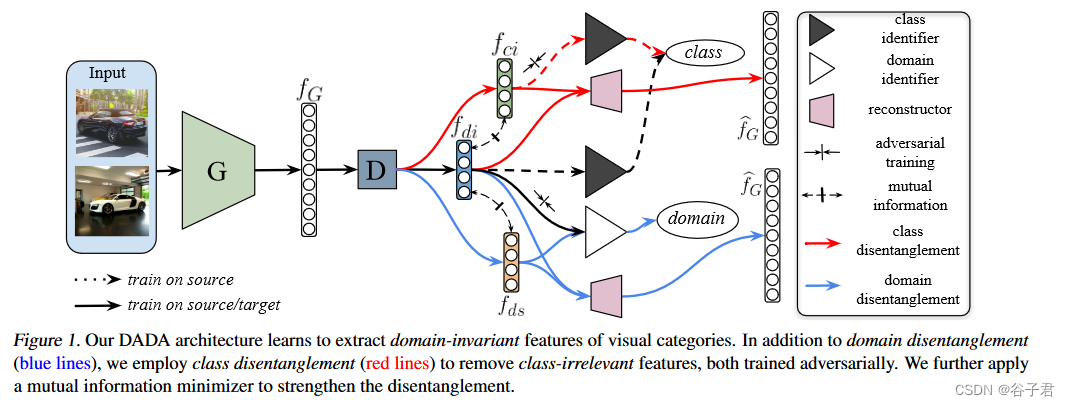
DADA方法学习提取视觉类别的领域不变特征。除了领域解耦(蓝线),还使用类别解耦(红线)来去除类别无关的特征(在有标签的源域上训练一个类标识符,解耦器生成特征来欺骗类标识符),两者都是对抗训练的,进一步应用互信息最小化器来加强解耦。
图1展示了所提出的模型, 特征生成器
G
G
G 将输入图片映射到特征向量
f
G
f_G
fG, 这个
f
G
f_G
fG 是一个高度耦合的特征, 所以后面编码器
D
D
D 的目的是将这个特征解耦为域不变特征
f
d
i
f_{d i}
fdi, 域特定特征
f
d
s
f_{d s}
fds 和类无关特征
f
c
i
f_{c i}
fci 。特征重建器
R
R
R 的目的是接受
(
f
d
i
,
f
c
i
)
left(f_{d i}, f_{c i}right)
(fdi,fci) 或 (
f
d
i
,
f
d
s
f_{d i}, f_{d s}
fdi,fds ) 作为输入, 然后重建出
f
G
f_G
fG 。
D
D
D 和
R
R
R 使用变分自编码器(VAE)中的编码器与解码器实现。为了增强解耦, 在
(
f
d
i
,
f
c
i
)
left(f_{d i}, f_{c i}right)
(fdi,fci) 以及 (
f
d
i
f_{d i}
fdi,
f
d
s
f_{d s}
fds ) 上进行互信息最小化约束。在域判别器支路(白三角) 通讨对抗训练学习出域不变特征
f
d
i
f_{d i}
fdi 。类判别器
C
C
C (黒三 角) 通过在有标注的源域数据上预测类分布
f
C
f_C
fC 训练得到, 类无关特征
f
c
i
f_{c i}
fci 是通过结合
C
C
C 以对抗的方式提取到的。
3.3 具体实现
3.3.1 变分自编码器
VAEs ( Kingma &韦林, 2013)是一类同时训练概率编码器和解码器的深度生成模型。编码器会生成符合高斯分布的隐藏向量。通过使用VAE来获得每个部分的解耦表示,损失函数设计如下:
L
vae
=
∥
f
^
G
−
f
G
∥
F
2
+
K
L
(
q
(
z
∣
f
G
)
∥
p
(
z
)
)
mathcal{L}_{text {vae }}=left|widehat{f}_G-f_Gright|_F^2+K Lleft(qleft(z mid f_Gright) | p(z)right)
Lvae =
f
G−fG
F2+KL(q(z∣fG)∥p(z))
这个式子前一项的目的是重建 G G G提取的原始特征,后面一项计算Kullback - Leibler散度,惩罚隐藏特征分布与先验分布 p ( z c ) pleft(z_cright) p(zc)(as z ∼ z sim z∼ N ( 0 , I ) mathcal{N}(0, I) N(0,I) )的偏差。这个约束仅仅是将隐藏特征映射到一个标准分布(将潜在特征对齐到正态分布),并没有保证特征解耦。
3.3.2 类别解耦
通过对抗的方式实现类别信息解耦来移除一些类别无关的特征,比如背景等。首先通过源域数据进行有监督训练得到class identifier
C
C
C((图中黑色的三角)):
首先,在交叉熵损失的监督下,训练解耦器
D
D
D和
K
K
K - way class identifier
C
C
C来正确预测标签:
L
c
e
=
−
E
(
x
s
,
y
s
)
∼
D
^
s
∑
k
=
1
K
1
[
k
=
y
s
]
log
(
C
(
f
D
)
)
mathcal{L}_{c e}=-mathbb{E}_{left(x_s, y_sright) sim widehat{mathcal{D}}_s} sum_{k=1}^K mathbb{1}left[k=y_sright] log left(Cleft(f_Dright)right)
Lce=−E(xs,ys)∼D
sk=1∑K1[k=ys]log(C(fD))
其中
f
D
∈
{
f
d
i
,
f
c
i
}
f_D inleft{f_{d i}, f_{c i}right}
fD∈{fdi,fci}.固定住类判别器
C
C
C来训练解耦器
D
D
D来生成类无关特征
f
c
i
f_{c i}
fci来欺骗
C
C
C。这可以通过最小化预测类分布的负交叉熵来实现:
L
ent
=
−
1
n
s
∑
j
=
1
n
s
log
C
(
f
c
i
j
)
−
1
n
t
∑
j
=
1
n
t
log
C
(
f
c
i
j
)
mathcal{L}_{text {ent }}=-frac{1}{n_s} sum_{j=1}^{n_s} log Cleft(f_{c i}^jright)-frac{1}{n_t} sum_{j=1}^{n_t} log Cleft(f_{c i}^jright)
Lent =−ns1j=1∑nslogC(fcij)−nt1j=1∑ntlogC(fcij)
第一项与第二项分别指的是在源域上和目标域上的交叉熵最小。上述对抗训练过程迫使相应的解缠器提取与类别无关的特征。
3.3.3 域解耦
为了实现源域与目标对齐,将学习到的特征分解为领域特定的和领域不变的特征,从而在领域不变的潜在空间中将源和目标领域对齐。这通过在得到的隐空间里进行对抗性域判别得到。具体来说,我们利用一个域标识符
D
I
D I
DI,它以解缠后的特征(
(
f
d
i
left(f_{d i}right.
(fdi or
f
d
s
)
left.f_{d s}right)
fds))作为输入,输出域标签
l
f
l_f
lf(源或目标)。领域标识符的目标函数为:
L
D
I
=
−
E
[
l
f
log
P
(
l
f
)
]
+
E
(
1
−
l
f
)
[
log
P
(
1
−
l
f
)
]
mathcal{L}_{D I}=-mathbb{E}left[l_f log Pleft(l_fright)right]+mathbb{E}left(1-l_fright)left[log Pleft(1-l_fright)right]
LDI=−E[lflogP(lf)]+E(1−lf)[logP(1−lf)]
之后就训练解耦器
D
D
D来欺骗域判别器
D
I
D I
DI来提取域不变特征。
3.3.4 互信息最小化
为了更好地分离特征,最小化领域不变和特定领域特征(
(
f
d
i
,
f
d
s
)
left(f_{d i}, f_{d s}right)
(fdi,fds)),以及领域不变和类别无关特征(
(
f
d
i
left(f_{d i}right.
(fdi,
f
c
i
)
left.f_{c i}right)
fci) )之间的互信息:
I
(
D
x
;
D
f
d
i
)
=
∫
X
×
Z
log
d
P
X
Z
d
P
X
⊗
P
Z
d
P
X
Z
,
Ileft(mathcal{D}_x ; mathcal{D}_{f_{d i}}right)=int_{mathbb{X} times mathcal{Z}} log frac{d mathbb{P}_{X Z}}{d mathbb{P}_X otimes mathbb{P}_Z} d mathbb{P}_{X Z},
I(Dx;Dfdi)=∫X×ZlogdPX⊗PZdPXZdPXZ,
其中,
x
∈
{
f
d
s
,
f
c
i
}
,
P
X
Z
x inleft{f_{d s}, f_{c i}right}, mathbb{P}_{X Z}
x∈{fds,fci},PXZ的联合概率分布,
(
D
x
,
D
f
d
i
)
left(mathcal{D}_x, mathcal{D}_{f_{d i}}right)
(Dx,Dfdi),
P
X
=
∫
Z
d
P
X
Z
mathbb{P}_X=int_{mathcal{Z}} d mathbb{P}_{X Z}
PX=∫ZdPXZ and
P
Z
=
mathbb{P}_Z=
PZ=
∫
X
d
P
X
Z
int_{mathcal{X}} d mathbb{P}_{X Z}
∫XdPXZ 为边缘分布。尽管互信息是跨领域的关键度量,但它只适用于离散变量或有限的概率分布未知的问题。计算复杂度为
O
(
n
2
)
Oleft(n^2right)
O(n2),不适合深层的CNN。因此这篇文章采用的是互信息神经估计器(MINE):
I
(
X
;
Z
^
)
n
=
sup
θ
∈
Θ
E
P
X
Z
(
n
)
[
T
θ
]
−
log
(
E
P
X
(
n
)
⊗
P
^
Z
(
n
)
[
e
T
θ
]
)
widehat{I(X ; Z})_n=sup _{theta in Theta} mathbb{E}_{mathbb{P}_{X Z}^{(n)}}left[T_thetaright]-log left(mathbb{E}_{mathbb{P}_X^{(n)} otimes widehat{mathbb{P}}_Z^{(n)}}left[e^{T_theta}right]right)
I(X;Z
)n=θ∈ΘsupEPXZ(n)[Tθ]−log(EPX(n)⊗P
Z(n)[eTθ])
其中,
(
x
,
z
)
(x, z)
(x,z)从联合分布中采样,
z
′
z^{prime}
z′ 从边缘分布中采样。使用神经网络来执行方程7中定义的蒙特卡罗积分。
3.3.5 Ring-style Normalization
通过减去批均值除以批标准差来减少内部协变量偏移。尽管在领域自适应方面取得了很好的效果,但仅靠批量归一化并不足以保证嵌入的特征在异构领域场景中得到很好的归一化。目标数据从多个域中采样,其嵌入特征在隐空间中不规则分散。Zheng等人(2018)提出了ring-style norm constraint用于保证多类别的角分类边界(angular classification margins)间的均衡性,其目的如下:
L
ring
=
1
2
n
∑
i
=
1
n
(
∥
T
(
x
i
)
∥
2
−
R
)
2
mathcal{L}_{text {ring }}=frac{1}{2 n} sum_{i=1}^nleft(left|Tleft(x_iright)right|_2-Rright)^2
Lring =2n1i=1∑n(∥T(xi)∥2−R)2
式中:R为学习到的范数值。然而,Ring-style并不鲁棒,如果学习到的R较小,可能会导致模式崩溃。取而代之的是,Geman-McClure模型,最小化如下损失函数:
L
ring
G
M
=
∑
i
=
1
n
(
∥
T
(
x
i
)
∥
2
−
R
)
2
2
n
β
+
∑
i
=
1
n
(
∥
T
(
x
i
)
∥
2
−
R
)
2
mathcal{L}_{text {ring }}^{G M}=frac{sum_{i=1}^nleft(left|Tleft(x_iright)right|_2-Rright)^2}{2 n beta+sum_{i=1}^nleft(left|Tleft(x_iright)right|_2-Rright)^2}
Lring GM=2nβ+∑i=1n(∥T(xi)∥2−R)2∑i=1n(∥T(xi)∥2−R)2
其中
β
beta
β是Geman -麦克卢尔模型的尺度因子。

以端到端的方式进行训练优化模型。使用Stochasitc Gradient Descent ( Kiefer等, 1952)或Adam ( Kingma & Ba , 2014)优化器迭代训练类和域解耦部分、MINE和重建部分。使用流行的神经网络( e.g. Le Net、Alex Net或Res Net)作为特征生成器G。详细的训练过程在算法1中给出。