不会真有人觉得聊天机器人难吧——从计算图到自动求导(上)
引言
借用修仙小说体写的标题,主要目的就是吸引你点进来?,客官来都来了,看完再走呗~
其实实现一个智能的聊天机器人?还是有一定难度的。博主就和大家一起尽可能实现一个智能的聊天机器人。
计划一周?更新一次,如果觉得更新慢的话,就在留言里催更吧,很有可能会响应你们的催更哦。本系列文章?会基于自己写的类Pytorch工具实现一个Seq2Seq 带Attention机制的聊天机器人,在本系列文章中,大家会了解到实现聊天机器人的所有知识,欢迎关注哦。
本文介绍自动求导的基础知识——计算图,并且基于计算图来开始实现我们自己的自动求导工具:metagrad。分为三部分,这是第一部分。
计算图
我们知道,反向传播是模型训练的途径。而反向传播是基于求导的,有没有想过像Keras和PyTorch这种工具是如何做到自动求导的。答案就是计算图,只要掌握了计算图的知识,我们就能自己开发一个自动求导工具。
计算图是一种描述函数的工具,可以可视化为有向图结构。其中节点为Tensor(向量/张量),有向边为操作。
在深度学习中比较常见的例子是类似
y
=
f
(
g
(
h
(
x
)
)
)
u
=
h
(
x
)
v
=
g
(
u
)
y
=
f
(
v
)
y = f (g(h(x))) \ u = h(x) quad v= g(u) quad y=f(v)
y=f(g(h(x)))u=h(x)v=g(u)y=f(v)

x可以看成是输入,y可以看成是输出,中间经过了3次变换。
有时我们的函数有多个参数(比如乘法就有两个参数),假设我们要计算 e = ( a + b ) ∗ ( b + 1 ) e = (a+b) * (b+1) e=(a+b)∗(b+1),它的计算图如下:
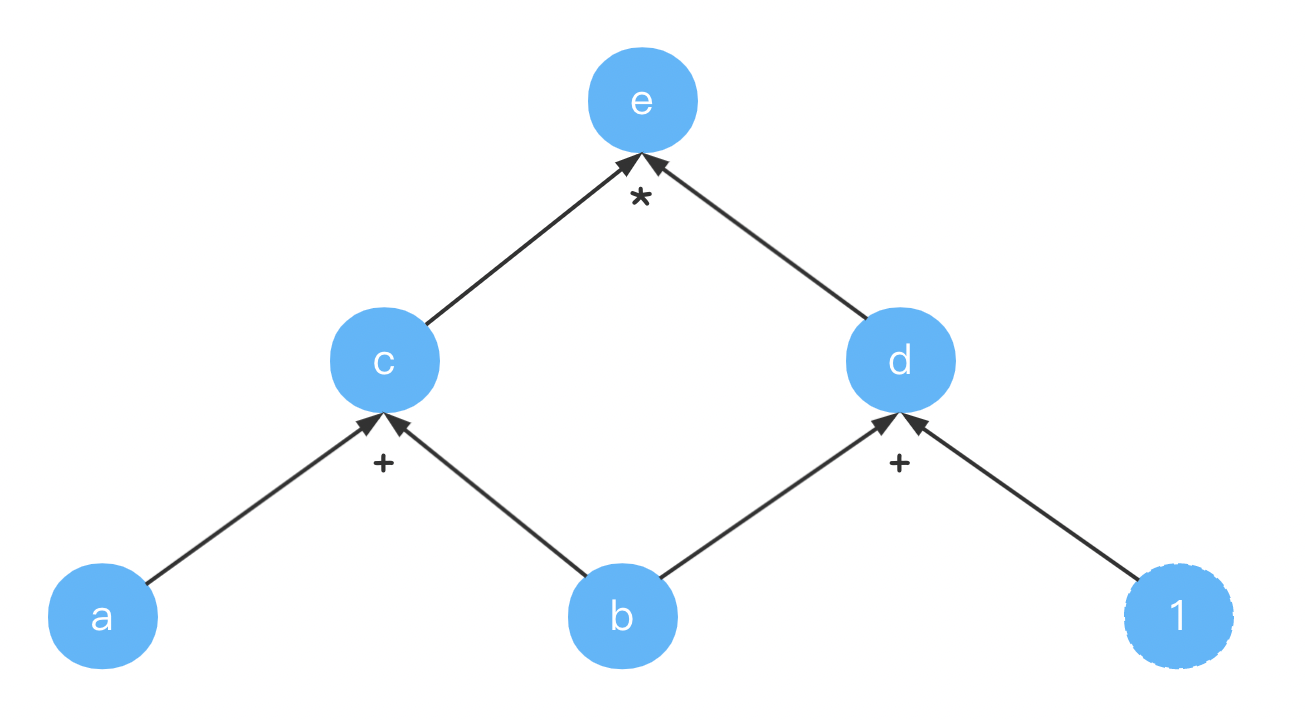
这里令 c = a + b ; d = b + 1 c = a+ b; quad d = b + 1 c=a+b;d=b+1,为了完整性,也画出了常量 1 1 1。
有了这个计算图,我们就就可以很容易的计算出 e e e的值。比如令 a = 2 , b = 1 a=2,b=1 a=2,b=1
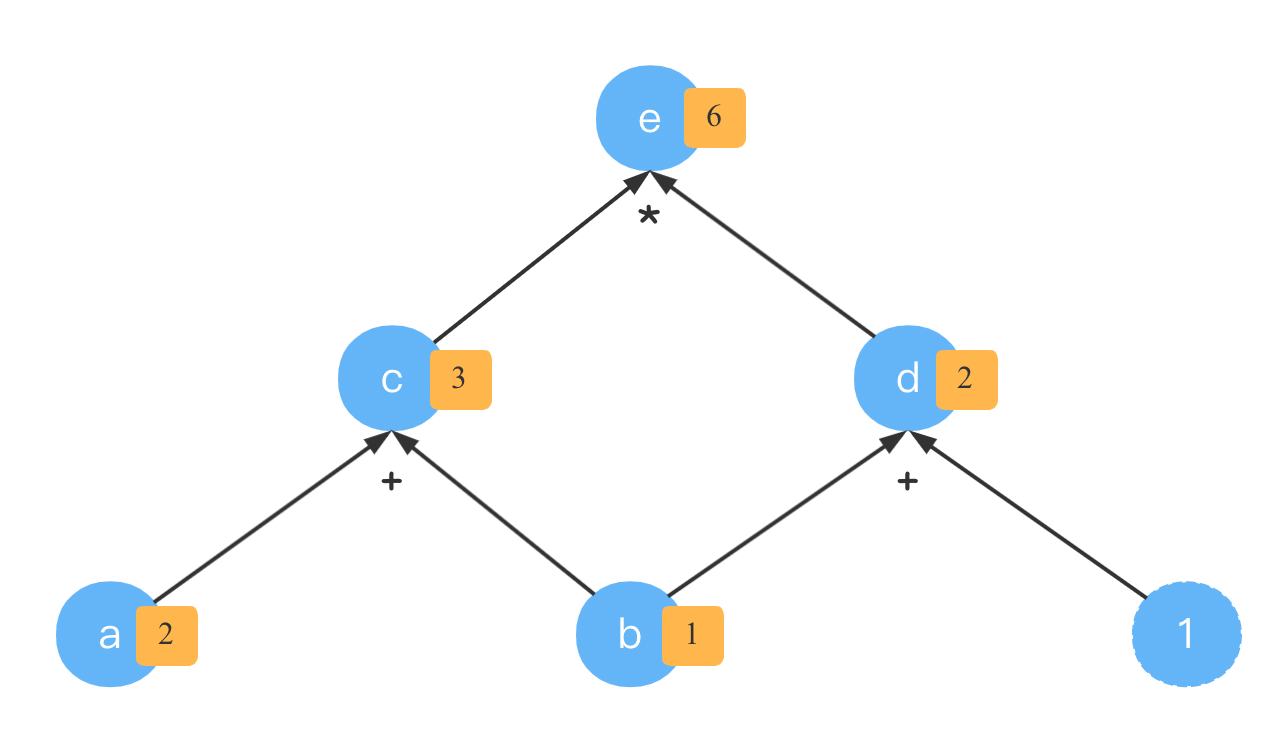
当然,我们这么辛苦的画出这个图,主要不是为了沿着箭头方向进行计算的。而是为了求导,也就是计算梯度。
计算图上的梯度
回顾一下链式法则


我们重点来看下多路径的链式法则,即上面说的全导数。
我们要计算 e = ( a + b ) ∗ ( b + 1 ) e = (a+b) * (b+1) e=(a+b)∗(b+1)中 ∂ e / ∂ b partial e/ partial b ∂e/∂b。
c = a + b ; d = b + 1 c = a+ b; quad d = b + 1 c=a+b;d=b+1。
类似上图中的
t
t
t,
b
b
b也影响了两个因子。因此有
∂
e
∂
b
=
∂
e
∂
c
⋅
∂
c
∂
b
+
∂
e
∂
d
⋅
∂
d
∂
b
frac{partial e}{partial b} = frac{partial e}{partial c} cdot frac{partial c}{partial b} + frac{partial e}{partial d} cdot frac{partial d}{partial b}
∂b∂e=∂c∂e⋅∂b∂c+∂d∂e⋅∂b∂d
要计算偏导数,我们先把每个箭头的偏导数计算出来。
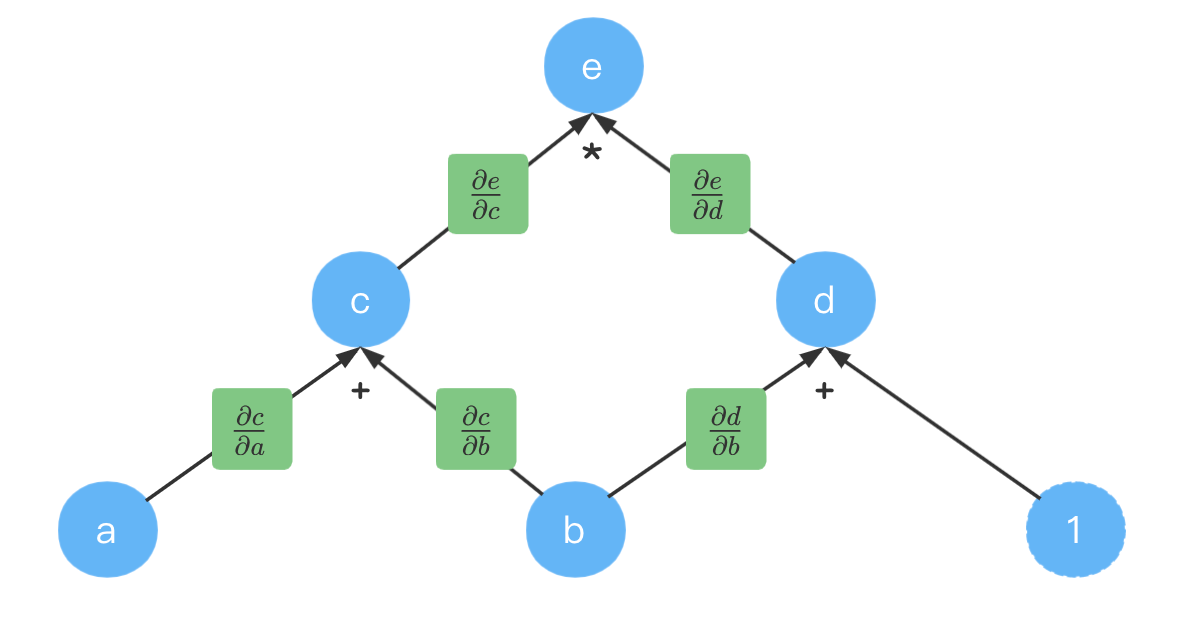
我们先填入计算出来的式子:
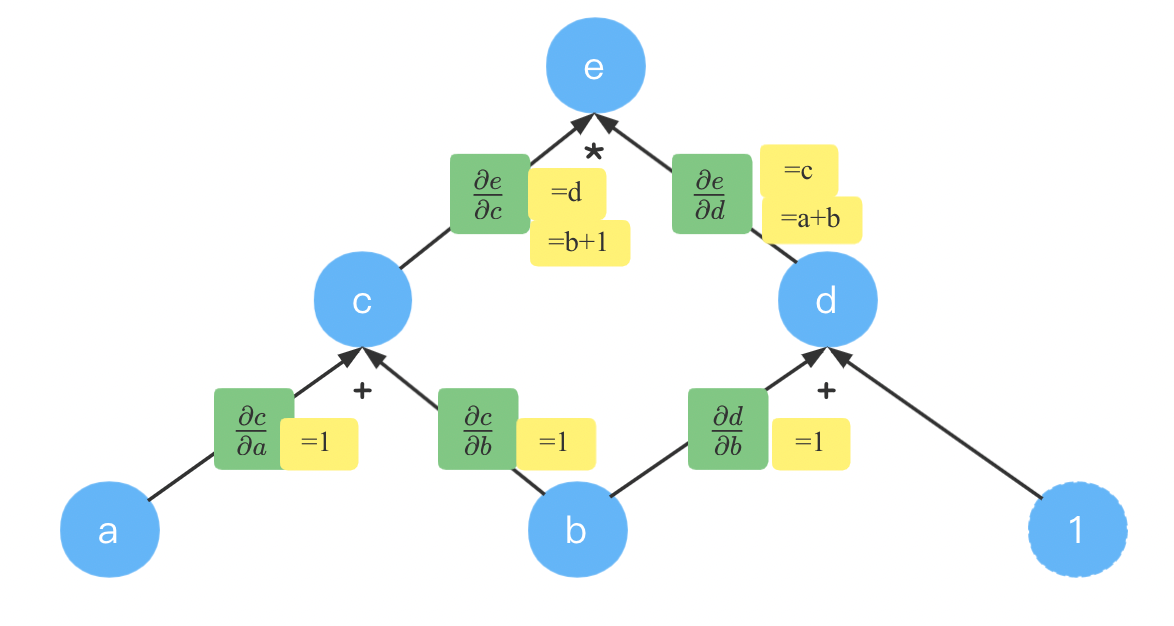
根据 e = c ∗ d c = a + b d = b + 1 e = c * d quad c = a+ b quad d = b+ 1 e=c∗dc=a+bd=b+1以及求导公式不难得到上面的结果。
此时,要计算 ∂ e / ∂ b partial e/ partial b ∂e/∂b,只需要找出所有从 b b b到 e e e到路径,然后把相同路径上的值相乘,不同路径上的值相加(连线相乘,分线相加)。
就可以得到: ∂ e / ∂ b = 1 ∗ ( b + 1 ) + 1 ∗ ( a + b ) partial e/ partial b = 1*(b+1) + 1*(a+b) ∂e/∂b=1∗(b+1)+1∗(a+b)
此时,代入 a = 2 , b = 1 a=2,b=1 a=2,b=1。
先计算出 b + 1 = 2 b+1=2 b+1=2,再计算 a + b = 3 a+b=3 a+b=3,所以 ∂ e / ∂ b = 1 ∗ 2 + 1 ∗ 3 = 5 partial e/ partial b = 1*2 + 1 *3=5 ∂e/∂b=1∗2+1∗3=5
反向模式
如果要同时计算 e e e对 a a a和 b b b的偏导数,我们需要反向模式(Reverse mode)来同时计算它们。
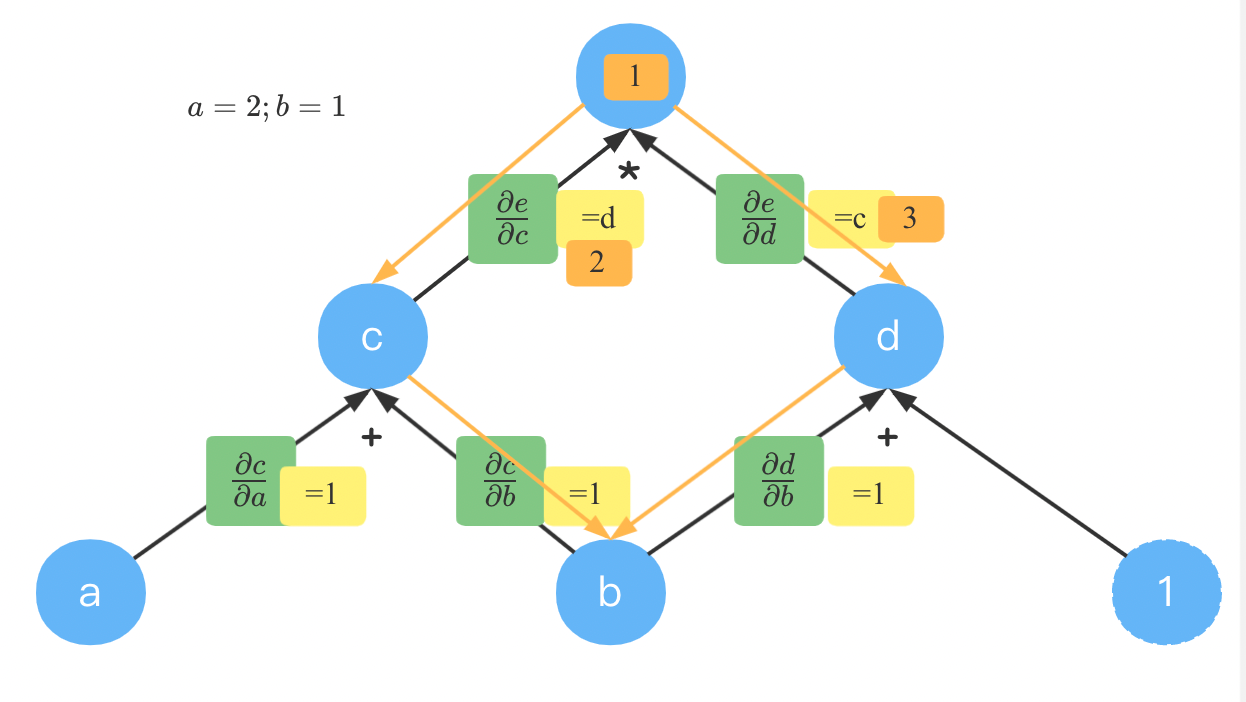
反向就是从顶点开始,这里从 e e e开始,也从梯度等于 1 1 1开始。
从顶点到 b b b,通过有两条路径,如山古同橙色箭头所示。达到 c c c时的梯度为 1 ∗ 2 = 2 1 * 2 =2 1∗2=2;到达 d d d时的梯度为 1 ∗ 3 = 3 1 * 3=3 1∗3=3。
c c c和 d d d到 b b b的梯度都是 1 1 1。根据相同路径相乘,不同路径相加。到 b b b到梯度为 2 + 3 = 5 2+3=5 2+3=5。
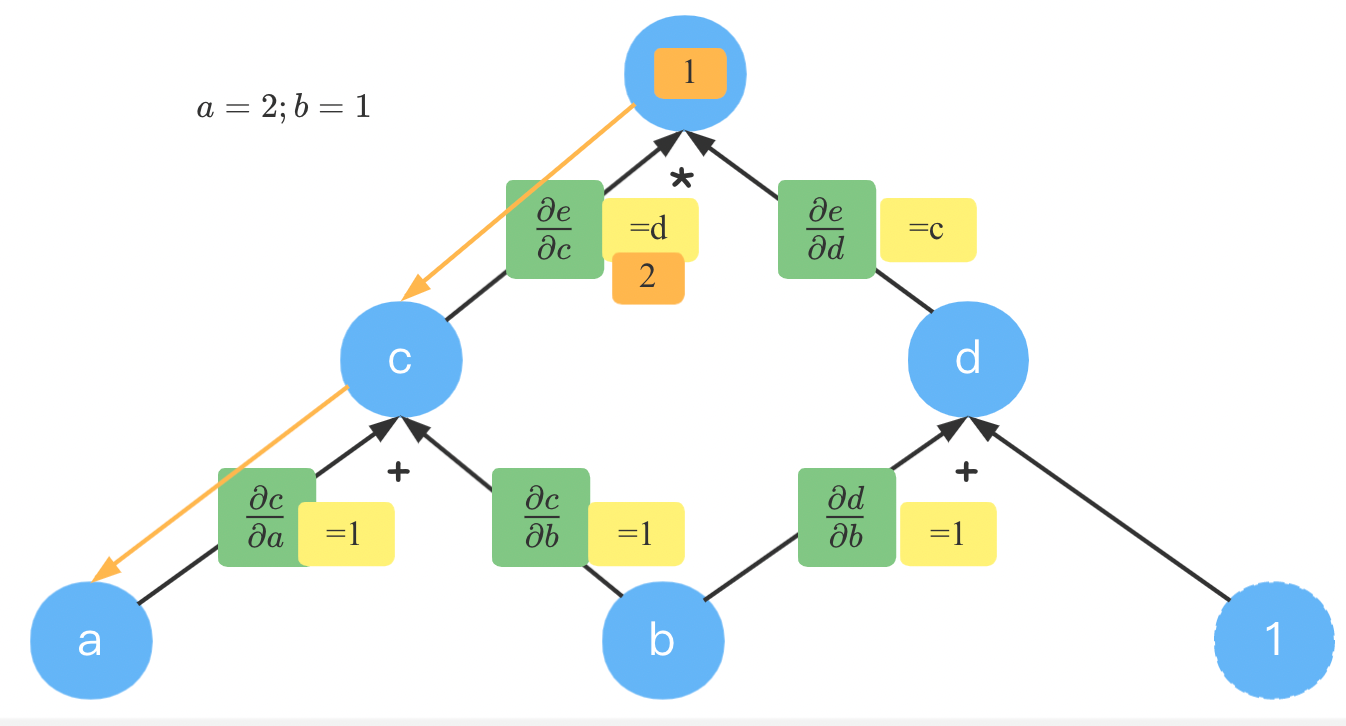
此时,计算 e e e到 a a a的就简单了,我们已经知道了 e e e到 c c c到梯度为 2 2 2,由于 e e e到 a a a只有一条路径,因此直接相乘得 ∂ e / ∂ a = 2 ∗ 1 = 2 partial e / partial a =2 * 1=2 ∂e/∂a=2∗1=2。
如果你的函数只有一个输出,由需要同时计算大量的不同值的偏导数时,用反向模式就比较快。
而这恰恰非常适合于我们计算损失函数的梯度,因为损失函数的输出就是一个标量。
总结
我们已经了解了计算图到基本知识,下篇文章我们来看一下常见运算的计算图。