Sqoop
前言
最近专业 NoSQL 的课程作业涉及到关系型数据库数据导入到非关系型数据库,其实我们也可以通过Java代码,通过JDBC将关系型数据库中的数据读取出来,然后写出到我们的非关系型数据库中(比如HBase)中。
原本 Sqoop 的学习计划还在后面阶段,现在既然用上了,今天就争取一下午学完,毕竟学校是不会教的。能学会并马上用到,这样的学习效果往往最好。Sqoop 只是一个工具,重点是学会使用。
Sqoop 介绍
Sqoop 的全称就是 SQL To Hadoop ,它可以把关系型数据库(MySQL、Orcale...)中的数据导入到 Hadoop 的 HDFS 中,也可以将 HDFS 中的数据导入到关系型数据库中。
Sqoop 原理
将导入或导出命令翻译成 MapReduce 程序来实现,主要是对 InputFormat 和 OutputFormat 进行定制。
Sqoop 导入数据
在Sqoop中,“导入”概念指:从非大数据集群(RDBMS)向大数据集群(HDFS,Hive,HBase)中传输数据,叫做:导入,即使用import关键字。
1、RDBMS 到 HDFS
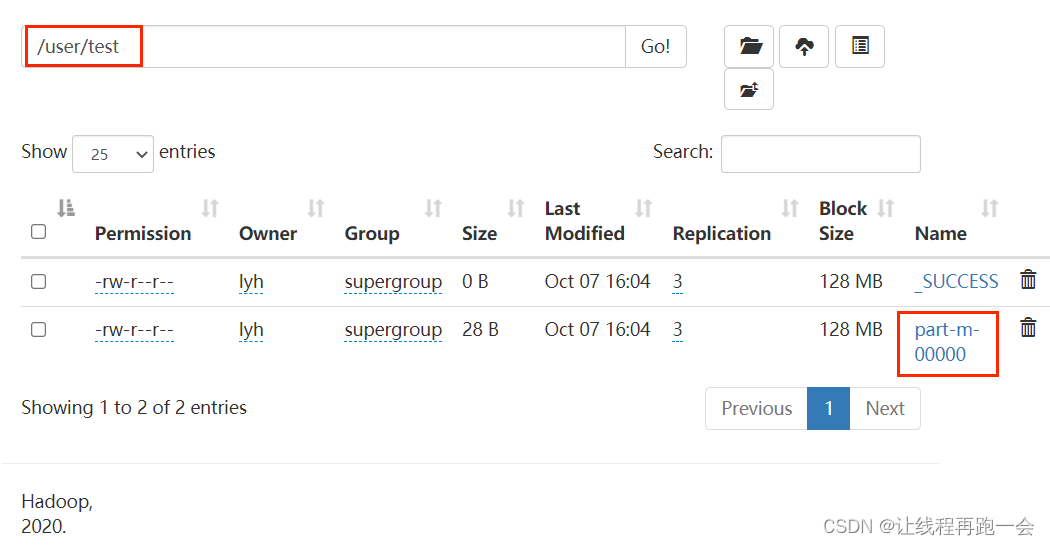
1.1、全部导入
其中的斜杠的作用是 因为 linux 下回车命令就会执行,用斜杠可以防止命令直接执行。
bin/sqoop import
--connect jdbc:mysql://hadoop102:3306/test
--username root
--password 123456
--table staff
--target-dir /user/test
--delete-target-dir
--num-mappers 1
--fields-terminated-by "t"参数解释:
- target-dir:目标目录(导入到 HDFS 后的存储目录)
- delete-target-dir:如果目标目录已存在,直接删除
- num-mappers 1:开启一个 MapTask
- fields-terminated-by "t":以制表符分割开来,
运行结果:
1.2、查询导入
bin/sqoop import
--connect jdbc:mysql://hadoop102:3306/test
--username root
--password 123456
--target-dir /user/test
--delete-target-dir
--num-mappers 1
--fields-terminated-by "t"
--query 'select name,sex from staff where id <=1 and $CONDITIONS;'
注意:
- 如果你要通过查询结果来导入,那 SQL 语句后必须加 $CONDITIONS ,这个参数可以保证最终导入数据的顺序和原本的数据顺序一致。
- 如果 SQL 语句是双引号,那么必须在 $CONDITIONS 之前加反斜杠代表转义。
比如:
--query "select name,sex from staff where name = 'mike' and $CONDITIONS;"1.3、导入指定列
bin/sqoop import
--connect jdbc:mysql://hadoop102:3306/test
--username root
--password 123456
--table staff
--columns id,sex
--target-dir /user/test
--delete-target-dir
--num-mappers 1
--fields-terminated-by "t"
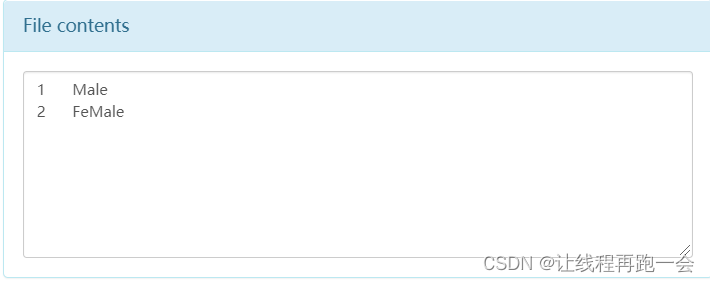
运行结果:
文件中只有 id 和 sex 字段,没有 name。
1.4、使用sqoop关键字筛选查询导入数据
bin/sqoop import
--connect jdbc:mysql://hadoop102:3306/test
--username root
--password 123456
--target-dir /user/test
--delete-target-dir
--num-mappers 1
--fields-terminated-by "t"
--table staff
--where "id=1"
注意:
- where 可以搭配 columns 使用
2、RDBMS 导入到 Hive
先会将 MySQL 的数据导入到 HDFS 的 /user/lyh/staff/ 目录下,再把数据迁移到 Hive(/user/hive/warehouse/staff_hive/)目录下,迁移后 /user/lyh/staff/ 下的数据被删除。
bin/sqoop import
--connect jdbc:mysql://hadoop102:3306/test
--username root
--password 123456
--table staff
--num-mappers 1
--hive-import
--fields-terminated-by "t"
--hive-overwrite
--hive-table staff_hive
参数解释:
- hive-import:导入到 Hive
- hive-overwrite:覆盖的方式
- hive-table:导入到 hive 哪张表
3、RDBMS 导入到 Hbase
直接通过 MapReduce 写入到 HBase 的表中,不需要向写入 Hive 一样需要中间结果写入到 /user/用户名/表名/ 下。
bin/sqoop import
--connect jdbc:mysql://hadoop102:3306/test
--username root
--password 123456
--table staff
--columns "id,name,sex"
--column-family "info"
--hbase-create-table
--hbase-row-key "id"
--hbase-table "hbase_staff"
--num-mappers 1
--split-by id
参数说明:
- hbase-create-table:如果创建表格
- hbase-row-key:行键
- hbase-table:迁移过来后的表名
- column-family:列族名
- split-by:当使用Sqoop将数据从关系型数据库导入HBase时,可以使用--split-by参数来提高导入过程的效率。Sqoop会根据指定的列将数据分割成多个部分,并并行处理这些部分,从而加速数据导入的速度。
注意:sqoop1.4.6只支持对 HBase1.0.1之前的版本的自动创建HBase表的功能,不能帮我们在 HBase 中创建表,需要我们自己手动创建一下。
create 'hbase_staff'
scan 'hbase_staff'如果遇到缺少 NoSuchMethodError: org.apache.hadoop.hbase.client.HBaseAdmin.<init>... 这种报错,建议下载一个低版本的 HBase ,把里面 lib 目录下的所有 jar 包都复制到 sqoop 的 lib 目录下,如果遇到重名的建议不要替换。
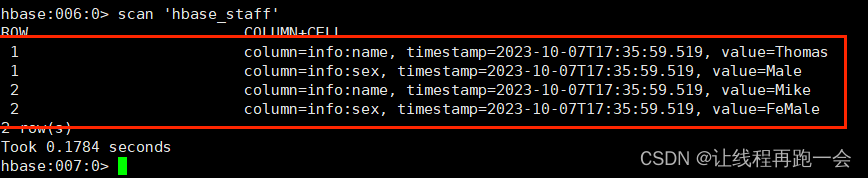
运行结果:
Sqoop 导出数据
在Sqoop中,“导出”概念指:从大数据集群(HDFS,HIVE,HBASE)向非大数据集群(RDBMS)中传输数据,叫做:导出,即使用export关键字。
1、Hive/HDFS 到 RDBMS
bin/sqoop export
--connect jdbc:mysql://hadoop102:3306/test
--username root
--password 123456
--table staff
--num-mappers 1
--export-dir /user/hive/warehouse/staff_hive
--input-fields-terminated-by "t"
参数说明:
- export-dir:要导出的数据所在目录。
注意:如果不加切割符号(input-fields-terminated-by),整个数据将会被当做一个字符串存到 RDBMS 表中的第一个字段。
清空 MySQL 表数据,防止主键冲突
truncate table staff;执行 sqoop 命令,运行结果: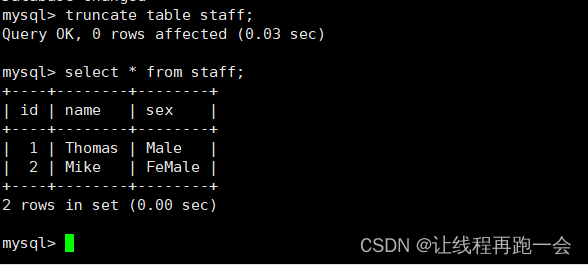
Sqoop 脚本打包
使用opt格式的文件打包sqoop命令,然后执行。写入到脚本后,我们把它交给任务调度框架 Oozie、Azkaban等这些工具来替我们定时执行。
1、创建一个 opt 文件
vim sqp.opt
export
--connect
jdbc:mysql://hadoop102:3306/test
--username
root
--password
123456
--table
staff
--num-mappers
1
--export-dir
/user/hive/warehouse/staff_hive
--input-fields-terminated-by
"t"
2、执行脚本
我们一般把下面的命令放到一个脚本中定时去执行。
bin/sqoop --options-file job/sqp.opt3、测试
清空 MySQL 表格:
truncate table staff;运行结果: