Hive【Hive(六)窗口函数】
窗口函数(window functions)
概述
定义
窗口函数能够为每行数据划分 一个窗口,然后对窗口范围内的数据进行计算,最后将计算结果返回给该行数据。
语法
窗口函数的语法主要包括 窗口 和 函数 两个部分。其中窗口用于定义计算范围,函数用于定义计算逻辑。
select order_id,
order_date,
amount,
函数(amount) over (窗口范围) 别名
from order_info;函数
绝大多数的聚合函数都可以配合窗口函数使用,例如 max、min、sum、count、avg、以及前面学到的 collect_list、collect_set 等。
窗口
窗口范围的定义分为两种,一种是基于行的,一种是基于值的。
基于行
sum(amount) over(order by 排序字段 rows between 起点 and 终点) 别名如果起点是下面两种:
- unbounded preceding 第一行
- [num] preceding 当前行的前 num 行
则终点可以是:
- [num] preceding 当前行的前 num 行
- current row 当前行
- [num] following 当前行的后 num 行
- unbounded following 最后一行
如果起点是:
- current row
那么终点可以是:
- current row 当前行
- [num] following 当前行的后 num 行
- unbounded following 最后一行
如果起点是:
- [num] following
则终点可以是:
- [num] following 当前行的后 num 行
- unbounded following 最后一行
注意:
真正进行窗口函数计算的时候,必须选定一个排序的字段(order by),因为每个窗口函数的作用范围会由于 MapReduce 切片、Shuffle 这些因素而不确定(上一行和下一行可能在不同的切片中)。
案例
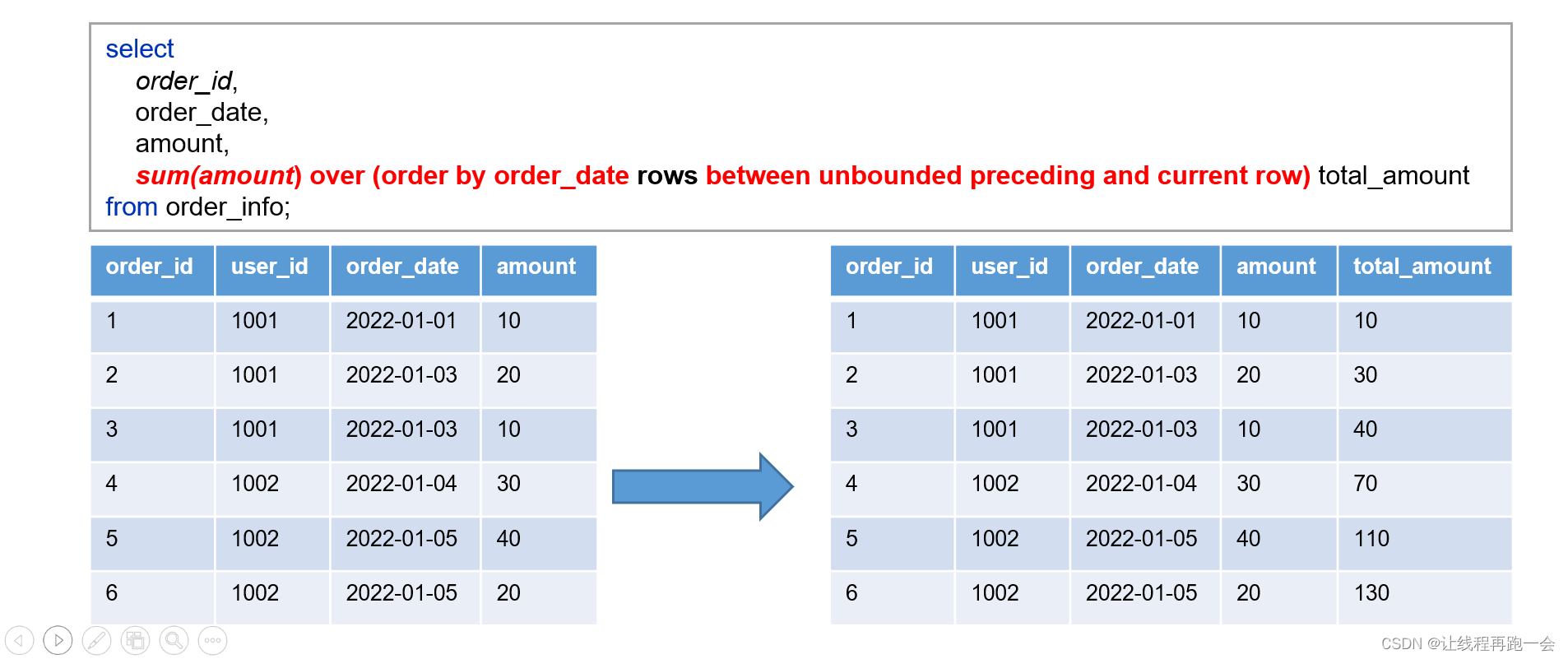
实际意义:截止当前订单的销售总额。
基于值
sum(amount) over (order by 划分窗口范围的字段 range between 起点 and 终点) 别名除了 over 关键字换成了 range ,别的没有变化。
注意:这里的 order by 并不是指的排序字段,基于值的窗口函数并不会排序,这里的 order by 指的是基于哪个字段在值进行窗口范围的划分。 order by 的字段可以是数值型(比如计算指定窗口范围值 num 的就必须是数值型)也可以是别的类型(这时 order by 的字段不可以通过 num 指定窗口范围 )。
同样,基于列的窗口函数中,[num] preceding 和 [num] following 中的 num 指的是当前值 -num 和 +num。
案例
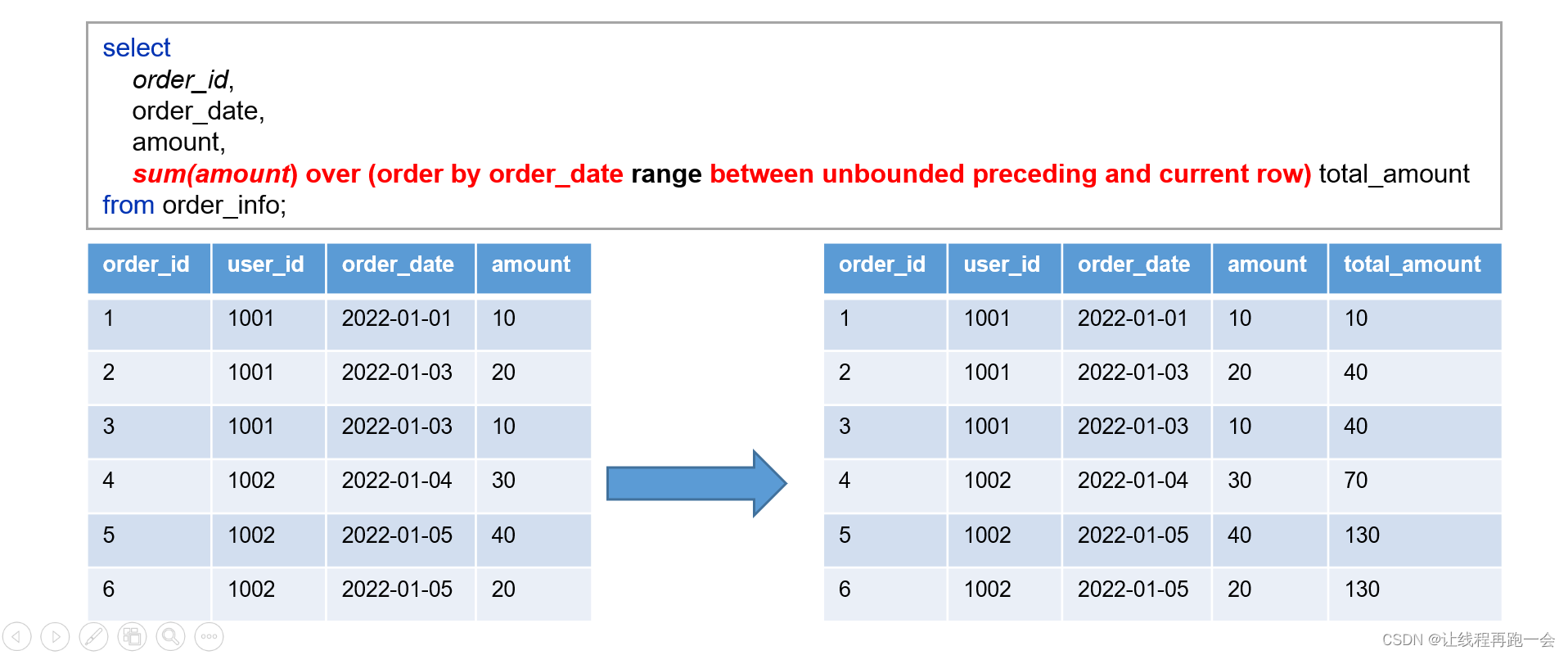
实际意义:截止当前日期的销售总额。
分区
定义窗口范围时,可以指定分区字段,每个分区单独划分一个窗口。
sum(amount) over (partition by 划分窗口范围的字段 rows between 起点 and 终点) 别名案例
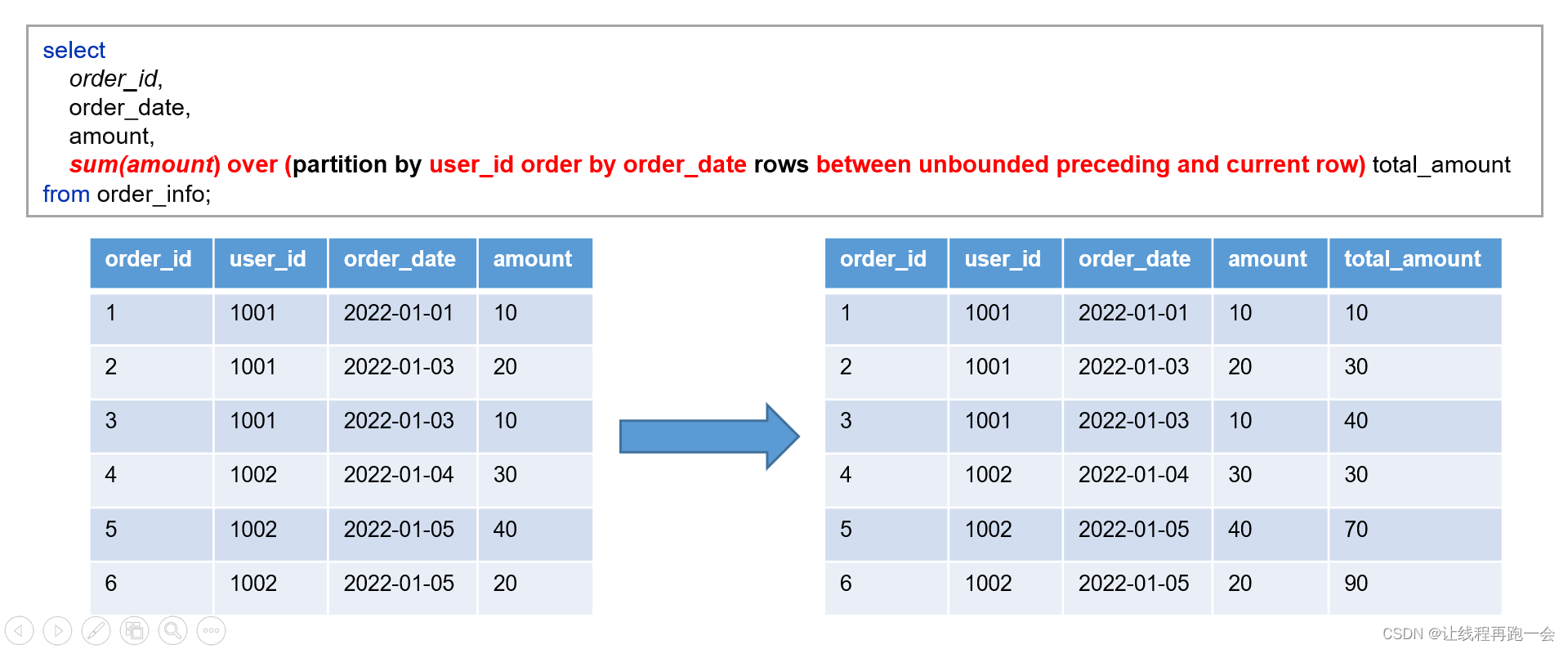
实际意义:每个用户截止到最后下单的累计下单金额。
缺省
over() 中的三部分内容 partition by、order by 、(rows |range) between ... and ... 均可省略不写。
partition by 省略不写,代表不分区。
order by 省略不写:
- 如果是基于 row 的,则 order by 必须写,除非窗口范围是第一行到最后一行(rows between unbounded preceding and unbounded following)。
- 如果是基于 range ,order by 同样必须写。因为如果不写,就相当于没有声明根据哪个字段的值来声明窗口的范围,同样无效,此时,窗口范围是 (负无穷,正无穷)。
(rows |range) between ... and ...省略不写:
- 如果over()中包含 order by:则默认值为 range between unbounded preceding and current row (也就是从 小于等于当前值的第一个值 到 当前值。)
- 如果over()中不包含 order by:则默认值为 rows between unbounded preceding and unbounded following (也就是从 当前值 到 大于等于当前值的最后一个值。)
常用窗口函数
按照功能,常用窗口可划分为如下几类:聚合函数、跨行取值函数、排名函数。
1)聚合函数
- max:最大值。
- min:最小值。
- sum:求和。
- avg:平均值。
- count:计数。
2)跨行取值函数
(1)lead和lag
功能:获取当前行的上/下边某行、某个字段的值。
- lead:用来获取下边某行的值
- lag:用来获取上边某行的值
select
order_id,
user_id,
order_date,
amount,
lag(order_date,1,'1970-01-01') over (partition by user_id order by order_date) last_date,
lead(order_date,1,'9999-12-31') over (partition by user_id order by order_date) next_date
from order_info;
注意:lead 和 lag 不能够自定义窗口范围(也就是不能添加 range between ... / rows between ...),因为 lead 和 lag 有它特定的逻辑,如果真的支持自定义窗口范围的话,上面的代码中应该默认是基于列的: range between unbounded preceding and current row ,这样的话根本无法实现取上一行或者下一行。
其中,lag 和 lead 的3个参数分别代表:(字段名,偏移量,默认值)。
运行结果:
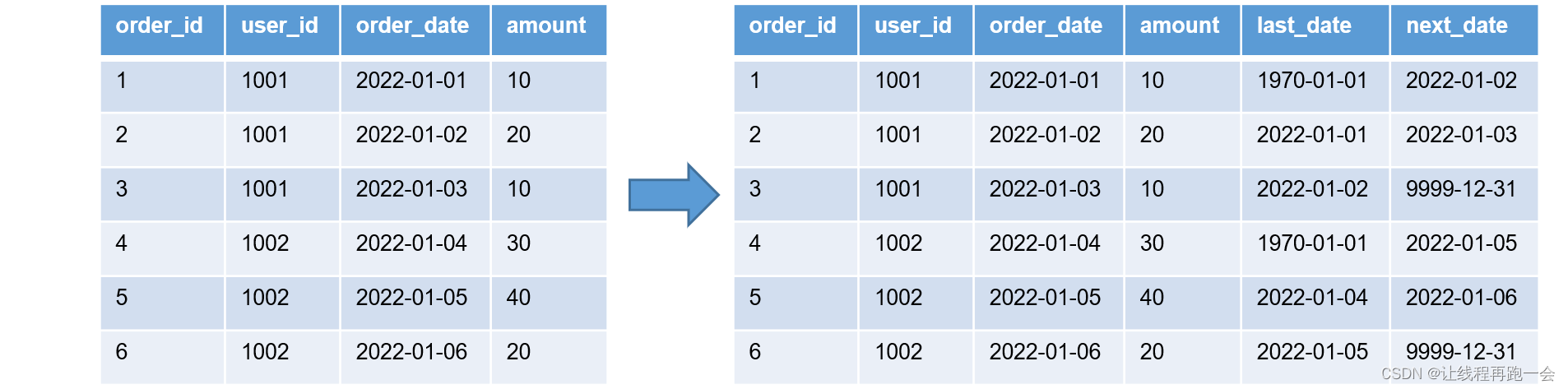
实际意义:获取用户两次下单时间,我们可以计算出两次下单时间的差值。
(2)first_value 和 last_value
功能:获取窗口内某一列的第一个值/最后一个值
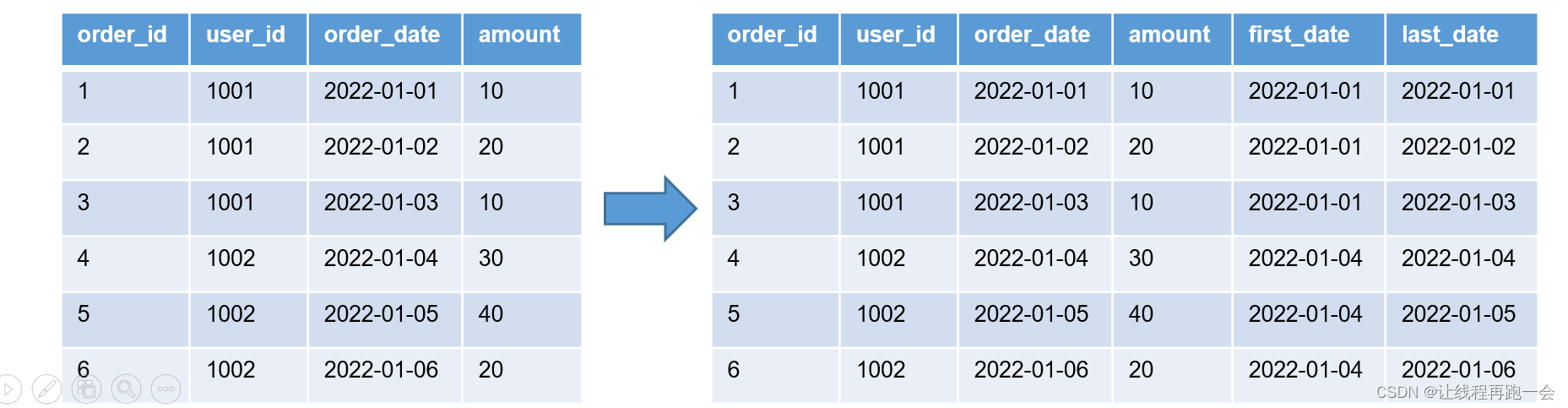
select
order_id,
user_id,
order_date,
amount,
first_value(order_date,false) over (partition by user_id order by order_date) first_date,
last_value(order_date,false) over (partition by user_id order by order_date) last_date
from order_info;
first_value 和 last_value 的2个参数分别代表:(字段名,是否跳过 null)。
注意:这里的 first_value 和 last_value 是可以自定义窗口范围的,上面的代码中我们有 order by 字段,所以默认是基于列的 range between unbounded preceding and current row (<= 当前值,当前值)。
运行结果:
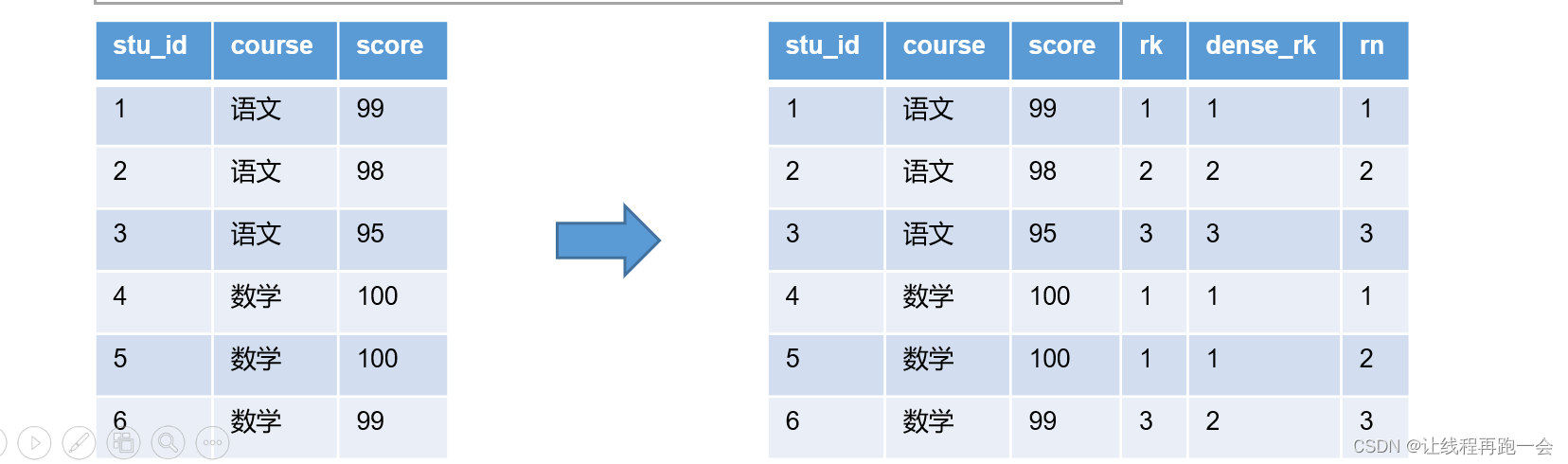
(3)排名函数
常用的排名函数: rank、dense_rank、row_number。
遇到相同名次时,rank 的结果是:1 1 3 ;而 dense_rank 是密集排名,结果是:1 1 2 ;row_number 是 1 2 3;
注意:排名函数也不支持自定义窗口范围!
select
st_id,
course
score,
rank() over (partition by course order by score) rk,
dense_rank() over(partition by course order by score desc) dense_rk,
row_number() over(partition by course order by score desc) rn
from score_info;
运行结果: