【JAVA基础】-JAVA开发中XML解析多种方法
【JAVA基础】-JAVA开发中XML解析多种方法
1、什么是XML
XML是可扩展标记语言(Extensible Markup Language)是一种标记语言,是从标准通用标记语言(SGML)中简化修改而来,它主要用到的有可扩展标记语言、可扩展式语言(XSL)、XBRL和XPath等。
XML设计用来传输和存储数据,而不是显示数据。
2、本文操作所用XML示例
<?xml version="1.0" encoding="UTF-8"?>
<street>
<code>110101001</code>
<name>东华门街道办事处</name>
<areaCode>110101</areaCode>
<provinceCode>11</provinceCode>
<cityCode>1101</cityCode>
</street>
如上示例使用简单的具有自我描述性的语法,第一行是XML声明。它定义XML的版本(1.0)和所使用的编码(UTF-8),描述文档的根元素。XML文档必须包含根元素,该元素是所有其他元素的父元素。XML文档是一个文档树,从根部开始,并扩展到树的最底部。具体如下图:
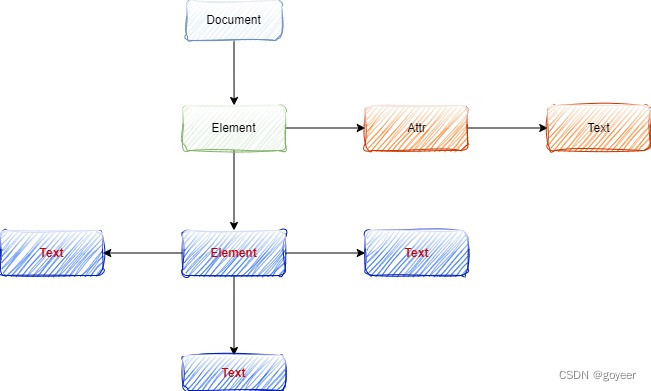
3、DOM解析XML文件
JAVA官方提供通过DOM实现对XML文件读取。DOM读取XML文件原理是:将整个XML文件预加载完毕后,才进行解析,在JAVA程序中读取XML文件效率取决于XML文件大小。
Dom解析XML步骤
-
获取DocumentBuilderFactory
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); -
通过DocumentBuilderFactory产生一个DocumentBuilder
DocumentBuilder builder=factory.newDocumentBuilder(); -
利用DocumentBuilder的parser方法加载xml创建对象Document
Document document=builder.parse(new File("street.xml")); -
解析XML文件属性名和属性值
NodeList nodeList = document.getElementsByTagName("book"); Node node = nodeList.item(i); NamedNodeMap nameNodeMap = node.getAttributes(); Node attr = nameNodeMap.item(i); //获取属性名 String nodeName = attr.getNodeName(); //获取属性值 String nodeValue = attr.getNodeValue(); -
解析XML文件的节点名和节点值
NodeList nodeList=document.getChildNodes(); Node node = node.item(i); //获取element类型element类型节点的节点值 String nodeName = node.getNodeName(); //获取element类型值 String nodeValue = node.getTextContent();
Dom解析XML示例代码
public void readXmlByDocument() throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("street.xml"));
Element root = document.getDocumentElement();
NodeList nodeList = root.getChildNodes();
int len = nodeList.getLength();
for (int i = 0; i < len; i++) {
Node node = nodeList.item(i);
String nodeName = node.getNodeName();
String localName = node.getLocalName();
System.out.println(nodeName);
}
}
4、JDOM解析XML文件
meaven引用依赖
<dependency>
<groupId>org.jdom</groupId>
<artifactId>jdom2</artifactId>
<version>2.0.6</version>
</dependency>
JDOM解析XML步骤
-
创建SAXBuilder对象
SAXBuilder saxBuilder = new SAXBuilder(); -
调用build方法获得Document对象
Document document = saxBuilder.build(new FileInputStream("street.xml")); -
获取根节点
Element root = document.getRootElement(); -
获取根节点的直接子节点集合
List<Element> children = root.getChildren(); -
遍历节点集合
for (Element element: children) {}
JDOM解析XML示例代码
public void readXmlByJDom() throws Exception{
SAXBuilder builder = new SAXBuilder();
Document document = builder.build(new File("street.xml"));
Element root = document.getRootElement();
List<Element> children = root.getChildren();
for (Element element: children) {
String elementName= element.getName();
String elementText =element.getText();
System.out.println(elementName);
System.out.println(elementText);
}
}
5、Dom4j解析XML文件
meaven引用依赖
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.1</version>
<scope>test</scope>
</dependency>
Dom4j解析XML步骤
-
创建SAXReader对象
SAXReader reader=new SAXReader(); -
调用SAXReader的read方法加载XML文件并创建Document对象
Document document = reader.read(new File("street.xml")); -
通过Document的方法getRootElement获取根结点
Element root = document.getRootElement(); -
获取子节点值
String nameText = root.elementText("name");
Dom4j解析XML示例
public void readXMLJDom4() throws Exception{
SAXReader reader=new SAXReader();
Document document = reader.read(new File("street.xml"));
Element root = document.getRootElement();
QName qName = root.getQName();
String name = qName.getName();
String name1 = root.getName();
String nameText = root.elementText("name");
System.out.println(nameText);
}
6、SAX读取并解析XML文件
Sax读取原理:Sax对xml文件的读取是采用事件机制的,当某事件发生时,会自动触发定义好的事件处理方法。基本的事件有:Document,Element,characters三种最基本的事件。
Dom4j解析XML步骤
-
方式一:
-
创建SAXParserFactory 通过SAXParserFactory.newInstance();
SAXParserFactory factory=SAXParserFactory.newInstance(); -
通过SAXParser.newSAXParser()创建SAXParser的实例对象;
SAXParser parser = factory.newSAXParser(); -
获取处理类,创建一个继承于DefaultHandler的累,并重写读取xml方法;
StreetHandle handler =new StreetHandle(); parser.parse(new File("street.xml"),handler); -
进行解析,通过SAXParser.parse方法进行解析;
-
-
方法二:
-
创建SAXParserFactory 通过SAXParserFactory.newInstance();
SAXParserFactory spf = SAXParserFactory.newInstance(); -
通过SAX解析工厂得到解析器对象
SAXParser sp = spf.newSAXParser(); -
通过解析器对象得到一个XML的读取器
XMLReader xmlReader = sp.getXMLReader(); -
设置读取器的事件处理器
xmlReader.setContentHandler(new BookParserHandler()); -
解析XML文件
xmlReader.parse("street.xml");
SAX读取并解析XML示例
-
创建Handle类
import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; import java.util.ArrayList; import java.util.List; public class StreetHandle extends DefaultHandler { public List<Street> list = new ArrayList<Street>(); Street street = null; StringBuilder sb = null; @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { System.out.println(localName); if("street".equals(qName)){ street=new Street(); String name = attributes.getValue("name"); street.setName(name); list.add(street); } } @Override public void characters(char[] ch, int start, int length) throws SAXException { System.out.println("characters->" + new String(ch, start, length)); } @Override public void endElement(String uri, String localName, String qName) throws SAXException { System.out.println("endElement->" + localName); } } -
SAX解析实例
public void readXmlSAX() throws Exception { SAXParserFactory factory=SAXParserFactory.newInstance() SAXParser parser = factory.newSAXParser(); StreetHandle handler =new StreetHandle(); parser.parse(new File("street.xml"),handler); List<Street> list=handler.list; System.out.println("readXMLSAX"); System.out.println(list.size()); }
-
7、总结
读取并解析XML有上面4种方案,根据不同的应用场合,使用恰当的方法。
DOM解析:一次性把XML文档内容加载到内存,构建Document对象。
- 不适合读取大容量的xml文件;
- Dom解析可以随意读取,甚至往回读取;
- Dom解析可以实现增删改查;
常用解析工具:Dom4j
SAX解析:读取一点,解析一点。
- 适合读取大容量的xml文件;
- 从上往下逐点读取,不能往回读;
- SAX解析通常只读取文件,不能对文件进行操作;