Informer时序模型(自定义项目)
开源项目
说明
- 读完代码解析篇,我们针对开源项目中的模型预测方法做一下介绍。作者在Github上给出了模型预测方法以及Q、K图的做法,这里提供下载链接
- 首先,在不更改任何参数的情况下跑完代码,会在项目文件夹中生成两个子文件夹
-
checkpoints文件夹中包含训练完成的模型,后缀名为.pth,该模型文件包含完整的模型架构与各层权重,可以通过torch.load函数加载模型 -
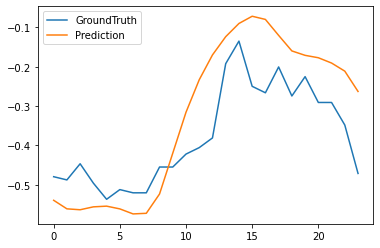
results文件夹中包含metrics.npy、pred.npy、true.npy三个文件,pred.npy表示模型预测值,true.npy表示序列真实值 - 我们可以先将
pred.npy与true.npy文件作图进行对比,观察模型效果
setting = 'informer_power data_ftMS_sl96_ll48_pl24_dm512_nh8_el2_dl1_df2048_atprob_fc5_ebtimeF_dtTrue_mxTrue_exp_0'
pred = np.load('./results/'+setting+'/pred.npy')
true = np.load('./results/'+setting+'/true.npy')
print(pred.shape)
print(true.shape)
import matplotlib.pyplot as plt
plt.figure()
plt.plot(true[0,:,-1], label='GroundTruth')
plt.plot(pred[0,:,-1], label='Prediction')
plt.legend()
plt.show()
输出:
- 如果想要得到模型对后面时间序列的预测值,有2种方式:
- 第1种:在pycharm模型训练之前将参数
'--do_predict'由'store_true'变为'store_false',这样在代码运行完以后results文件夹中会多出一个文件real_prediction.npy,该文件中即是模型预测的序列值。 - 第2种:在模型训练完以后(在
jupyter notebook)中使用exp.predict(setting, True)得到预测值
输出:
- 第1种:在pycharm模型训练之前将参数
在Kaggle上使用
- 在Kaggle上我们可以使用免费的GPU来训练模型,达到加速效果,这里把作者的代码解析一遍。
下载项目文件
!git clone https://github.com/zhouhaoyi/Informer2020.git
!git clone https://github.com/zhouhaoyi/ETDataset.git
!ls
导入包
from utils.tools import dotdict
import matplotlib.pyplot as plt
from exp.exp_informer import Exp_Informer
import torch
参数传导
- 这个地方与在pycharm中不一样,请注意!
args = dotdict()
args.model = 'informer' # model of experiment, options: [informer, informerstack, informerlight(TBD)]
args.data = 'ETTh1' # data
args.root_path = './ETDataset/ETT-small/' # root path of data file
args.data_path = 'ETTh1.csv' # data file
args.features = 'M' # forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate
args.target = 'OT' # target feature in S or MS task
args.freq = 'h' # freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h
args.checkpoints = './informer_checkpoints' # location of model checkpoints
args.seq_len = 96 # input sequence length of Informer encoder
args.label_len = 48 # start token length of Informer decoder
args.pred_len = 24 # prediction sequence length
# Informer decoder input: concat[start token series(label_len), zero padding series(pred_len)]
args.enc_in = 7 # encoder input size
args.dec_in = 7 # decoder input size
args.c_out = 7 # output size
args.factor = 5 # probsparse attn factor
args.d_model = 512 # dimension of model
args.n_heads = 8 # num of heads
args.e_layers = 2 # num of encoder layers
args.d_layers = 1 # num of decoder layers
args.d_ff = 2048 # dimension of fcn in model
args.dropout = 0.05 # dropout
args.attn = 'prob' # attention used in encoder, options:[prob, full]
args.embed = 'timeF' # time features encoding, options:[timeF, fixed, learned]
args.activation = 'gelu' # activation
args.distil = True # whether to use distilling in encoder
args.output_attention = False # whether to output attention in ecoder
args.mix = True
args.padding = 0
args.freq = 'h'
args.batch_size = 32
args.learning_rate = 0.0001
args.loss = 'mse'
args.lradj = 'type1'
args.use_amp = False # whether to use automatic mixed precision training
args.num_workers = 0
args.itr = 1
args.train_epochs = 6
args.patience = 3
args.des = 'exp'
args.use_gpu = True if torch.cuda.is_available() else False
args.gpu = 0
args.use_multi_gpu = False
args.devices = '0,1,2,3'
检查GPU
args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else False
if args.use_gpu and args.use_multi_gpu:
args.devices = args.devices.replace(' ','')
device_ids = args.devices.split(',')
args.device_ids = [int(id_) for id_ in device_ids]
args.gpu = args.device_ids[0]
定义数据加载
# Set augments by using data name
data_parser = {
'ETTh1':{'data':'ETTh1.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},
'ETTh2':{'data':'ETTh2.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},
'ETTm1':{'data':'ETTm1.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},
'ETTm2':{'data':'ETTm2.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},
}
if args.data in data_parser.keys():
data_info = data_parser[args.data]
args.data_path = data_info['data']
args.target = data_info['T']
args.enc_in, args.dec_in, args.c_out = data_info[args.features]
训练模型
args.detail_freq = args.freq
args.freq = args.freq[-1:]
Exp = Exp_Informer
for ii in range(args.itr):
# setting record of experiments
setting = '{}_{}_ft{}_sl{}_ll{}_pl{}_dm{}_nh{}_el{}_dl{}_df{}_at{}_fc{}_eb{}_dt{}_mx{}_{}_{}'.format(args.model, args.data, args.features,
args.seq_len, args.label_len, args.pred_len,
args.d_model, args.n_heads, args.e_layers, args.d_layers, args.d_ff, args.attn, args.factor, args.embed, args.distil, args.mix, args.des, ii)
# set experiments
exp = Exp(args)
# train
print('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting))
exp.train(setting)
# test
print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.test(setting)
torch.cuda.empty_cache()
- 到这里模型训练完毕
预测
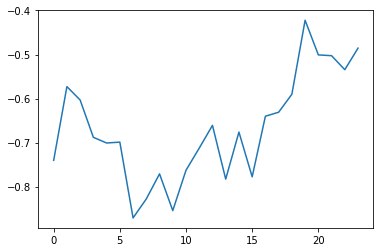
- 运行完会在
results文件夹中生成real_prediction.npy序列预测数据
import os
setting = 'informer_ETTh1_ftM_sl96_ll48_pl24_dm512_nh8_el2_dl1_df2048_atprob_fc5_ebtimeF_dtTrue_mxTrue_exp_0'
exp = Exp(args)
exp.predict(setting, True)
prediction = np.load('./results/'+setting+'/real_prediction.npy')
plt.figure()
plt.plot(prediction[0,:,-1], label='Prediction')
plt.legend()
plt.show()
自定义项目
数据处理
- 首先将数据集放入项目
data文件夹中,然后修改'--data'、'--root_path'、'--data_path'、'--data_path'参数。 - 比如在这里,我使用的是
power data.csv数据集(下载链接),那么我的参数应该修改成这样:
parser.add_argument('--data', type=str, default='power data')
parser.add_argument('--root_path', type=str, default='./data/')
parser.add_argument('--data_path', type=str, default='power data.csv')
- 然后修改预测类型,这里我使用多变量预测单变量,所以
--features参数选择MS;预测的变量名称为总有功功率,所以修改'--target'参数;时间采样为15分钟,所以将'--freq'参数改为t即:
parser.add_argument('--features', type=str, default='MS')
parser.add_argument('--target', type=str, default='总有功功率')
parser.add_argument('--freq', type=str, default='t')
- 我想序列长度为192(2天),有标签预测序列长度为96(1天),无标签预测序列长度为48(半天),修改参数
'--seq_len'、'--label_len'、'--pred_len'为:
parser.add_argument('--seq_len', type=int, default=192)
parser.add_argument('--label_len', type=int, default=96)
parser.add_argument('--pred_len', type=int, default=48)
- 接下来跳到数据处理方式
data_parser,参照项目原有处理方式进行填写:
data_parser = {'power data':{'data':'power data.csv','T':'总有功功率','M':[5,5,5],'S':[1,1,1],'MS':[5,5,1]},
}
- 找到
exp_informer.py文件,_get_data类中data_dict参数,使用Dataset_Custom对数据进行处理,即:
data_dict = {'power data':Dataset_Custom,}
- 到这里数据处理修改结束
模型参数
- 这里我希望模型运行结束后生成预测序列文件,所以我将
'--do_predict'参数修改为'store_false',即:
parser.add_argument('--do_predict', action='store_false')
- 其他参数,比如学习率等等,大家可以根据任务要求自行修改,这里我就不再赘述了。
在Kaggle上使用
- 将项目放在Kaggle上使用GPU加速运算,这里我将基于此数据的Kaggle项目分享给大家,大家可以参照我的项目搭建自己的模型。