kafka:各组件概念
摘要
kafka主要由Scala和Java编写,broker启动后可以直接用jps -l查看到是kafka进程。kafka是一种高吞吐量的分布式发布订阅消息系统,组件参数都比较多。
总体组件
kafka的组件主要有:Kafka Cluster(zookeeper和kafka broker组成)、Producer、Consumer、Connector、Stream,总体架构图如下:
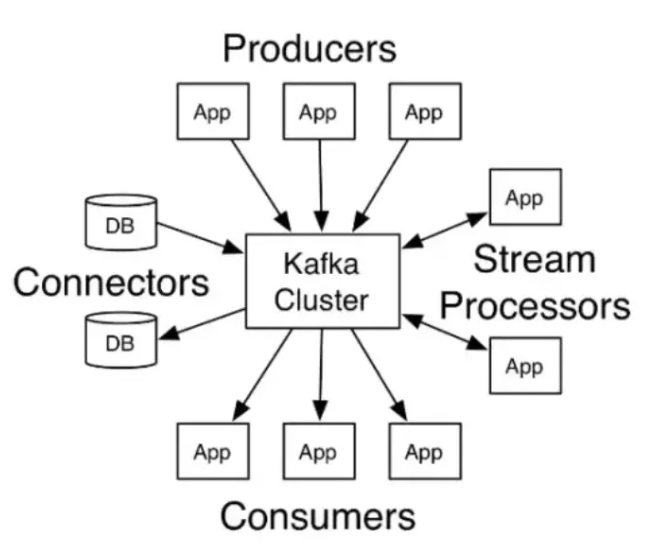
Kafka Cluster:kafka集群,主要由zookeeper和broker组成。
broker:kafka服务代理节点,它就是我们在kafka官网下载安装包配置启动后的服务。单机只需启动一个broker,集群需要多个broker启动,broker启动都需要连接zookeeper在里面注册信息,因此无论单机还是集群,都需要先启动zookeeper。
zookeeper:主要用于维护kafka broker的元数据信息,比如zookeeper的/brokers/ids 路径下有各kafka节点的broker.id。
producer:生产者,主要通过kefka客户端api给kafka发送消息。
consumer:消费者,主要通过kefka客户端api消费kafka的消息。
connector:连接器,可以将kafka直连数据库,比如,kafka可以通过connectors直连mysql和elasticsearch,将mysql的数据直接通过kafka导入到es中,中间不需要开发生产消费代码。
stream:流处理,通过流处理API可以实时对kafka的消息进行处理,比如将一个主题的消息处理后发送到另一个主题。
消息相关组件
topic:主题,用于存储一类消息,生产和消费者都以主题为容器发送和消费消息的。一个主题有多个分区,每个分区存储着消息。
partition:分区,为了加大吞吐量,每个主题在kafka内部维护了多个队列(分区),消息最终是存在分区下的。
key:消息键,当发送消息,不指定分区且key不为空时,相同key的消息会被发送到同一分区。分区默认策略就是对key进行hash,而key为空则轮询分配分区。
value:消息信息,该值一般保存具体的业务消息。
consumer gourp:消费组,多个消费者的组ID一致时,主题的分区会分配给同组下的消费者进行消费。即同组消费者只会消费主题下不同分区的消息,不会消费相同的消息。
offset:偏移量,当前分区的消费偏移量,记录消费者消费的最新消息的索引。
高可用相关组件
controller:控制节点,集群中的一个broker作为leader来管理整个集群。若leader挂掉,则会重新选举出新leader。
replication:副本,每个partition分区可以设置多个副本,副本之间数据一致,相当于备份。
leader:以上分区的副本中,只有一个为leader,可以读写消息。
fllower:以上分区的副本中,除了leader,都为fllower,功能只有一个,从leader拉取消息,不参与生产和消费,仅仅是备份。消费者只能获取leader分区的消息。只有leader挂掉,才会从fllower里选举出leader。