机器学习:什么是分类/回归/聚类/降维/决策
目录
我们将涵盖目前「五大」最常见机器学习任务:
-
回归
-
分类
-
聚类
-
降维
-
决策
学习模式分为三大类:监督,无监督,强化学习

监督学习基本问题
分类问题
-
分类是监督学习的一个核心问题。
-
在监督学习中,当输出变量Y取有限个离散值时,预测问题变成为分类问题。
-
这时,输入变量X可以是离散的,也可以是连续的。
-
监督学习从数据中学习一个分类模型或分类决策函数,称为分类器(classifier)。
-
分类器对新的输入进行输出的预测,成为分类(classification)。
-
可能的输出成为类别(class)。
-
分类的类别为多个时,称为多分类问题。
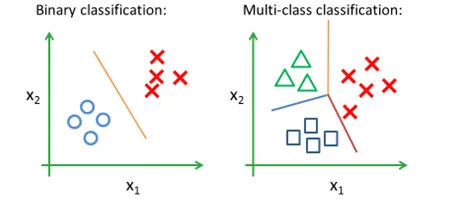
分类问题包括学习和分类两个过程,也就是训练和测试的过程。在学习过程中,根据已知的训练数据集利用有效的学习方法学习一个分类器;在分类过程中,利用学习的分类器对新的输入实例进行分类。
分类问题可以通过下图来描述。图中是训练数据集,学习系统由训练数据学习一个分类器或;分类系统通过学到的分类器或对新的输入实例进行分类,即预测其输出的类标记。
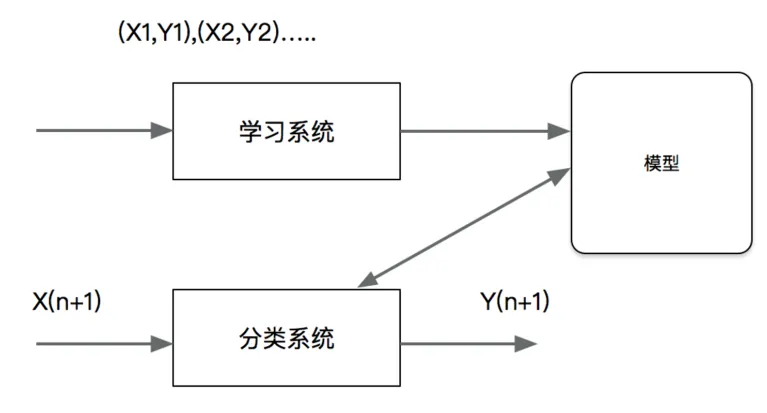
分类问题
评价分类器性能的指标有分类精度(accuracy)、查准率(precision)和召回率(recall)等,
许多机器学习算法可以用于分类问题,包括k近邻法、感知机、朴素贝叶斯、决策树、逻辑斯蒂回归、支持向量机、提升方法、贝叶斯网络、神经网络等等。
分类任务根据其特性将数据“分门别类”,所以在许多领域都有广泛的应用。例如,在银行业务中,可以构建一个客户分类模型,对客户按照贷款风险的大小进行分类;在网络安全领域,可以利用日志数据的分类对非法入侵进行检测;在图像处理中,分类可以用来检测图像中是否有人脸出现;在手写识别中,分类可以用于识别手写的数字;在互联网搜索中,网页的分类可以帮助网页的抓取、索引与排序。
回归问题
-
回归(regression)是监督学习的另一个重要问题。
-
回归用于预测输入变量(自变量)和输出变量(因变量)之间的关系,特别是当输入变量的值发生变化时,输出变量的值随之发生的变化。
-
回归模型正是表示从输入变量到输出变量的之间映射的函数。
-
回归问题的学习等价于函数拟合:选择一条函数曲线使其很好地拟合已知数据且很好地预测未知数据。
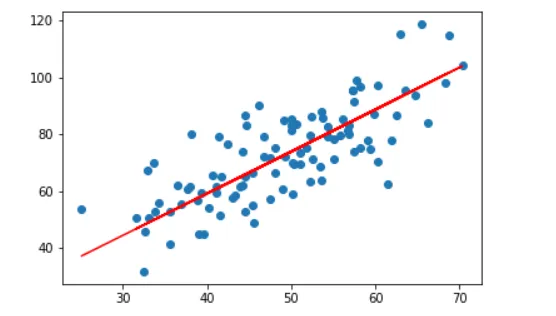
回归问题也分为学习和预测两个过程。首先给定一个训练数据集,其中是输入,是对应的输出,。学习系统基于训练数据构建一个模型,即函数;对新的输入,预测系统根据学习的模型确定相应的输出。
回归问题按照输入变量的个数,分为一元回归和多元回归;按照输入变量和输出变量之间关系的类型即模型的类型,分为线性回归和非线性回归。
回归学习最常用的损失函数是平方损失函数
许多领域的任务都可以形式化为回归问题,比如,回归可以用于商务领域,作为市场趋势预测、产品质量管理、客户满意度调查、投资风险分析的工具。
无监督学习基本问题
聚类问题
-
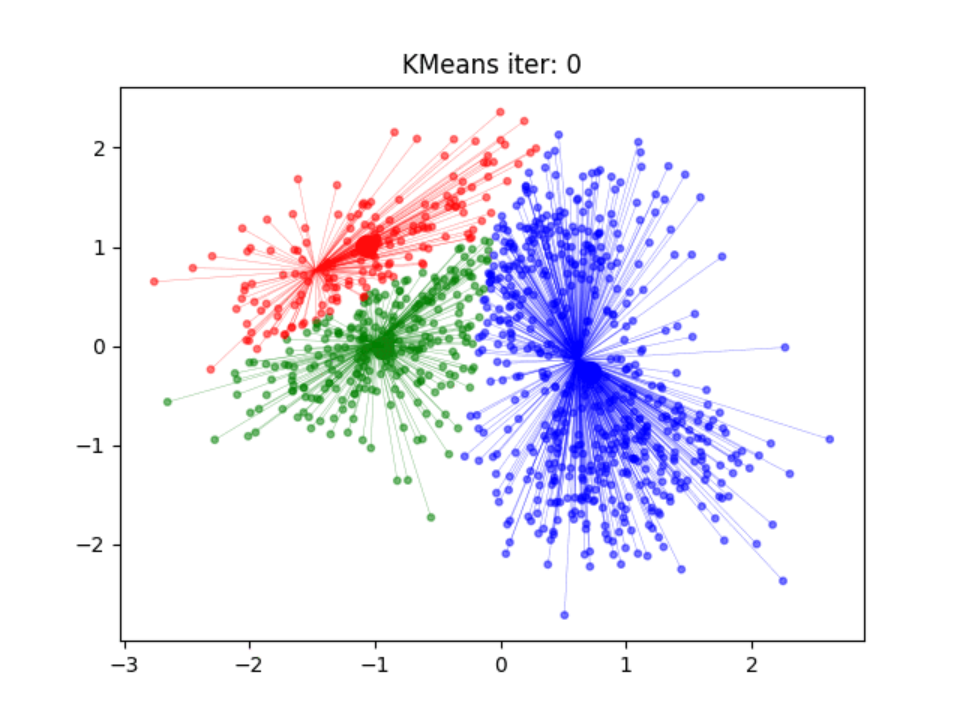
聚类(clustering)是将样本集合中相似的样本(实例)分配到相同的类,不相似的样本分配到不同的类。
-
聚类时,样本通常是欧式空间中的向量,类别不是事先给定,而是从数据中自动发现,但个别的个数通常是实现给定的。
-
样本之间的相似度或距离由应用决定。
-
如果一个样本只能属于一个类,则称为硬聚类(hard clustering),如果一个样本可以属于多个类,则称为软聚类(soft clustering)。
-
聚类的过程就是学习聚类模型的过程。
降维问题
-
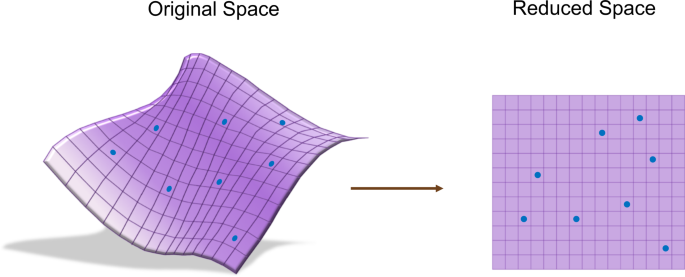
降维(dimensionality reduction)是将训练数据中的样本(实例)从高位空间转换到低维空间。
-
假设样本原本存在于低维空间,或者近似地存在于低维空间,通过降维则可以更好地表示样本数据的结构,即更好地表示样本之间的关系。
-
高维空间通常是高维的欧式空间,而低维空间是低维的欧式空间或者流形(manifold)。
-
低维空间不是事先给定的,而是从数据中自动发现的,其位数通常是事先给定的。
-
从高维到低维的降维中,要保证样本中的信息损失最小。
-
降维有线性降维和非线性降维。
强化学习基本问题
决策问题
机器学习中的决策任务不同于分类、回归、聚类和降维,是将待解决问题建模为马尔科夫决策过程,然后利用强化学习求解的问题框架。强化学习的目标就是给定一个马尔科夫决策过程,寻找到最优策略。
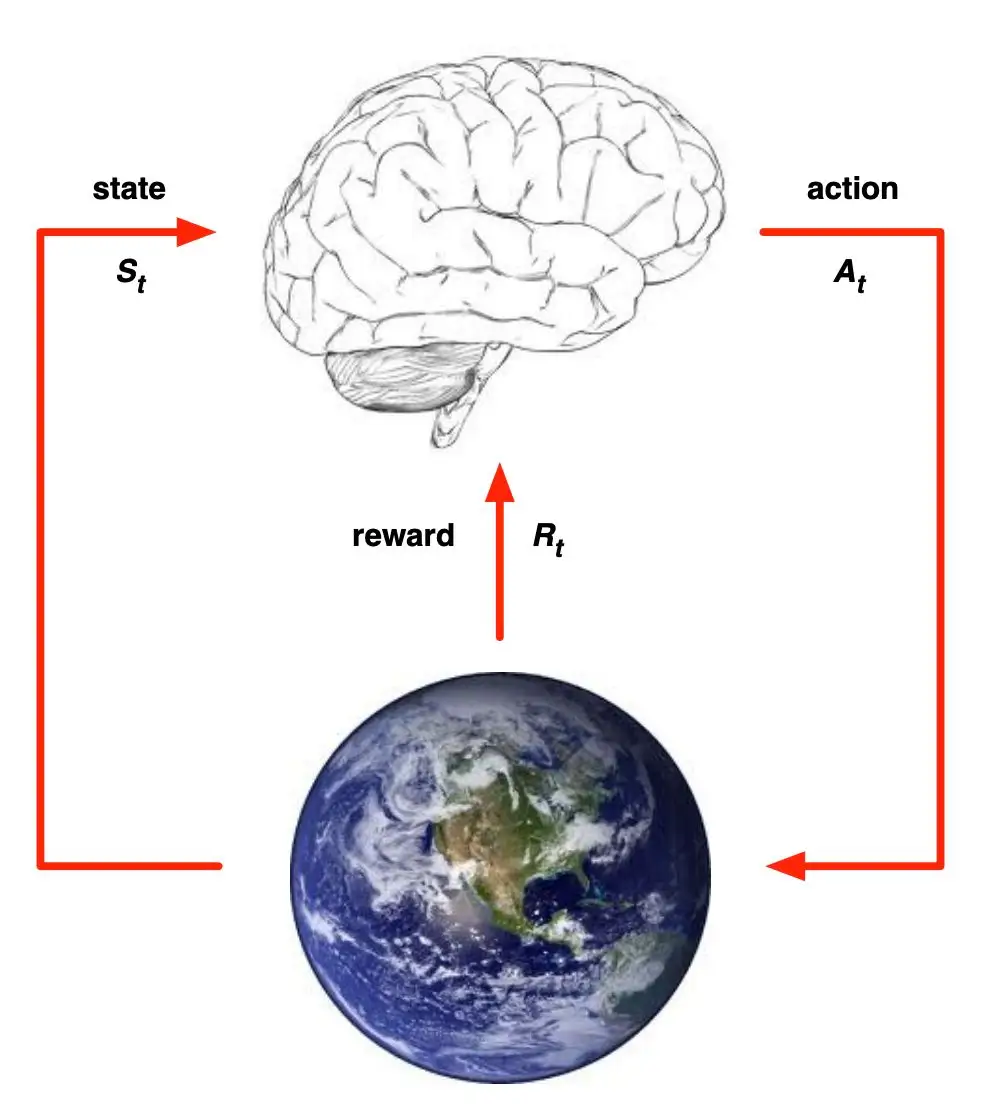
下图解释了强化学习的基本原理。智能体在完成某项任务时,首先通过动作A与周围环境进行交互,在动作A和环境的作用下,智能体会产生新的状态,同时环境会给出一个立即回报。如此循环下去,智能体与环境不断地交互从而产生很多数据。强化学习算法利用产生的数据修改自身的动作策略,再与环境交互,产生新的数据,并利用新的数据进一步改善自身的行为,经过数次迭代学习后,智能体最终学到完成相应任务的最优动作(最优策略)。
从强化学习的基本原理能看出它与其他机器学习算法如监督学习和非监督学习的一些基本差别。在监督学习和非监督学习中,数据是静态的、不需要与环境进行交互,比如图像识别,只要给出足够的差异样本,将数据输入深度神经网络中进行训练即可。
然而,强化学习的学习过程是动态的、不断交互的过程,所需要的数据也是通过与环境不断交互所产生的。强化学习更像是人的学习过程,即与通过与周围环境交互进行学习。
如何选择合适的算法
你使用机器学习算法的目的,想要完成什么任务?比如是预测明天下雨的概率还是对投票者按照兴趣分组;想要选择合适的算法,必须考虑以下两个问题:
首先考虑机器学习算法的目的。如果想要预测目标变量的值,则可以选择监督学习算法,否则可以选择无监督学习。确定选择监督学习算法后,需要进一步明确目标变量的类型,如果目标变量是离散型,则可以选择分类算法;如果是连续型,则需要选择回归算法。
其次应该考虑实际的数据问题,应该充分了解数据,对实际数据了解的越充分,越容易创建符合实际需要的应用程序。
主要应该了解数据的以下特征:
-
特征值是离散型变量还是连续型变量
-
特征值中是否有缺失的值,何种原因造成
-
数据中是否有异常值
-
某些特征发生的频率如何
通过上面对数据的充分了解,可以帮助我们缩小算法的选择范围,一般并不存在最好的算法和可以给出最好效果的算法,一般发现最好算法的关键环节是反复试错的迭代过程。