NoSQL简介
一、什么是NoSQL
NoSQL是Not Only SQL的缩写,意即"不仅仅是SQL"的意思,泛指非关系型的数据库。强调Key-Value Stores和文档数据库的优点。
NoSQL产品是传统关系型数据库的功能阉割版本,通过减少用不到或很少用的功能,来大幅度提高产品性能
二、NoSQL起源
过去,关系型数据库(SQL Server、Oracle、MySQL)是数据持久化的唯一选择,但随着发展,关系型数据库存在以下问题。
问题1:不能满足高性能查询需求
我们使用:Java、.Net等语言编写程序,是面向对象的。但所使用数据库都是关系型数据库。存储结构是面向对象的,但是数据库却是关系的,所以在每次存储或者查询数据时,我们都需要做转换。类似Hibernate、Mybatis这样的ORM框架确实可以简化这个过程,但是在对高性能查询需求时,这些ORM框架就捉襟见肘了。
问题2:应用程序规模的变大
网络应用程序的规模变大,需要储存更多的数据、服务更多的用户以及需求更多的计算能力。为了应对这种情形,我们需要不停的扩展。
扩展分为两类:一种是纵向扩展,即购买更好的机器,更多的磁盘、更多的内存等等。另一种是横向扩展,即购买更多的机器组成集群。在巨大的规模下,纵向扩展发挥的作用并不是很大。首先单机器性能提升需要巨额的开销并且有着性能的上限,在Google和Facebook这种规模下,永远不可能使用一台机器支撑所有的负载。鉴于这种情况,我们需要新的数据库,因为关系数据库并不能很好的运行在集群上
三、NoSQL数据库类型
1.键值(Key-Value)数据库[Redis/Memcached]适用场景:
储存用户信息,比如会话、配置文件、参数、购物车等等。这些信息一般都和ID(键)挂钩,这种情景下键值数据库是个很好的选择。
不适用场景:
a.取代通过键查询,而是通过值来查询。Key-Value数据库中根本没有通过值查询的途径
b.需要储存数据之间的关系。在Key-Value数据库中不能通过两个或以上的键来关联数据。
c.事务的支持。在Key-Value数据库中故障产生时不可以进行回滚。
2.面向文档(Document-Oriented)数据库[MongoDB]
数据可以使用XML、JSON或者JSONB等多种形式存储。
适用场景:日志、分析
不适用场景:不支持事务
3.列存储(Wide Column Store/Column-Family)数据库[HBASE]
列存储数据库将数据储存在列族(column family)中,一个列族存储经常被一起查询的相关数据。举个例子,如果我们有一个Person类,我们通常会一起查询他们的姓名和年龄而不是薪资。这种情况下,姓名和年龄就会被放入一个列族中,而薪资则在另一个列族中。
适用场景:日志、博客平台,我们储存每个信息到不同的列族中。列如,标签可以储存一个,类别可以存在一个,而文章存在另一个。
不适用场景:ACID事务、原型设计。在模型设计之初,我们根本不可能去预测它的查询方式,而一旦查询方式改变,我们就必须重新设计列族。
4.图(Graph-Oriented)数据库[Neo4J]
适用范围很小,主要用用网络拓扑分析如脉脉的人员关系图等。
四、传统RDBMS VS NOSQL
1.RDBMS
-高度组织化结构化数据
-结构化查询语言(SQL)
-数据和关系都存储在单独的表中
-数据操纵语言,数据定义语言
-严格的一致性
-基础事务
2.NosQL
-代表着不仅仅是SQL-没有声明性查询语言心
-没有预定义的模式
-键-值对存储,列存储,文档存储,图形数据库
-最终一致性,而非ACID【原子,一致,隔离,持久】属性
-非结构化和不可预知的数据
-CAP定理【一致性,可用性,容错性】
-高性能,高可用性和可伸缩性
五、常见的NoSQL数据库
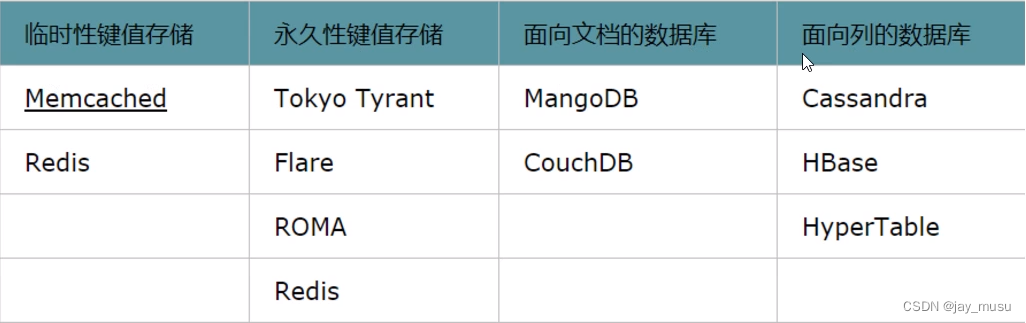
六、不同NoSQL数据库的区别
1.Memcached
挥发性(临时性)的键值存储
一般作为关系型数据库的缓存来使用
具有非常快的处理速度
由于存在数据丢失的可能,所以一般用来处理不需要持久保存的数据
用于需要使用expires时(需要定期清除数据)
使用一致性散列(Consistent Hashing)算法来分散数据
2.TokyoTyrant
持久性的键值存储
用来处理需要持久保存,高速处理的数据
具有非常快的处理速度
用于不需要定期清除的数据
使用一致性散列(Consistent Hashing)算法来分散数据
3.Redis
兼具Memcached和Tokyo Tyrant优势的
键值存储擅长处理数组类型的数据
具有非常快的处理速度
可以高速处理时间序列的数据,易于处理集合运算
拥有很多可以进行原子操作的方法
使用一致性散列(Consistent Hashing)算法来分散数据
4.MongoDB
面向无需定义表结构的文档数据
具有非常快的处理速度
通过BSON的形式可以保存和查询任何类型的数据
无法进行JOIN处理,但是可以通过嵌入(embed)来实现同样的功能
使用sharding(范围分割)算法来分散数据