Microsoft 图像BERT,基于大规模图文数据的跨模态预训练
视觉语言任务是当今自然语言处理(NLP)和计算机视觉领域的热门话题。大多数现有方法都基于预训练模型,这些模型使用后期融合方法融合下游任务的多模态输入。然而,这种方法通常需要在训练期间进行特定的数据注释,并且对于许多多模态任务来说,满足这一要求仍然非常困难和昂贵。Microsoft研究人员最近发表的一篇论文提出了一种新的视觉语言预训练模型,用于图像 - 文本联合嵌入,ImageBERT,它在MSCOCO(图像检索任务)和Flickr 30k(文本检索)数据集上都实现了SOTA性能。
与Google的BERT(来自变压器的双向编码器表示)语言模型一样,ImageBERT是基于Transformer的。它采用不同的模态(文本和视觉标记)作为输入,通过嵌入层编码到不同的嵌入中。然后将这些嵌入输入多层双向自注意力转换器,该转换器训练跨模态转换器来建模图像和文本之间的关系。
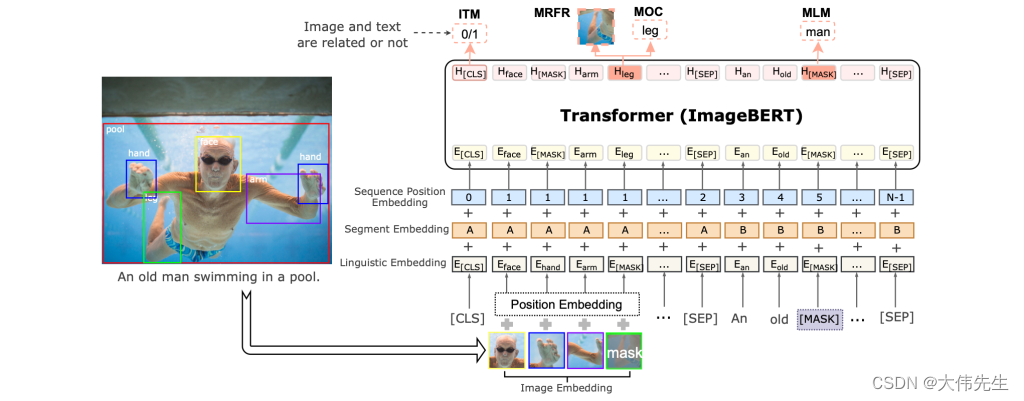
ImageBERT模型架构
数据的数量和质量对于视觉语言任务的跨模型预训练至关重要,因此研究人员开发了一种弱监督方法,用于从互联网收集大规模图像文本数据,以提高预训练性能。他们的大规模weAk监督图像文本(LAIT)数据集包括10万个视觉语言对(图像+描述),并用于预训练ImageBERT模型。
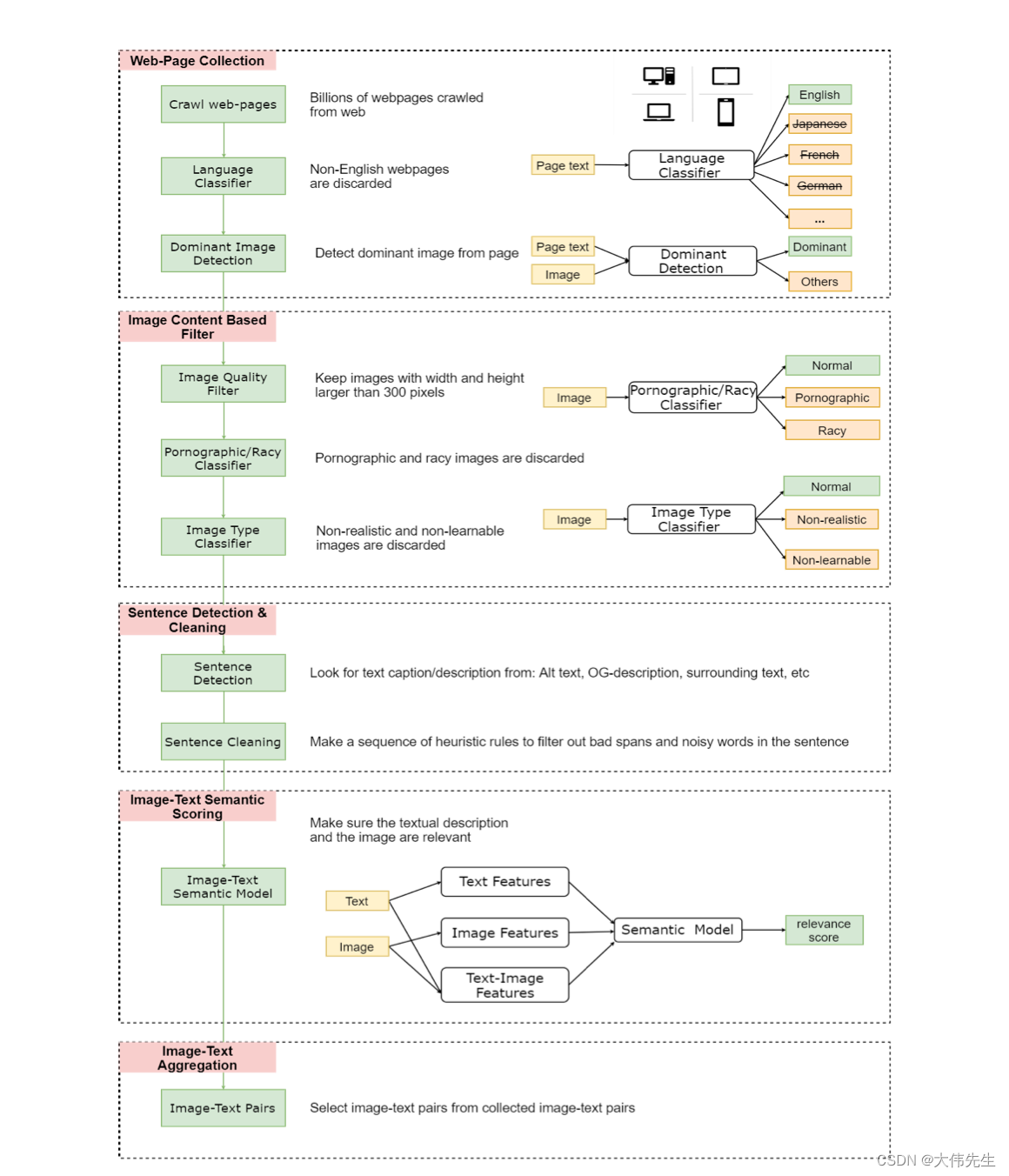
弱监督数据收集管道
在LAIT之后,研究人员在第二阶段对公共数据集概念标题(最广泛使用的图像文本预训练数据)和SBU标题(SBU标题照片数据集)对模型进行了预训练。该模型同时在研究人员设计的四个任务上进行预训练,以对文本和视觉内容及其相互关系进行建模:
**任务1:**掩蔽语言建模(MLM) –这与BERT培训中的MLM相同。它提出了一个新的预训练目标,并能够训练深度双向嵌入。
**任务2:**屏蔽对象分类 (MOC) – MLM 任务的扩展。
**任务3:**屏蔽区域特征回归 (MRFR) – 与 MOC 类似,此任务还通过更精确的对象特征预测工作对视觉内容进行建模。
**任务4:**图像文本匹配 (ITM) – 学习图像-文本对齐的任务。
实验结果表明,多阶段预训练方法比单阶段预训练方法取得了更好的效果。研究人员还进行了微调,并将预训练的ImageBERT模型与SOTA方法在图像检索和文本检索任务上进行了比较,其中ImageBERT在MSCOCO和Flickr30k数据集上都获得了最佳结果。
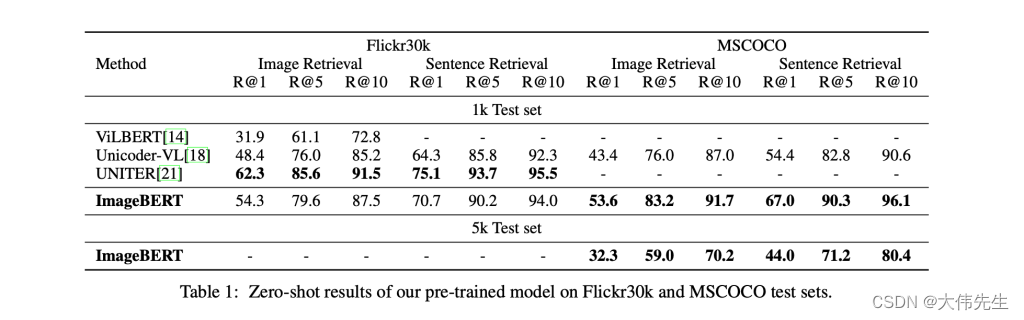
研究人员希望他们的新模型和数据集能够进一步推进跨模态预训练的研究和发展。
论文ImageBERT:使用大规模弱监督图像文本数据的跨模态预训练发表在arXiv上。