说说Flink on yarn的启动流程
分析&回答
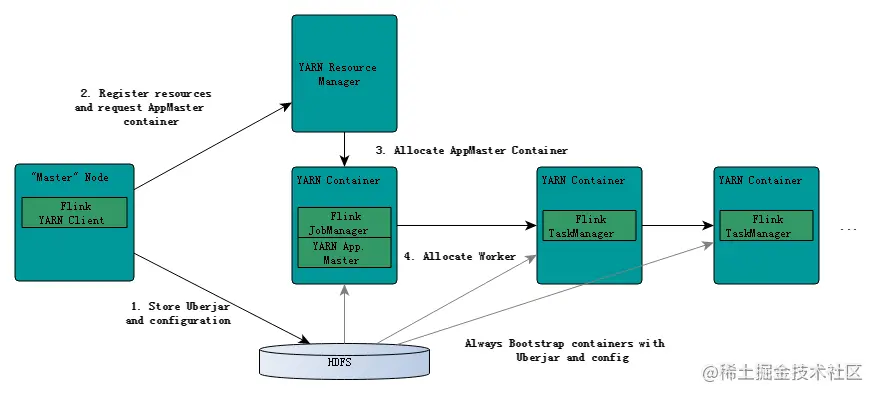
核心流程
- FlinkYarnSessionCli 启动的过程中首先会检查Yarn上有没有足够的资源去启动所需要的container,如果有,则上传一些flink的jar和配置文件到HDFS,这里主要是启动AM进程和TaskManager进程的相关依赖jar包和配置文件。
- 接着yarn client会首先向RM申请一个container来作为ApplicationMaster(YarnApplicationMasterRunner进程),然后RM会通知其中一个NM启动这个container,被分配到启动AM的NM会首先去HDFS上下载第一步上传的jar包和配置文件到本地,接着启动AM;在这个过程中会启动JobManager,因为JobManager和AM在同一进程里面,它会把JobManager的地址重新作为一个文件上传到HDFS上去,TaskManager在启动的过程中也会去下载这个文件获取JobManager的地址,然后与其进行通信;AM还负责Flink的web 服务,Flink里面用到的都是随机端口,这样就允许了用户能够启动多个yarn session。
- AM 启动完成以后,就会向AM申请container去启动TaskManager,启动的过程中也是首先从HDFS上去下载一些包含TaskManager(yarn模式的话这里就是YarnTaskManager )主类 的jar和启动过程依赖的配置文件,如JobManager地址所在的文件,然后利用java cp的方式去启动YarnTaskManager ,一旦这些准备好,就可以接受任务了。 这个和spark on yarn的yarn cluster模式其实差不多,也是分为两个部分,一个是准备工人和工具(spark是启动sc的过程,flink是初始化ENV的过程),另外一个就是给工人分配具体工作(都是执行具体的操作,action什么的触发)。
简化表述
- 1.客户端执行启动脚本;
- 2.启动AppMaster;
- 3.启动Resource Manager & JobManager;
- 4.启动Node Manager & TaskManager;
- 5.集群启动完毕后与客户端的交互。
Flink 集群启动后架构图
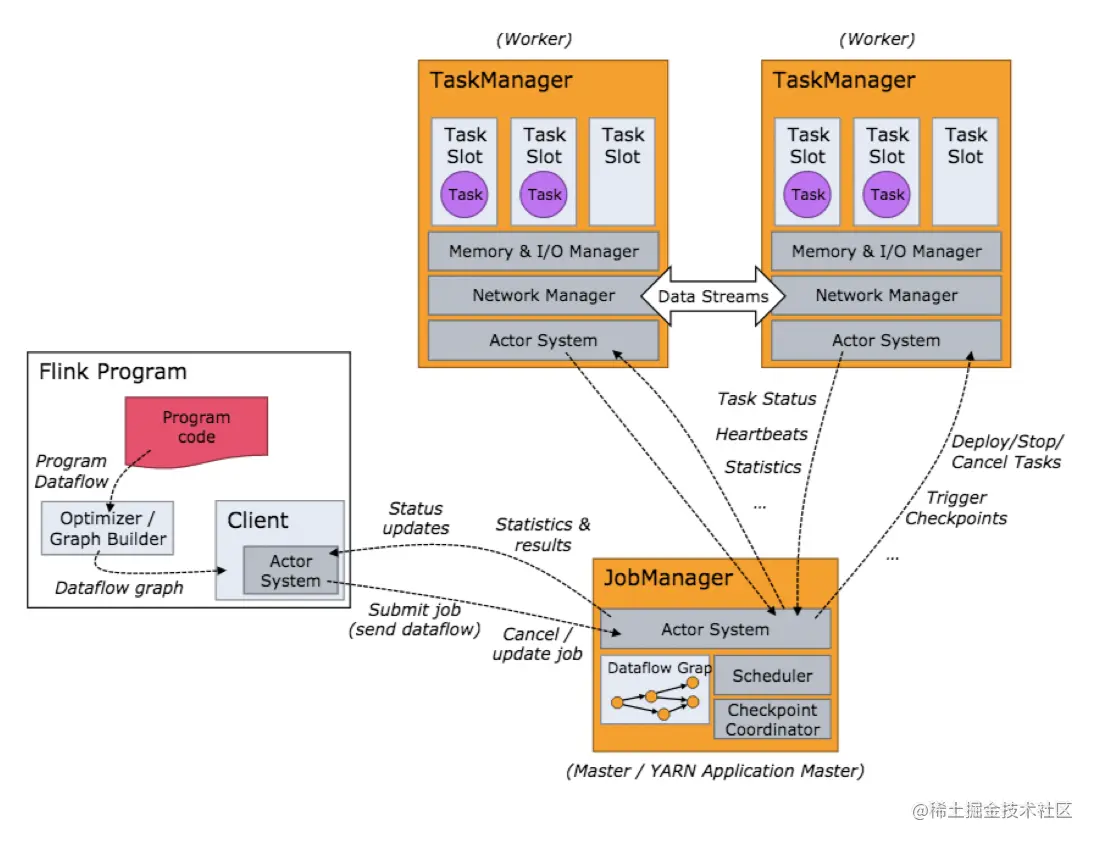
当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
- Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
- JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
- TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。 可以看到 Flink 的任务调度是多线程模型,并且不同Job/Task混合在一个 TaskManager 进程中。虽然这种方式可以有效提高 CPU 利用率,但是个人不太喜欢这种设计,因为不仅缺乏资源隔离机制,同时也不方便调试。类似 Storm 的进程模型,一个JVM 中只跑该 Job 的 Tasks 实际应用中更为合理。
反思&扩展
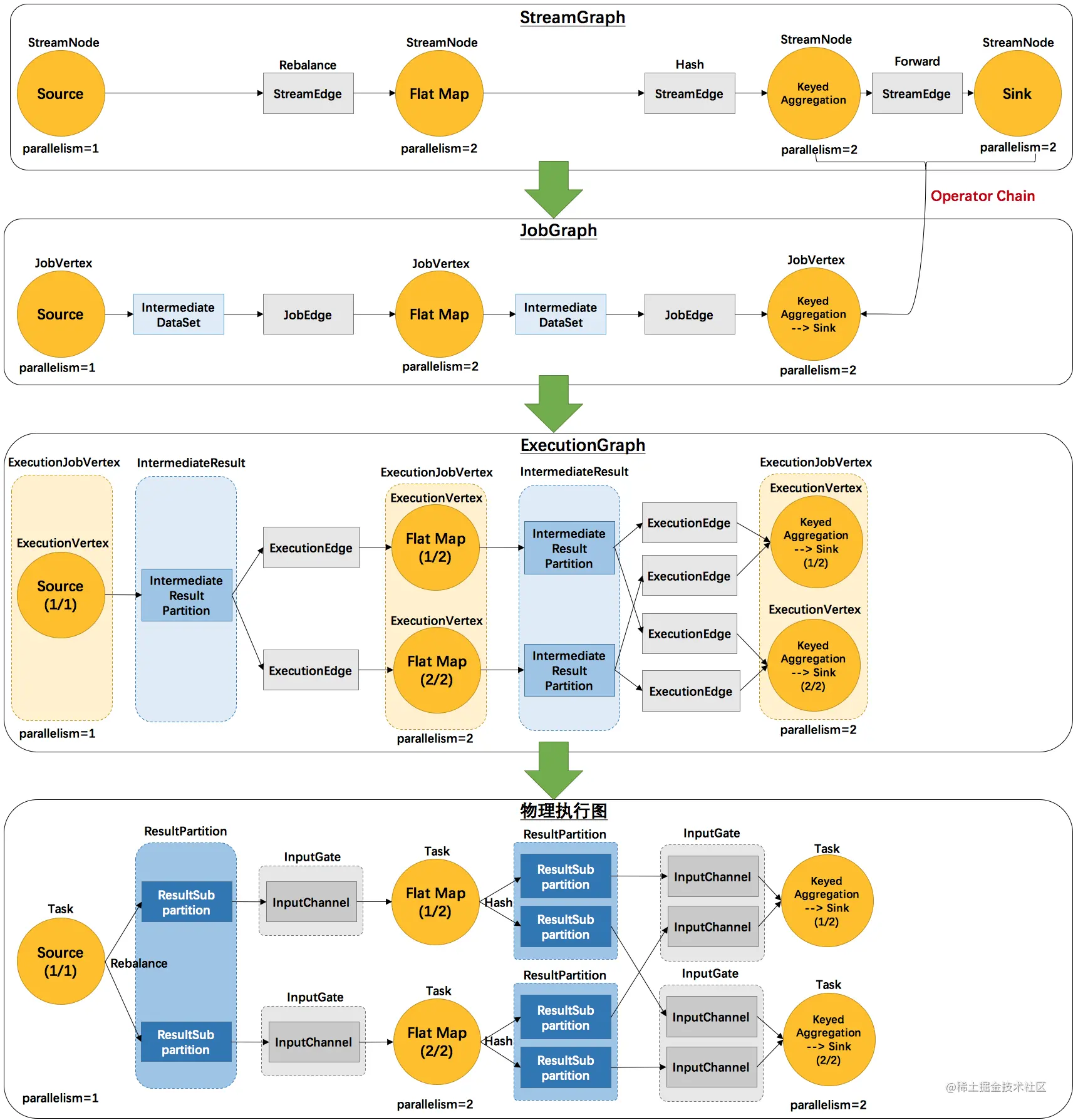
Flink 中的执行图可以分成四层
StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图
喵呜面试助手:一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!