kube-scheduler 架构概述
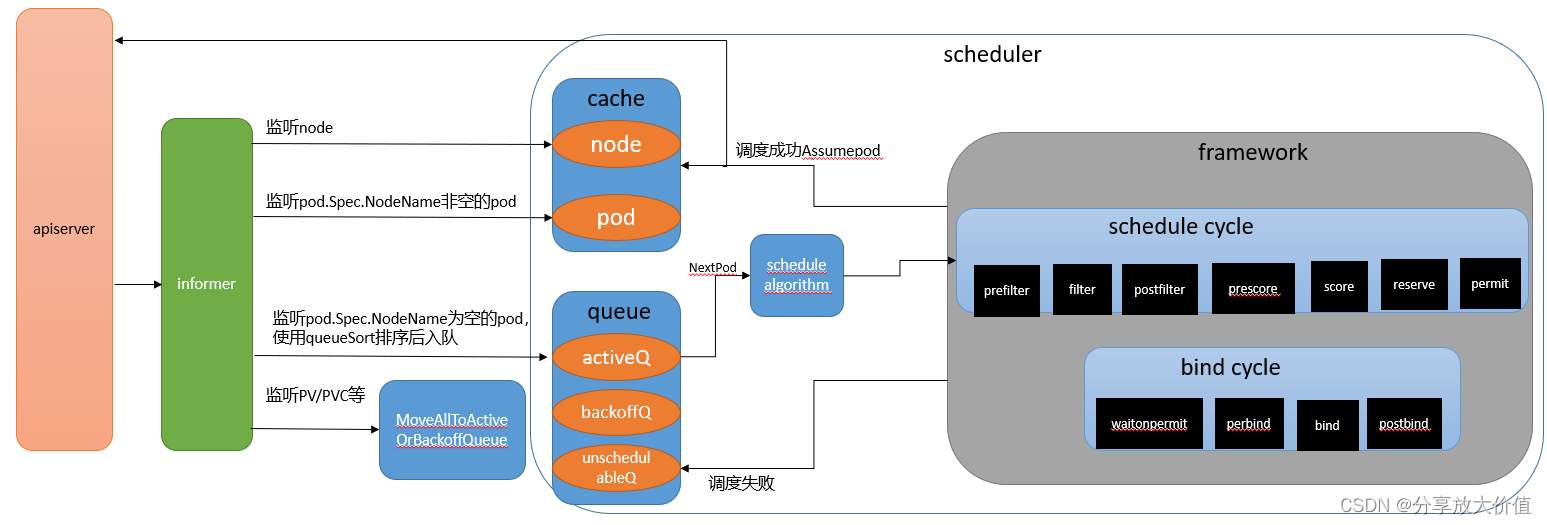
本文主要介绍一下kube-scheduler的架构,简要说明一下各个模块的作用,后面会单独详细分析每个模块。架构图如下
监听资源
kube-scheduler会通过client-go提供的informer机制监听如下几种k8s的资源变化,相关代码可参考: //pkg/scheduler/eventhandlers.go:addAllEventHandlers
a. Node资源
kube-scheduler的主要目的是给未调度的pod找到合适的node,所以kube-scheduler必须得知道所有的node信息,这里通过监听node资源的增删改事件将node信息保存到cache中
b. Pod资源
kube-scheduler的主要目的是给未调度的pod找到合适的node,所以kube-scheduler必须得监听pod资源,未调度的pod指的是pod.Spec.NodeName字段为空的pod,监听到此种pod后,将根据queueSort提供的排序方法进行排序后(按照pod优先级和创建时间),插入ActiveQ中,等待被调度。对于pod.Spec.NodeName字段不为空的pod,又分为两种情况,一种是在创建pod时,显式指定了此pod所在node,另一种情况是调度成功并且bind node成功的pod,对于这种pod将其加入cache中
c. PV/PVC等资源
这里主要是监听影响pod调度的资源,比如PV等pod需要的资源。如果这些资源有变化可能导致之前调度失败的pod成功,所以需要调用MoveAllToActiveOrBackoffQueue将不可调度队列中的pod移动到ActiveO或者BackoffQueue队列
cache
cache主要用来缓存从apiserver监听到的所有的node信息,及node上所有的pod,可参考代码://pkg/scheduler/internal/cache/cache.go。
之前看informer机制源码时,其内部也有cache,缓存的是监听的所有资源信息,包括node和pod,为什么这里要再搞一个cache?我想有两个原因:
a. informer里的cache保存的资源都是分开的,比如想获取某个node上的所有pod,必须遍历所有的pod找到属于这个node的pod。而这里的cache在资源变化时已经将pod按node保存了,所以查找速率更快
b. 这里的cache中node上的信息不仅包括已经成功运行的pod的资源,也包括那些调度成功,但正在bind阶段的pod资源,因为bind过程是异步进行的,schedule调度时必须考虑这些pod所占用的node资源
queue
主要包括三个队列,可参考代码://pkg/scheduler/internal/queue/scheduling_queue.go
a. activeQ
此队列中的pod是正在等待被调度的pod,并且是有序队列,pod优先级高(如果优先级相同,则先创建的pod)的在队列头
b. podBackoffQ
pod退避队列,此队列中的pod是调度失败的pod,等到退避时间到后就会被移动到activeQ,也是有序队列,根据退避时间排序
c. unschedulableQ
此队列保存的是尝试调度但失败的pod
framework
framework是一个调度框架,里面保存着每个扩展点上的插件。
schedulealgorithm
调度算法的目的是根据输入的node列表和pod信息,找到适合pod的node并返回,此过程中会调用framework的prefilter,filter,postfilter,prescore和score五个扩展点上的插件。
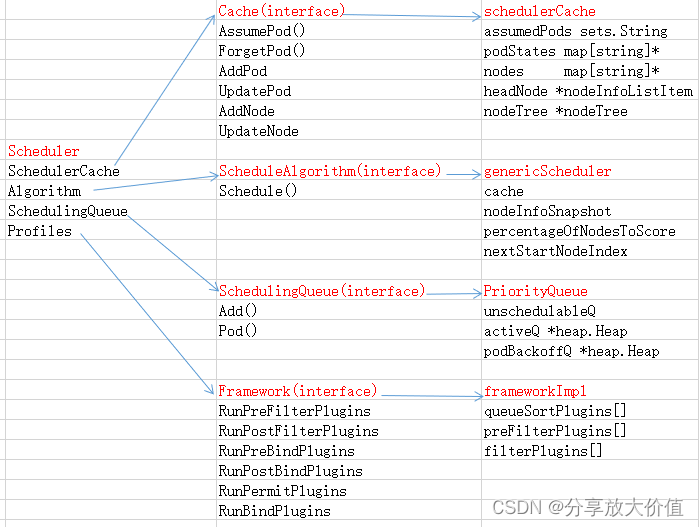
下图为调度器数据结构,Scheduler为调度器,其中包括了cache,queue,调度算法和framework等几个接口,每个接口都有其对应的实现