python数据预处理
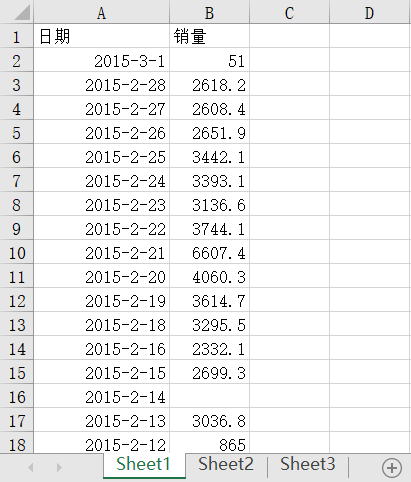
Ⅰ.数据源
Ⅱ.导入库
import pandas as pd
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# 避免画图时无法显示中文(中文部分以正方格显示)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# 显示所有的列,而不是以……显示
pd.set_option('display.max_columns', None)
# 显示所有的行,而不是以……显示
pd.set_option('display.max_rows', None)
# 不自动换行显示
pd.set_option('display.width', None)
Ⅲ.读取数据
# 读取文件
catering_sale=pd.read_excel('./data/catering_sale.xls')
Ⅳ.数据缺失值处理
# 判断是否存在缺失值
print(catering_sale.info(),'n')
# print(np.isnan(catering_sale).any(),'n')
catering_sale2=catering_sale.dropna(axis=0)
print(catering_sale2.info(),'n')
输出结果如下:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 201 entries, 0 to 200
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 日期 201 non-null datetime64[ns]
1 销量 200 non-null float64
dtypes: datetime64[ns](1), float64(1)
memory usage: 3.3 KB
None
<class 'pandas.core.frame.DataFrame'>
Int64Index: 200 entries, 0 to 200
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 日期 200 non-null datetime64[ns]
1 销量 200 non-null float64
dtypes: datetime64[ns](1), float64(1)
memory usage: 4.7 KB
None
观察可知,【销量】存在一个缺失值,本例将缺失值所在行进行删除处理
Ⅴ.数据特征分析
# 数据特征分析
y=catering_sale2.iloc[:,1]
print(catering_sale2.describe(),'n')
m=stats.mode(y)
r=np.max(y)-np.min(y)
cv=np.std(y)/np.mean(y)
n,(smin,smax),sm,sv,ss,sk=stats.describe(y)
print(f"统计量:{n},最小值:{smin},最大值:{smax},极差:{r},众数:{m},均值:{sm},方差:{sv},偏度:{ss},峰度:{sk},变异系数:{cv}n")
输出结果如下:
销量
count 200.000000
mean 2755.214700
std 751.029772
min 22.000000
25% 2451.975000
50% 2655.850000
75% 3026.125000
max 9106.440000
统计量:200,最小值:22.0,最大值:9106.44,极差:9084.44,众数:ModeResult(mode=array([2618.2]), count=array([2])),均值:2755.2146999999995,方差:564045.7182129748,偏度:3.0384935298149753,峰度:29.36759633770712,变异系数:0.2719025288924932
Ⅵ.数据异常值处理
# 画箱线图
y=np.array(y)
def boxplot(y,title):
plt.style.use('ggplot')
plt.subplots()
plt.boxplot(y,patch_artist=True,showmeans=True,showfliers=True,medianprops={'color':'yellow'},flierprops={'markerfacecolor':'red'},labels=[''])
plt.xlabel('销量')
plt.text(1.05,3850,'上边缘')
plt.text(1.05,1780,'下边缘')
plt.text(1.1,3000,'上四分位数Q3')
plt.text(0.8,2600,'中位数Q2')
plt.text(1.1,2300,'下四分位数Q1')
plt.text(1.05,6500,'异常值')
plt.title(f'{title}箱线图')
plt.show()
# 计算上下四分位数
q1=np.quantile(y,q=0.25)
q3=np.quantile(y,q=0.75)
# 异常值判断标准,1.5倍的四分位差 计算上下须对应的值
low_quantile=q1-1.5*(q3-q1)
high_quantile=q3+1.5*(q3-q1)
print(f'下四分位数Q1:{q1},上四分位数Q3:{q3},下边缘:{low_quantile},上边缘:{high_quantile}n')
y2=[]
for i in y:
if i>high_quantile:
i=high_quantile
y2.append(i)
elif i<low_quantile:
i=low_quantile
y2.append(i)
else:
y2.append(i)
boxplot(y,title='异常值处理前')
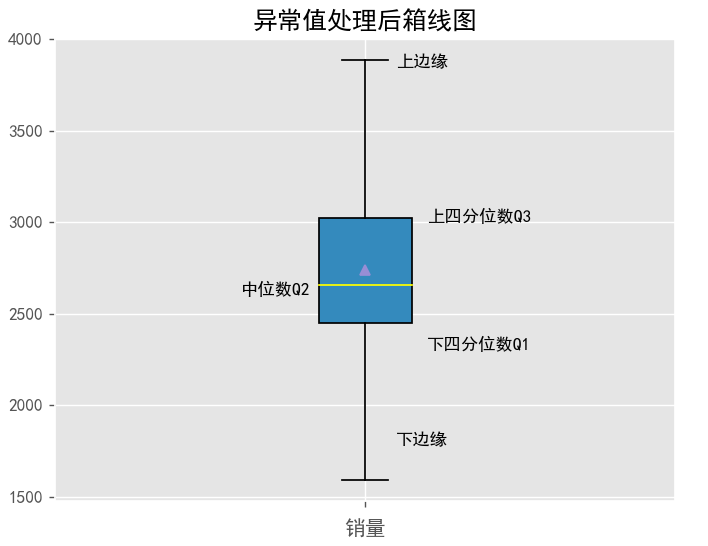
boxplot(y2,title='异常值处理后')
输出结果如下:
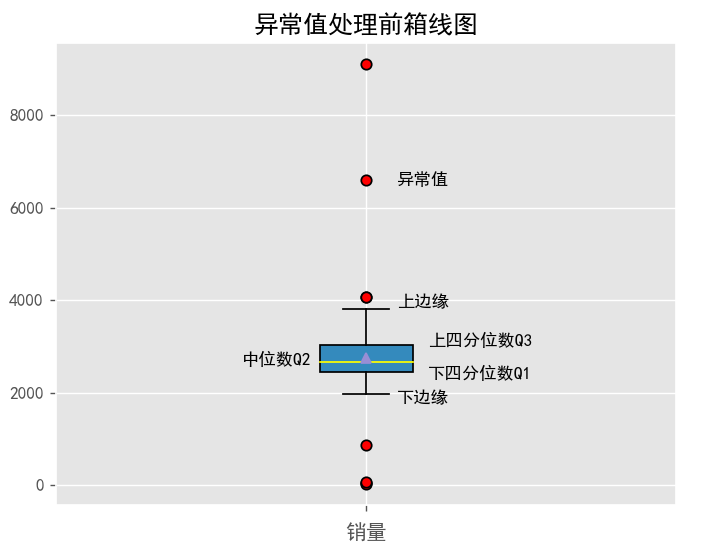
下四分位数Q1:2451.975,上四分位数Q3:3026.125,下边缘:1590.7499999999998,上边缘:3887.3500000000004
观察可知,箱线图上下边缘存在异常值,本例通过四分位法对异常值进行处理,即:超出上边缘的异常值让其落在上边缘,低于下边缘的异常值让其落在下边缘
输出结果如下:
Ⅶ.数据标准化/归一化处理
# 标准化处理
catering_sale_all=pd.read_excel('./data/catering_sale_all.xls',index_col=0)
# 方法一:归一化处理
normalization_data1=MinMaxScaler().fit_transform(catering_sale_all)
normalization_data1=[[round(j,2) for j in normalization_data1[i]] for i in range(len(normalization_data1))]
normalization_data1=np.array(normalization_data1)
# 方法二:标准化处理
normalization_data2=StandardScaler().fit_transform(catering_sale_all)
normalization_data2=[[round(j,2) for j in normalization_data2[i]] for i in range(len(normalization_data2))]
normalization_data2=np.array(normalization_data2)
print(f'方法一:归一化处理:n{normalization_data1}n方法二:标准化处理:n{normalization_data2}')
输出结果如下:
方法一:归一化处理:
[[1. 0.1 0.4 1. 0.9 0.83 0.94 0.45 0.64 1. ]
[0.57 1. 1. 0.48 0.5 0.58 1. 0.73 1. 0.39]
[0.5 0.3 0.8 0.48 0.4 0. 0.33 0.55 0.64 0.22]
[0.43 0.1 0.2 0. 0.6 0.5 0.44 0.73 1. 0.39]
[0.07 0.5 0.9 0.24 0.8 0.58 0.89 0.55 0.91 0.43]
[0.71 0.5 0.9 0.62 0.4 0.5 0.61 0.55 0.18 0.22]
[0.43 0.2 0.9 0.24 0.1 0.33 0.5 0.27 0.64 0.13]
[0.43 0.7 0.9 0.14 0.3 0.42 0.28 0.64 0.73 0.04]
[0.21 0.3 0.4 0. 0.1 0.08 0.22 0. 0.36 0.26]
[0.43 0.6 0.9 0.14 0.4 0.33 0.28 0.36 0.45 0.22]
[0.21 0.2 0.4 0.29 0. 0.33 0.39 0. 0. 0.26]
[0.14 0.4 0. 0.19 0.4 0.5 0.78 0.36 0.91 0.22]
[0.43 0.2 0.7 0.29 0.7 0.42 0.72 0.36 0.55 0.48]
[0.5 0.3 0.6 0.14 1. 0.83 0.83 0.36 0.09 0.43]
[0.71 0.7 0.8 0.33 0.5 0.67 0.39 0.64 0.55 0.48]
[0.07 0.3 0.8 0.38 0.5 0.33 0.5 0.09 0.73 0.3 ]
[0.21 0.7 0.6 0.29 0.7 0.08 0.39 0.82 0.27 0.39]
[0.43 1. 0. 0.43 0.3 0.5 0. 0. 0.82 0.17]
[0. 0.5 0.9 0.48 0.9 0.42 0.67 0. 0.73 0.3 ]
[0.36 0.2 0.5 0.81 0.1 0.75 0.39 0.18 0.45 0.3 ]
[0.57 0.1 0.7 0.24 0.3 0.42 0.44 0.18 0.64 0.22]
[0.57 0.1 0.1 0.57 0.3 0.92 0.72 0.18 0.27 0.17]
[0.07 0.2 0.6 0.19 0.2 0.58 0.44 0.64 0.36 0.04]
[0.29 0. 0.2 0.19 0.8 1. 0.28 0.64 0.55 0. ]
[0.36 0.3 0.8 0.52 0.4 0.67 0.33 0.64 0.64 0.09]
[0.07 0.5 0.8 0.29 0.3 0.42 0.39 0.45 0.64 0.3 ]
[0.21 0.2 0.3 0.38 0.3 0.33 0.44 1. 0.64 0.3 ]
[0.36 0. 0.7 0.33 0.4 0.67 0.39 0.45 0.64 0.22]
[0.36 0.1 0.3 0.29 0.2 0.08 0.28 0.55 0.27 0.22]]
方法二:标准化处理:
[[ 2.81 -0.95 -0.64 3.05 1.77 1.42 1.93 0.11 0.3 3.89]
[ 0.9 2.41 1.39 0.62 0.23 0.4 2.17 1.15 1.74 0.59]
[ 0.58 -0.21 0.71 0.62 -0.16 -1.98 -0.68 0.45 0.3 -0.36]
[ 0.26 -0.95 -1.32 -1.59 0.61 0.06 -0.2 1.15 1.74 0.59]
[-1.33 0.54 1.05 -0.49 1.38 0.4 1.69 0.45 1.38 0.82]
[ 1.54 0.54 1.05 1.28 -0.16 0.06 0.51 0.45 -1.5 -0.36]
[ 0.26 -0.58 1.05 -0.49 -1.32 -0.62 0.03 -0.58 0.3 -0.83]
[ 0.26 1.29 1.05 -0.93 -0.55 -0.28 -0.92 0.8 0.66 -1.3 ]
[-0.69 -0.21 -0.64 -1.59 -1.32 -1.64 -1.15 -1.62 -0.78 -0.12]
[ 0.26 0.92 1.05 -0.93 -0.16 -0.62 -0.92 -0.24 -0.42 -0.36]
[-0.69 -0.58 -0.64 -0.27 -1.7 -0.62 -0.44 -1.62 -2.22 -0.12]
[-1.01 0.17 -2. -0.71 -0.16 0.06 1.22 -0.24 1.38 -0.36]
[ 0.26 -0.58 0.37 -0.27 1. -0.28 0.98 -0.24 -0.06 1.06]
[ 0.58 -0.21 0.04 -0.93 2.15 1.42 1.46 -0.24 -1.86 0.82]
[ 1.54 1.29 0.71 -0.05 0.23 0.74 -0.44 0.8 -0.06 1.06]
[-1.33 -0.21 0.71 0.18 0.23 -0.62 0.03 -1.28 0.66 0.11]
[-0.69 1.29 0.04 -0.27 1. -1.64 -0.44 1.49 -1.14 0.59]
[ 0.26 2.41 -2. 0.4 -0.55 0.06 -2.1 -1.62 1.02 -0.59]
[-1.65 0.54 1.05 0.62 1.77 -0.28 0.74 -1.62 0.66 0.11]
[-0.05 -0.58 -0.3 2.16 -1.32 1.08 -0.44 -0.93 -0.42 0.11]
[ 0.9 -0.95 0.37 -0.49 -0.55 -0.28 -0.2 -0.93 0.3 -0.36]
[ 0.9 -0.95 -1.66 1.06 -0.55 1.75 0.98 -0.93 -1.14 -0.59]
[-1.33 -0.58 0.04 -0.71 -0.93 0.4 -0.2 0.8 -0.78 -1.3 ]
[-0.37 -1.33 -1.32 -0.71 1.38 2.09 -0.92 0.8 -0.06 -1.54]
[-0.05 -0.21 0.71 0.84 -0.16 0.74 -0.68 0.8 0.3 -1.07]
[-1.33 0.54 0.71 -0.27 -0.55 -0.28 -0.44 0.11 0.3 0.11]
[-0.69 -0.58 -0.98 0.18 -0.55 -0.62 -0.2 2.18 0.3 0.11]
[-0.05 -1.33 0.37 -0.05 -0.16 0.74 -0.44 0.11 0.3 -0.36]
[-0.05 -0.95 -0.98 -0.27 -0.93 -1.64 -0.92 0.45 -1.14 -0.36]]
Ⅷ.数据相关性分析
# 相关性分析
pearson=catering_sale_all.corr(method='pearson')
print('相关性矩阵:n',pearson)
y2=catering_sale_all.iloc[:,1:]
# 相关性矩阵散点图
# sns.pairplot(y2,kind='reg',diag_kind='hist')
# plt.title('相关性矩阵散点图')
# plt.show()
# 相关性矩阵热力图
sns.heatmap(pearson,square=True,annot=True)
plt.title('相关性矩阵热力图')
plt.show()
输出结果如下:
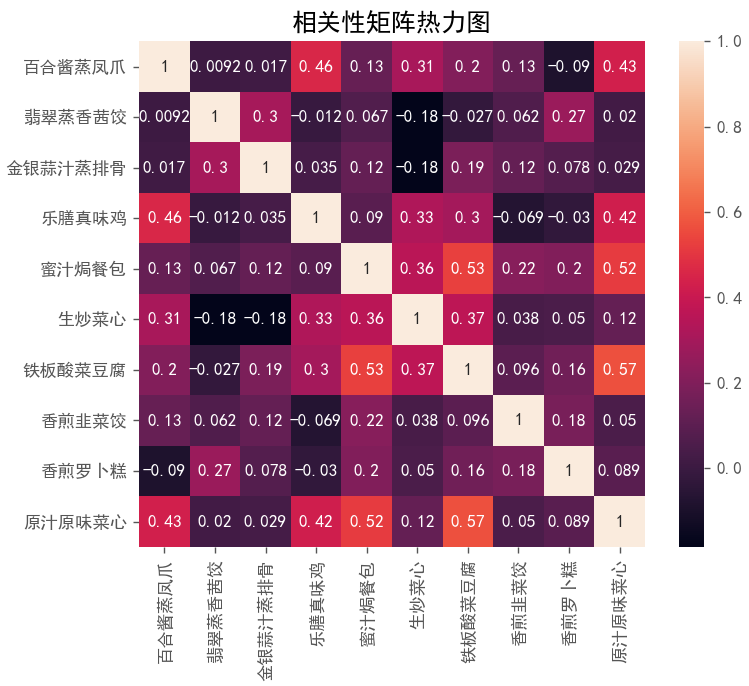
相关性矩阵:
百合酱蒸凤爪 翡翠蒸香茜饺 金银蒜汁蒸排骨 乐膳真味鸡 蜜汁焗餐包 生炒菜心 铁板酸菜豆腐 香煎韭菜饺 香煎罗卜糕 原汁原味菜心
百合酱蒸凤爪 1.000000 0.009206 0.016799 0.455638 0.126700 0.308496 0.204898 0.127448 -0.090276 0.428316
翡翠蒸香茜饺 0.009206 1.000000 0.304434 -0.012279 0.066560 -0.180446 -0.026908 0.062344 0.270276 0.020462
金银蒜汁蒸排骨 0.016799 0.304434 1.000000 0.035135 0.122710 -0.184290 0.187272 0.121543 0.077808 0.029074
乐膳真味鸡 0.455638 -0.012279 0.035135 1.000000 0.089602 0.325462 0.297692 -0.068866 -0.030222 0.421878
蜜汁焗餐包 0.126700 0.066560 0.122710 0.089602 1.000000 0.361068 0.528772 0.219578 0.200550 0.516849
生炒菜心 0.308496 -0.180446 -0.184290 0.325462 0.361068 1.000000 0.369787 0.038233 0.049898 0.122988
铁板酸菜豆腐 0.204898 -0.026908 0.187272 0.297692 0.528772 0.369787 1.000000 0.095543 0.157958 0.567332
香煎韭菜饺 0.127448 0.062344 0.121543 -0.068866 0.219578 0.038233 0.095543 1.000000 0.178336 0.049689
香煎罗卜糕 -0.090276 0.270276 0.077808 -0.030222 0.200550 0.049898 0.157958 0.178336 1.000000 0.088980
原汁原味菜心 0.428316 0.020462 0.029074 0.421878 0.516849 0.122988 0.567332 0.049689 0.088980 1.000000