基于 ACK Fluid 的混合云优化数据访问(五):自动化跨区域中心数据分发
作者:车漾
前文回顾:
本系列将介绍如何基于 ACK Fluid 支持和优化混合云的数据访问场景,相关文章请参考:
-基于 ACK Fluid 的混合云优化数据访问(一):场景与架构
-基于 ACK Fluid 的混合云优化数据访问(二):搭建弹性计算实例与第三方存储的桥梁
-基于 ACK Fluid 的混合云优化数据访问(三):加速第三方存储的读访问,降本增效并行
-基于 ACK Fluid 的混合云优化数据访问(四):将第三方存储目录挂载到 Kubernetes,提升效率和标准化
在之前的文章中,我们讨论了混合云场景下 Kubernetes 与数据相结合的 Day 1:解决数据接入的问题,实现云上计算和线下存储的连接。在此基础上,ACK Fluid 进一步解决了数据访问的成本和性能问题。而进入 Day 2,当用户真的在生产环境使用该方案时,最主要的挑战就是运维側如何处理多区域集群的数据同步。
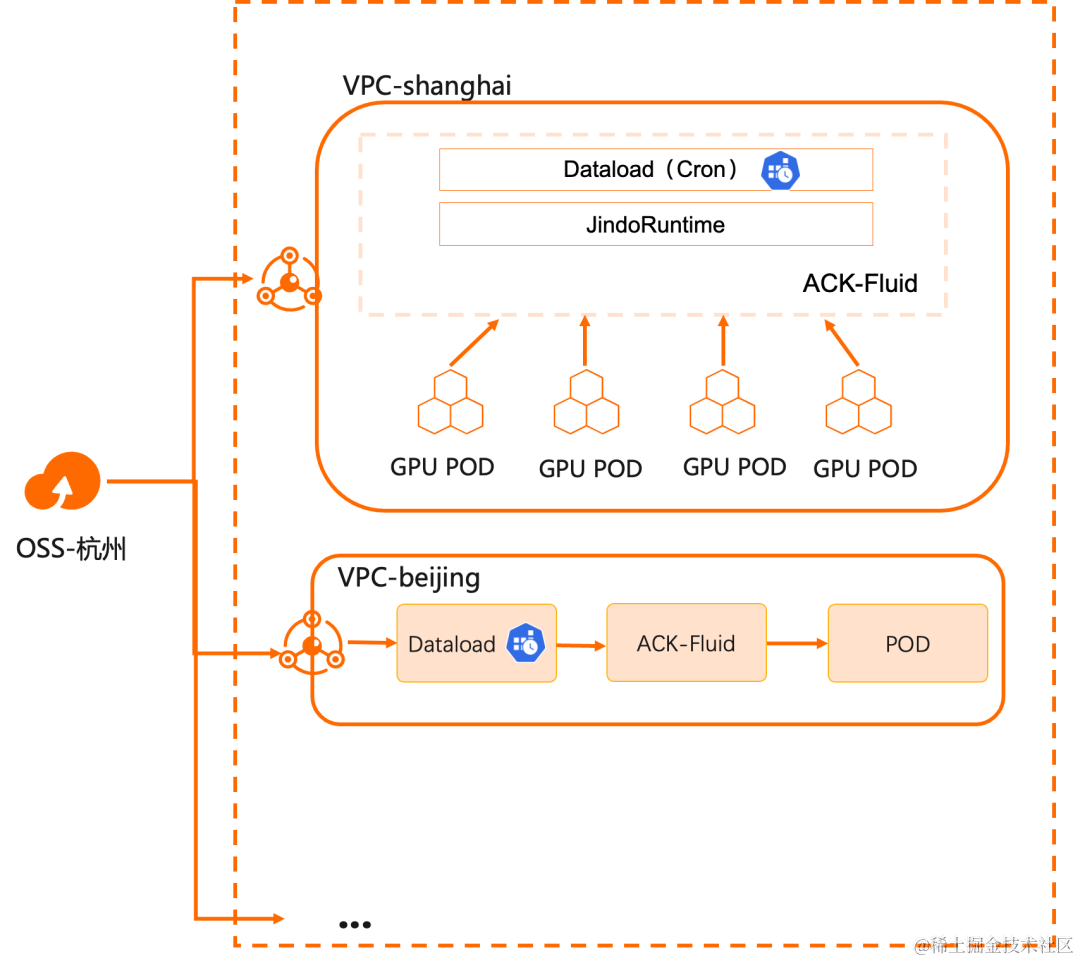
概述
许多企业出于性能、安全、稳定性和资源隔离的目的,会在不同区域建立多个计算集群。而这些计算集群需要远程访问唯一中心化的数据存储。比如随着大语言模型的逐渐成熟,基于其的多区域推理服务也逐渐成为各个企业需要支持的能力,就是这个场景的具体实例,它有不小的挑战:
- 多计算集群跨数据中心手动操作数据同步,非常耗时
- 以大语言模型为例,参数多文件大,数量多,管理复杂:不同业务选择不同的基础模型和业务数据,因此最终模型存在差异。
- 模型数据会根据业务输入不断做更新迭代,模型数据更新频繁
- 模型推理服务启动慢,拉取文件时间长:大型语言模型的参数规模相当巨大,体积通常很大甚至达到几百 GB,导致拉取到 GPU 显存的耗时巨大,启动时间非常慢。
- 模型更新需要所有区域同步更新,而在过载的存储集群上进行复制作业严重影响现有负载的性能。
ACK Fluid 除了提供通用存储客户端的加速能力,还提供了定时和触发式数据迁移和预热能力,简化数据分发的复杂度。
- 节省网络和计算成本: 跨区流量成本大幅降低,计算时间明显缩短,少量增加计算集群成本;并且可以通过弹性进一步优化。
- 应用数据更新大幅加速: 由于计算的数据访问在同一个数据中心或者可用区内完成通信,延时降低,且缓存吞吐并发能力可线性扩展。
- 减少复杂的数据同步操作: 通过自定义策略控制数据同步操作,降低数据访问争抢,同时通过自动化的方式降低运维复杂度。
演示
本演示介绍如何通过 ACK Fluid 的定时预热机制更新用户不同区域的计算集群可以访问的数据。
前提条件
- 已创建 ACK Pro 版集群,且集群版本为 1.18 及以上。具体操作,请参见创建 ACK Pro 版集群 [ 1] 。
- 已安装云原生 AI 套件并部署 ack-fluid 组件。重要:若您已安装开源 Fluid,请卸载后再部署 ack-fluid 组件。
- 未安装云原生 AI 套件:安装时开启 Fluid 数据加速。具体操作,请参见安装云原生 AI 套件 [ 2] 。
- 已安装云原生 AI 套件:在容器服务管理控制台 [ 3] 的云原生 AI 套件页面部署 ack-fluid。
- 已通过 kubectl 连接 Kubernetes 集群。具体操作,请参见通过 kubectl 工具连接集群 [ 4] 。
背景信息
准备好 K8s 和 OSS 环境的条件,您只需要耗费 10 分钟左右即可完成 JindoRuntime 环境的部署。
步骤一:准备 OSS Bucket 的数据
- 执行以下命令,下载一份测试数据。
$ wget https://archive.apache.org/dist/hbase/2.5.2/RELEASENOTES.md
- 将下载的测试数据上传到阿里云 OSS 对应的 Bucket 上,上传方法可以借助 OSS 提供的客户端工具 ossutil。具体操作,请参见安装 ossutil [ 5] 。
$ ossutil cp RELEASENOTES.md oss://<bucket>/<path>/RELEASENOTES.md
步骤二:创建Dataset和JindoRuntime
- 在创建 Dataset 之前,您可以创建一个 mySecret.yaml 文件来保存 OSS 的 accessKeyId 和 accessKeySecret。
创建 mySecret.yaml 文件的 YAML 样例如下:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
stringData:
fs.oss.accessKeyId: xxx
fs.oss.accessKeySecret: xxx
- 执行以下命令,生成 Secret。
$ kubectl create -f mySecret.yaml
- 使用以下 YAML 文件样例创建一个名为 dataset.yaml 的文件,且里面包含两部分:
- 创建一个 Dataset,描述远端存储数据集和 UFS 的信息。
- 创建一个 JindoRuntime,启动一个 JindoFS 的集群来提供缓存服务。
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
name: demo
spec:
mounts:
- mountPoint: oss://<bucket-name>/<path>
options:
fs.oss.endpoint: <oss-endpoint>
name: hbase
path: "/"
encryptOptions:
- name: fs.oss.accessKeyId
valueFrom:
secretKeyRef:
name: mysecret
key: fs.oss.accessKeyId
- name: fs.oss.accessKeySecret
valueFrom:
secretKeyRef:
name: mysecret
key: fs.oss.accessKeySecret
accessModes:
- ReadOnlyMany
---
apiVersion: data.fluid.io/v1alpha1
kind: JindoRuntime
metadata:
name: demo
spec:
replicas: 1
tieredstore:
levels:
- mediumtype: MEM
path: /dev/shm
quota: 2Gi
high: "0.99"
low: "0.8"
fuse:
args:
- -okernel_cache
- -oro
- -oattr_timeout=60
- -oentry_timeout=60
- -onegative_timeout=60
相关参数解释如下表所示:
| 参数 | 说明 |
|---|---|
| mountPoint | oss://<oss_bucket>/ 表示挂载UFS的路径,路径中不需要包含endpoint信息。 |
| fs.oss.endpoint | OSS Bucket的endpoint信息,公网或私网地址皆可。 |
| accessModes | 表示Dataset的访问模式。 |
| replicas | 表示创建JindoFS集群的Worker数量。 |
| mediumtype | 表示缓存类型。定义创建JindoRuntime模板样例时,JindoFS暂时支持HDD/SSD/MEM中的其中一种缓存类型。 |
| path | 表示存储路径,暂时只支持单个路径。当选择MEM做缓存时,需指定一个本地路径来存储Log等文件。 |
| quota | 表示缓存最大容量,单位GB。缓存容量可以根据UFS数据大小自行配置。 |
| high | 表示存储容量上限大小。 |
| low | 表示存储容量下限大小。 |
| fuse.args | 表示可选的fuse客户端挂载参数。通常与Dataset的访问模式搭配使用。当Dataset访问模式为ReadOnlyMany时,我们开启kernel_cache以利用内核缓存优化读性能。此时我们可以设置attr_timeout(文件属性缓存保留时间)、entry_timeout(文件名读取缓存保留时间)超时时间、negative_timeout(文件名读取失败缓存保留时间),默认均为7200s。当Dataset访问模式为ReadWriteMany时,我们建议使用默认配置。此时参数如下:- -oauto_cache- -oattr_timeout=0- -oentry_timeout=0- -onegative_timeout=0使用auto_cache以确保如果文件大小或修改时间发生变化,缓存就会失效。同时将超时时间都设置为0。 |
- 执行以下命令,创建 JindoRuntime 和 Dataset。
$ kubectl create -f dataset.yaml
- 执行以下命令,查看 Dataset 的部署情况。
$ kubectl get dataset
预期输出:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
demo 588.90KiB 0.00B 10.00GiB 0.0% Bound 2m7s
步骤三:创建支持定时运行的 Dataload
- 使用以下 YAML 文件样例创建一个名为 dataload.yaml 的文件。
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:
name: cron-dataload
spec:
dataset:
name: demo
namespace: default
policy: Cron
schedule: "*/2 * * * *" # Run every 2 min
相关参数解释如下表所示:
| 参数 | 说明 |
|---|---|
| dataset | 表示执行dataload的数据集name和namespace。 |
| policy | 表示执行策略,目前支持Once和Cron。这里创建定时dataload任务。 |
| shcedule | 表示触发dataload的策略。 |
scheule 使用以下 cron 格式:
# ┌───────────── 分钟 (0 - 59)
# │ ┌───────────── 小时 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周一;在某些系统上,7 也是星期日)
# │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
同时,cron 支持下列运算符:
- 逗号(,)表示列举,例如:1,3,4,7 * * * * 表示在每小时的 1、3、4、7 分时执行Dataload。
- 连词符(-)表示范围,例如:1-6 * * * * 表示每小时的 1 到 6 分钟内,每分钟都执行一次。
- 星号(*)代表任何可能的值。例如:在“小时域”里的星号等于是“每一个小时”。
- 百分号(%) 表示“每"。例如:*%10 * * * * 表示每 10 分钟执行一次。
- 斜杠 (/) 用于描述范围的增量。例如:*/2 * * * *表示每 2 分钟执行一次。
您也可以在这里查看更多信息。
Dataload 相关高级配置请参考如下配置文件:
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:
name: cron-dataload
spec:
dataset:
name: demo
namespace: default
policy: Cron # including Once, Cron
schedule: * * * * * # only set when policy is cron
loadMetadata: true
target:
- path: <path1>
replicas: 1
- path: <path2>
replicas: 2
相关参数解释如下表所示:
| 参数 | 说明 |
|---|---|
| policy | 表示dataload执行策略,包括[Once, Cron]。 |
| schedule | 表示cron使用的计划,只有policy为Cron时有效。 |
| loadMetadata | 表示在dataload前是否同步元数据。 |
| target | 表示dataload的目标,支持指定多个目标。 |
| path | 表示执行dataload的路径。 |
| replicas | 表示缓存的副本数。 |
- 执行以下命令创建 Dataload。
$ kubectl apply -f dataload.yaml
- 执行以下命令查看 Dataload 状态。
$ kubectl get dataload
预期输出:
NAME DATASET PHASE AGE DURATION
cron-dataload demo Complete 3m51s 2m12s
- 等待 Dataload 状态为 Complete 后,执行以下命令查看当前 dataset 状态。
$ kubectl get dataset
预期输出:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
demo 588.90KiB 588.90KiB 10.00GiB 100.0% Bound 5m50s
可以看出 oss 中文件已经全部加载到缓存。
步骤四:创建应用容器访问 OSS 中的数据
本文以创建一个应用容器访问上述文件以查看定时 Dataload 效果。
- 使用以下 YAML 文件样例,创建名为 app.yaml 的文件。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- mountPath: /data
name: demo-vol
volumes:
- name: demo-vol
persistentVolumeClaim:
claimName: demo
- 执行以下命令创建应用容器。
$ kubectl create -f app.yaml
- 等待应用容器就绪,执行以下命令查看 OSS 中的数据:
$ kubectl exec -it nginx -- ls -lh /data
预期输出:
total 589K
-rwxrwxr-x 1 root root 589K Jul 31 04:20 RELEASENOTES.md
- 为了验证 dataload 定时更新底层文件效果,我们在定时 dataload 触发前修改 RELEASENOTES.md 内容并重新上传。
$ echo "hello, crondataload." >> RELEASENOTES.md
重新上传该文件到 oss。
$ ossutil cp RELEASENOTES.md oss://<bucket-name>/<path>/RELEASENOTES.md
- 等待 dataload 任务触发。Dataload 任务完成时,执行以下命令查看 Dataload 作业运行情况:
$ kubectl describe dataload cron-dataload
预期输出:
...
Status:
Conditions:
Last Probe Time: 2023-07-31T04:30:07Z
Last Transition Time: 2023-07-31T04:30:07Z
Status: True
Type: Complete
Duration: 5m54s
Last Schedule Time: 2023-07-31T04:30:00Z
Last Successful Time: 2023-07-31T04:30:07Z
Phase: Complete
...
其中,Status 中 Last Schedule Time 为上一次 dataload 作业的调度时间,Last Successful Time 为上一次 dataload 作业的完成时间。
此时,可以执行以下命令查看当前 Dataset 状态:
$ kubectl get dataset
预期输出:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
demo 588.90KiB 1.15MiB 10.00GiB 100.0% Bound 10m
可以看出更新后的文件也已经加载到了缓存。
- 执行以下命令在应用容器中查看更新后的文件:
$ kubectl exec -it nginx -- tail /data/RELEASENOTES.md
预期输出:
<name>hbase.config.read.zookeeper.config</name>
<value>true</value>
<description>
Set to true to allow HBaseConfiguration to read the
zoo.cfg file for ZooKeeper properties. Switching this to true
is not recommended, since the functionality of reading ZK
properties from a zoo.cfg file has been deprecated.
</description>
</property>
hello, crondataload.
从最后一行可以看出,应用容器已经可以访问更新后的文件。
环境清理
当您不再使用该数据加速功能时,需要清理环境。
执行以下命令,删除 JindoRuntime 和应用容器。
$ kubectl delete -f app.yaml
$ kubectl delete -f dataset.yaml
总结
关于基于 ACK Fluid 的混合云优化数据访问的讨论先到这里告一段落,阿里云容器服务团队会和用户在这个场景下持续的迭代和优化,随着实践不断深入,这个系列也会持续更新。
相关链接:
[1] 创建 ACK Pro 版集群
https://help.aliyun.com/document_detail/176833.html#task-skz-qwk-qfb
[2] 安装云原生 AI 套件
https://help.aliyun.com/zh/ack/cloud-native-ai-suite/user-guide/deploy-the-cloud-native-ai-suite#task-2038811
[3] 容器服务管理控制台
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Fcs.console.aliyun.com%2F
[4] 通过 kubectl 工具连接集群
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/obtain-the-kubeconfig-file-of-a-cluster-and-use-kubectl-to-connect-to-the-cluster#task-ubf-lhg-vdb
[5] 安装 ossutil
https://help.aliyun.com/zh/oss/developer-reference/install-ossutil#concept-303829