SENet 学习
ILSVRC
是一个比赛,全称是ImageNet Large-Scale Visual Recognition Challenge,平常说的ImageNet比赛指的是这个比赛。
使用的数据集是ImageNet数据集的一个子集,一般说的ImageNet(数据集)实际上指的是ImageNet的这个子集,总共有1000类,每类大约有1000张图像。完整的 ImageNet,有大约1.2million的训练集,5万验证集,15万测试集。ILSVRC从2010年开始举办,到2017年是最后一届。ILSVRC-2012的数据集被用在2012-2014年的挑战赛中(VGG论文中提到)。ILSVRC-2010是唯一提供了test set的一年。
ImageNet可能是指整个数据集(15 million),也可能指比赛用的那个子集(1000类,大约每类1000张),也可能指ILSVRC这个比赛。需要根据语境自行判断。
12-17年期间在ImageNet比赛上提出了一些经典网络,比如AlexNet,ZFNet,VGG, GoogLeNet, ResNet,DenseNet,SENet。我之前的博文都有相应模型及其变体的介绍。
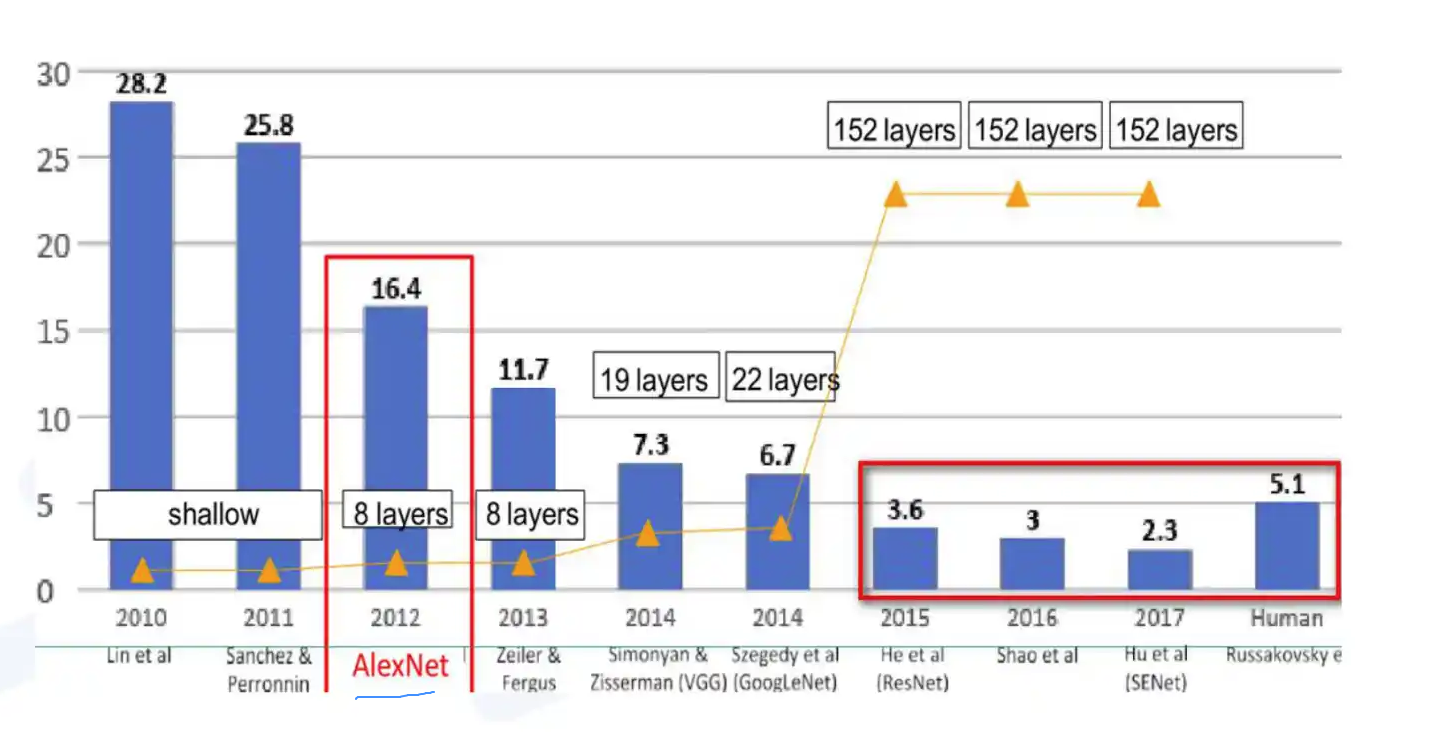
- 13 年 ZFNet
- 16 年 DenseNet
SENET简介
提出背景:卷积核通常被看做是在局部感受野上,在空间上和通道维度上同时对信息进行相乘求和的计算。现有网络很多都是主要在空间维度方面来进行特征的融合(如Inception的多尺度)。
通道维度的注意力机制:在常规的卷积操作中,输入信息的每个通道进行计算后的结果会进行求和输出,这时每个通道的重要程度是相同的。而通道维度的注意力机制,则通过学习的方式来自动获取到每个特征通道的重要程度(即feature map层的权重),以增强有用的通
道特征,抑制不重要的通道特征。
说起卷积对通道信息的处理,有人或许会想到逐点卷积,即kernel大小为1X1的常规卷积。与1X1卷积相比,SENet是为每个channel重新分配一个权重(即重要程度)。而1X1卷积只是在做channel的融合计算,顺带进行升维和降维,也就是说每个channel在计算时的重要程度是相同的。
SENet 模块

X经过一系列传统卷积得到U,对U先做一个Global Average Pooling,输出的1x1xC数据(即,上图梯形短边的白色向量),这个特征向量一定程度上可以代表之前的输入信息,论文中称之为Squeeze操作。
再经过两个全连接来学习通道间的重要性,用sigmoid限制到[0,1]的范围,这时得到的输出可以看作每个通道重要程度的权重(即上图梯形短边的彩色向量),论文中称之为Excitation操作。
最后,把这个1x1xC的权重乘到U的C个通道上,这时就根据权重对U的channles进行了重要程度的重新分配。
效果
- 与SE模块可以嵌入到现在几乎所有的网络结构中,而且都可以得到不错的效果提升,用过的都说好。
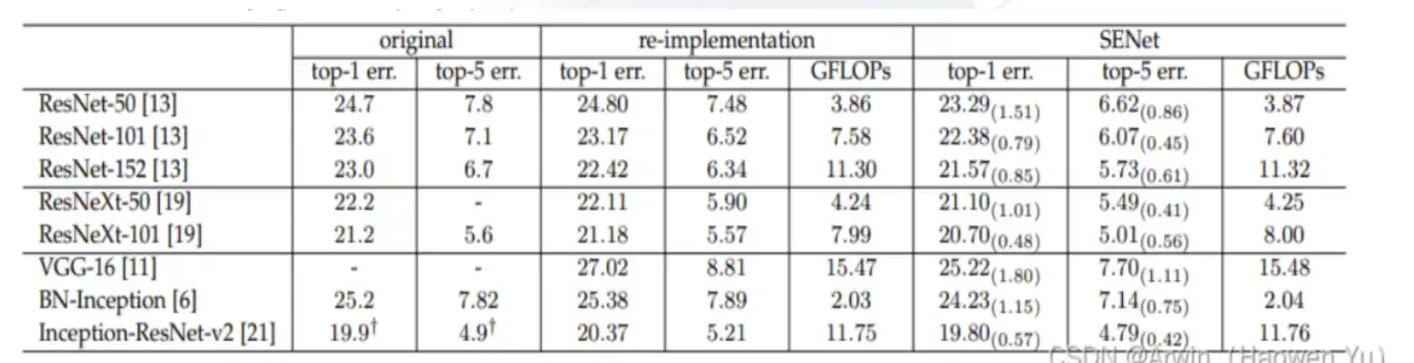
- 在大部分模型中嵌入SENet要比非SENet的准确率更高出1%左右,而计算复杂度上只是略微有提升,具体如下图所示。而且SE块会使训练和收敛更容易。CPU推断时间的基准测试:224×224的输入图 像,ResNet-50 164ms, SE-ResNet-50 167ms。
代码
class SqueezeExcite(nn.Module):
def __init__(self,
input_c: int, # block input channel
expand_c: int, # block expand channel
se_ratio: float = 0.25):
super(SqueezeExcite, self).__init__()
squeeze_c = int(input_c * se_ratio)
self.conv_reduce = nn.Conv2d(expand_c, squeeze_c, 1)
self.act1 = nn.SiLU() # alias Swish
self.conv_expand = nn.Conv2d(squeeze_c, expand_c, 1)
self.act2 = nn.Sigmoid()
def forward(self, x: Tensor):
scale = x.mean((2, 3), keepdim=True)
scale = self.conv_reduce(scale)
scale = self.act1(scale)
scale = self.conv_expand(scale)
scale = self.act2(scale)
return scale * x
总结
- SE block 可以理解为 channel维度上的注意力机制(即重分配通道上 feature map对后续计算的权重),与Stochastic Depth Net一样,本论文的贡献更像一种思想,而非模型。在之后的模型中,会经常看见SE block 的身影。例如,SKNet,MobileNet等等。