【数据库】详解数据库架构优化思路(两主架构、主从复制、冷热分离)
文章目录
1、为什么对数据库做优化
对数据库架构进行优化是为了提高数据库系统的性能、可扩展性、稳定性和可维护性。MySQL官方说:单表2000万数据,性能就达到瓶颈了,为了保证查询效率需要让每张表的大小得到控制。
再来说,为什么要提高查询效率呢?
除了普通的用户查询操作,增、删、改操作都包含查询操作,所以说,在一个应用中,查询操作是占比最高的,提高了查询效率,整体性能都会有所提升。
下面介绍几种常见方案
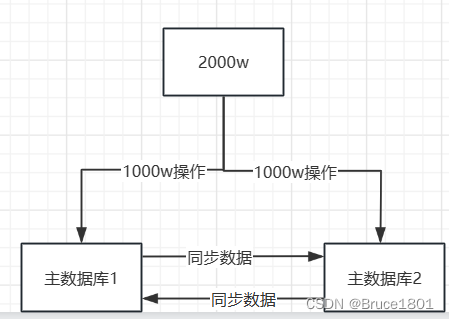
2、双主架构
它旨在提高数据库的可用性和负载均衡。在双主架构中,有两个主数据库实例(也称为主节点),每个主数据库都可以处理读写操作,而不仅仅是一个主数据库处理写操作,另一个主数据库处理读操作。
双主架构的工作方式如下:
- 数据同步: 两个主数据库之间需要建立数据同步机制,以保持数据的一致性。通常使用主从复制或双向复制来实现数据同步。这意味着任何一个主数据库上的写操作都会同步到另一个主数据库,从而保持数据的同步。
- 读写操作: 由于双主架构允许两个主数据库都处理读写操作,因此应用程序可以同时向这两个主数据库发送写操作和读操作。这可以减轻单个主数据库的负载。
- 故障切换: 如果其中一个主数据库发生故障,应用程序可以切换到另一个正常运行的主数据库,以保持系统的可用性。故障切换时,应该确保切换后的主数据库是最新的,并且可以快速地切换到备用主数据库。
双主架构的优势包括:
- 高可用性: 双主架构可以提供较高的可用性,因为即使一个主数据库发生故障,另一个主数据库仍然可以继续处理读写操作。
- 负载均衡: 两个主数据库可以分摊读写负载,从而提高数据库的性能和响应性能。
- 容错性: 如果一个主数据库出现问题,可以快速切换到另一个主数据库,从而减少系统的停机时间。
但是一般不用这种架构,原因是:
这种架构只是做了负载均衡,当写操作频繁时,会导致两个主数据库之间的数据同步压力增大。还有就是,现实中,一天可能就会产生1000w条数据,两个主数据库的单表会很大,影响读和写的性能。
3、主从复制
主从复制是一种常见的数据库复制技术,用于在多个MySQL数据库之间实现数据同步。在主从复制中,有一个主数据库(主节点)负责处理写操作,而一个或多个从数据库(从节点)将主数据库的数据复制到自身,用于处理读操作。
主从复制和双主架构都实现了负载均衡,但主从复制将读操作和写操作进行了分离,主数据库只承担写操作,从数据库只承担读操作,从而减轻主库的负载。对于频繁的写操作场景,将读操作分散到从库可以提高主库的性能,从而更好地处理写入请求。
主从复制的工作方式如下:
- 主库(主节点): 主库负责处理所有的写操作,如插入、更新和删除操作。主库上的写操作会被记录在二进制日志(binary log)中,这是一个记录数据库变更的日志文件。
- 从库(从节点): 从库通过读取主库的二进制日志,将主库的写操作逐一复制到自身。从库会保持与主库的数据一致性。从库可以用于处理查询操作,从而分担主库的负载。
主从复制的优势包括:
-
高可用性: 主从复制提供了一种冗余备份,如果主库发生故障,可以切换到从库以保持系统的可用性。
-
负载均衡: 从库可以用于处理读操作,从而减轻主库的负载,提高数据库的性能和响应性。
-
数据备份: 从库可以用于数据备份和恢复,因为它保留了与主库相同的数据。
主从复制的缺点
- 不满足强一致性
在MySQL中,主节点入库的时候可以选择采用某种方式来判定入库成功-
主节点入库以后,不管从节点是否同步成功,直接返回sql执行成功。 这种方式的特点就是快,但是不满足强一致性:
由于延迟和复制过程中的一些异常情况,从库和主库之间可能会出现数据不一致的问题。在复制链路上发生故障或者复制操作出现错误时,可能会导致从库数据与主库不一致。在存储一些不太敏感的数据(操作记录,日志)时,可以采用。 - 主节点入库以后,等所有的从节点都同步完成以后,才返回sql执行成功,当有一个从节点落库失败,返回执行失败。 这种方式可以满足强一致性,会比较慢。 对于存储敏感数据(跟钱有关),采用这种方式。
-
主节点入库以后,不管从节点是否同步成功,直接返回sql执行成功。 这种方式的特点就是快,但是不满足强一致性:
- 同步延迟问题
我刚提交了订单就去查询订单列表,这时主库刚入库,从库还没去主库同步。有可能看不到我新下的订单。还有可能是,我去申请退款并且已经显示了退款成功,我去查订单列表,由于从库还没有同步主库的数据,还会显示购买成功。
可以采用分布式全局锁,等查询从库的时候,如果退款状态是false(未退款),再去redis中查看分布式全局锁是否存在,如果存在就说明主库已经完成退款操作,只是从库还没同步过来,可以通知用户后台正在处理,请稍后再试。如果redis中不存在这个锁,就说明该订单的确未退款。
上述的主从复制对读、写操作进行了分离,将读操作平摊给了注册的从数据库,分担了主数据库的查询压力。但是没有解决表大小的问题,当单表的数据达到2000w后,主数据库的写操作(包含查询)达到瓶颈,从数据库的读操作也达到了瓶颈。针对表大下,于是有了下面的架构
就是将原本要装几千万数据的单表,进行拆分,如下图:
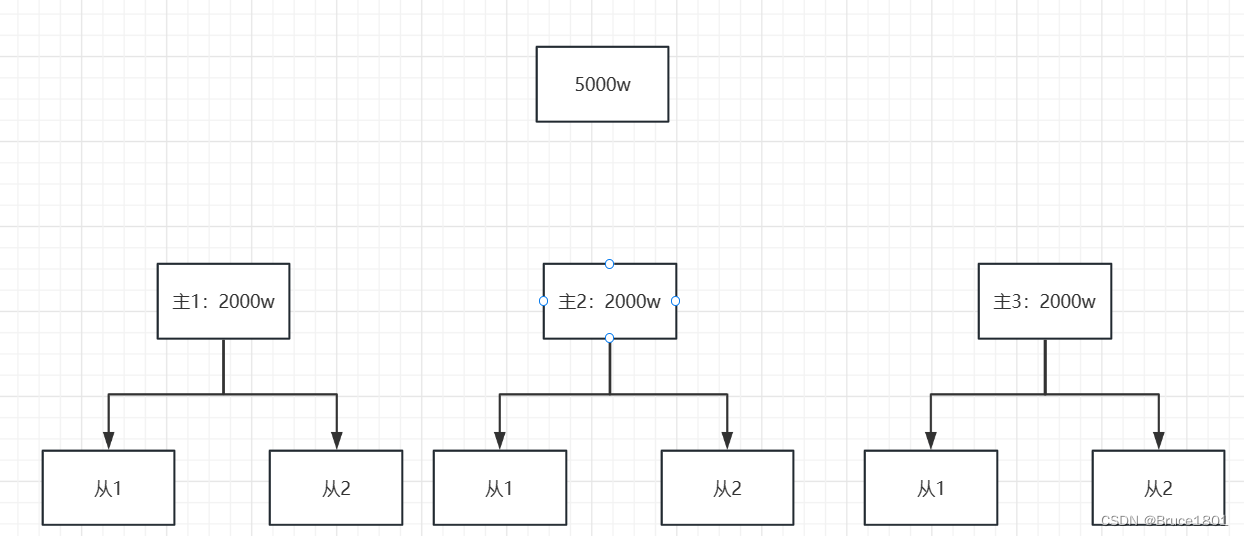
就是在执行入库或查询之前,可以通过数据的id%主库的数量,将操作均分到每个主从复制单位上。
当数据量过亿时,此时要是延续上面的方案,至少需要10个数据库,当数据量再多,过10亿时,至少需要100个数据库,这是不现实的。那么好(哈哈哈哈)下面就来介绍一下,当数据量破亿后,该如何优化。
4、冷热分离
表数据量增长速度快或数据量较大时, 我们就该考虑是否使用冷热分离解决方案了
冷数据
这是不经常被访问的数据(好比打入冷宫),通常是历史数据或者很少被查询的数据。冷数据不需要频繁的访问速度,因此可以存储在较慢但成本更低的存储介质中,如磁盘存储或者分布式文件系统。冷数据可以通过归档、压缩等手段来节省存储空间。
好比你要查询美团外卖的订单,你应该很少或者从不去查询1年以前或者更久远的订单吧。这种冷数据如果和其他表没有关联的话可以直接扔es,es在数据量1TB的情况下,单次查询可达到秒级。
热数据
这是经常被访问的数据,通常是最近的数据,或者是频繁被查询和更新的数据。热数据对于应用的性能至关重要,因此可以采用较快的存储介质,如内存或快速的闪存存储设备。对于关系型数据库,热数据可以存储在主数据库中。