使用OCR来解决自动化中图片验证
序言
由于在自动化测试过程中有的登录需要图形验证码,不管是webUI自动化测试,还是接口自动化测试如果登录接口返回的是一张图片出现这种情况我们则一般难以全自动化的去解决。
在传统方法中可能很多测试同学会如下几个方法去做:
1、自动化时直接叫开发同学关闭验证码验证环节?
2、直接叫开发同学弄个万能验证码?
3、redis有记录验证码相关信息不能直接调用redis API去查询?
4、公司有sms平台直接调用sms API获取验证码?
5、使用OCR相关模块(但仍有识别精度问题),在线API有调用次数限制?
以上几个方案你都做了哪些呢?其实以上方案都是可行的一种解决方案,但是不能总出现解决不了的问题都去找别人那么自己就得不到什么成长,我们测试就应该多尝试自己去解决自己的问题岂不更好?自己动手丰衣足食嘛。
接下来我要给大家讲解下如何使用高精度 OCR模型来解决上述问题。。。我要讲的是百度的PaddleOCR模型,百度在OCR文本识别方面确实下了不少功夫精确度可达98%,并且还有免费开源确实强大。接下来我会通过二到三章节来讲述使用AI来解决问题。
使用模型源码私有化部署
部署方式
paddleocr 部署方式有如下几种:
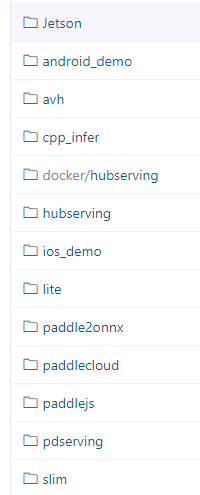
在PaddleOCR仓库的deploy中可以它给我们提供很多方式的部署,下面简单介绍下这些方法的部署
Jetson Jetson开发板部署(同时支持 Jetson NX、TX2、nano、AGX等系列硬件的部署。) 开发板可以自行去了解,如果玩过树莓派的同学应该就很了解这方面相关的了。
Android Demo Android系统上的一个demo应用
avh 使用TVM 在 Cortex(R)-M55 CPU 上运行 PaddleOCR 模型
ios Demo ios端上的demo
以上都是一些终端部署,还有端侧部署相关的 lite,slim这里就不描述了
采用hubserving来部署PaddleOCR模型
部署下面相关操作时建议使用docker容器,在docker容器中安装配置相关内容比较方便,以便以后不用了直接删除容器或镜像就可以了。docker容器教程可以查看我的公众号文章有教程。
下面来看看云端部署的
hubserving 使用hubserving进行部署在服务器端
docker/hubserving docker容器部署hubserving
pdserving 基于PaddleServing的部署
以上就是相关的部署方式,我们使用hubserving方式部署,将模型部署在服务器上可通过http请求来进行访问模型服务。
paddlocr 提供的部署教程https://gitee.com/paddlepaddle/PaddleOCR/tree/release/2.6/deploy/hubserving
首先需要在服务器安装Python 需要在3.6以上吧,不然会出现版本兼容问题导致一些依赖下载不成功,甚至编译不成功。
手动下载到本地上传服务器
然后你需要将paddleocr整个仓库下载下来
使用git下载
也可以使用git直接拉下来,这里需要安装了git和配置了私钥到gitee具体自行百度可以解决这里不细讲了。
git clone https://github.com/PaddlePaddle/PaddleOCR
拉取成功后,或者自行上传到服务器后解压压缩包得到一个文件夹

下载paddlehub
# paddlehub 需要 python>3.6.2
pip3 install paddlehub==2.1.0 --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
下载后终端输入 hub会出现如下命令则hub可以正常使用
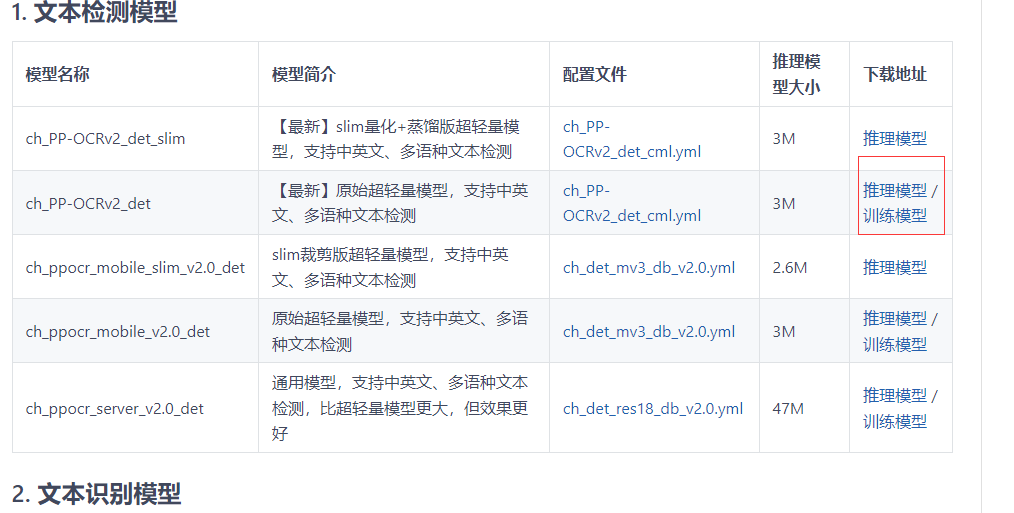
下载推理模型
安装服务模块前,需要准备推理模型并放到正确路径。默认使用的是PP-OCRv2模型,默认模型路径为:
检测模型:./inference/ch_PP-OCRv2_det_infer/
识别模型:./inference/ch_PP-OCRv2_rec_infer/
方向分类器:./inference/ch_ppocr_mobile_v2.0_cls_infer/
模型下载地址 https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.4/doc/doc_ch/models_list.md
在上面有很多不一样的模型,可以提供自己去选择尽量下载推理模型,如果你觉得模型精度不够需要自己再次训练模型就下载训练模型。
下载好后的模型文件需要存放在PaddleOCR/inference目录中

是需要解压后的的文件夹,不能是压缩包。
模型路径可在各模型的params.py中查看和修改。 更多模型可以从PaddleOCR提供的模型库下载,也可以替换成自己训练转换好的模型。
具体路径如ocr_cls模型
PaddleOCR/ deploy / hubserving / ocr_cls

如果你在搭配模型时需要修改不同模型则可修改 params.py文件相关的配置即可
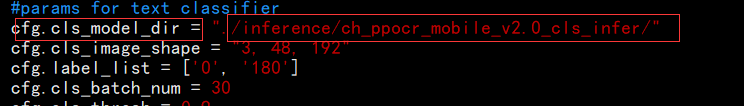
先说明一个完整的OCR识别服务是通过很多相关联的模型组成的就如目前的OCR文本识别来说:
光有ocr_cls是没用的,该模型只是处理文本方向的如一个图片一段文本是横的还是竖的会先同它来推理检查分析的,再将这些信息返回出来进行处理,
可处理改图来了解整个模型的运作流程及架构,后面具体的详细说明每个模型的使用及结果示例。

安装服务模块
PaddleOCR提供9种服务模块,根据需要安装所需模块。
在Linux环境下,安装示例如下:
# 安装检测服务模块:
hub install deploy/hubserving/ocr_det/
# 或,安装分类服务模块:
hub install deploy/hubserving/ocr_cls/
# 或,安装识别服务模块:
hub install deploy/hubserving/ocr_rec/
# 或,安装检测+识别串联服务模块:
hub install deploy/hubserving/ocr_system/
# 或,安装表格识别服务模块:
hub install deploy/hubserving/structure_table/
# 或,安装PP-Structure服务模块:
hub install deploy/hubserving/structure_system/
# 或,安装版面分析服务模块:
hub install deploy/hubserving/structure_layout/
# 或,安装关键信息抽取SER服务模块:
hub install deploy/hubserving/kie_ser/
# 或,安装关键信息抽取SER+RE服务模块:
hub install deploy/hubserving/kie_ser_re/
按需进行下载,我们就只需要下载四个服务模块分别是:ocr_det、ocr_cls、ocr_rec、ocr_system。
需要在PaddleOCR项目的根目录下执行命令。

下载完成后会提示如下内容:

其次依次下载其他模型服务,这样就已经完成相关的环境配置,
下一章节讲解如何使用paddleocr及相关模型的介绍。在自己搭建环境的时候如果出现有问题可以随时找我,可以帮忙解决或者部署。
如果觉得自己动手比较吃力但又想使用OCR那么就可以直接找到我这已经有现成的docker容器可以直接给到你直接用就可以了。
本文由mdnice多平台发布