联邦学习 (FL) 中常见的3种模型聚合方法的 Tensorflow 示例
目录
联合学习 (FL) 是一种出色的 ML 方法,它使多个设备(例如物联网 (IoT) 设备)或计算机能够在模型训练完成时进行协作,而无需共享它们的数据。
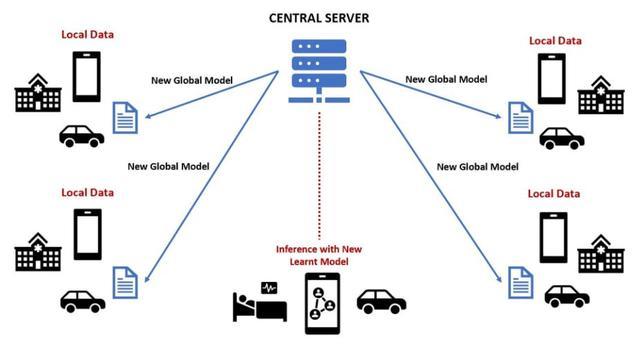
“客户端”是 FL 中使用的计算机和设备,它们可以彼此完全分离并且拥有各自不同的数据,这些数据可以应用同不隐私策略,并由不同的组织拥有,并且彼此不能相互访问。
使用 FL,模型可以在没有数据的情况下从更广泛的数据源中学习。 FL 的广泛使用的领域如下:
-
卫生保健
-
物联网 (IoT)
-
移动设备
由于数据隐私对于许多应用程序(例如医疗数据)来说是一个大问题,因此 FL 主要用于保护客户的隐私而不与任何其他客户或方共享他们的数据。 FL的客户端与中央服务器共享他们的模型更新以聚合更新后的全局模型。 全局模型被发送回客户端,客户端可以使用它进行预测或对本地数据采取其他操作。
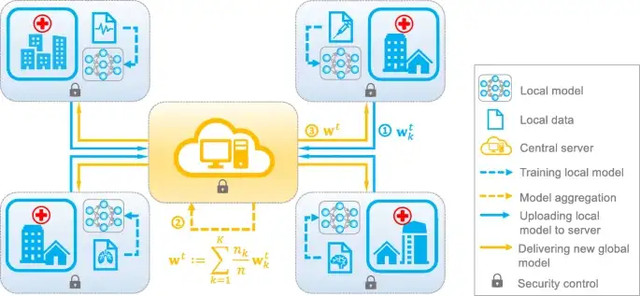
FL的关键概念
数据隐私:适用于敏感或隐私数据应用。
数据分布:训练分布在大量设备或服务器上;模型应该能够泛化到新的数据。
模型聚合:跨不同客户端更新的模型并且聚合生成单一的全局模型,模型的聚合方式如下:
-
简单平均:对所有客户端进行平均
-
加权平均:在平均每个模型之前,根据模型的质量,或其训练数据的数量进行加权。
-
联邦平均:这在减少通信开销方面很有用,并有助于提高考虑模型更新和使用的本地数据差异的全局模型的收敛性。
-
混合方法:结合上面多种模型聚合技术。
通信开销:客户端与服务器之间模型更新的传输,需要考虑通信协议和模型更新的频率。
收敛性:FL中的一个关键因素是模型收敛到一个关于数据的分布式性质的良好解决方案。
实现FL的简单步骤
-
定义模型体系结构
-
将数据划分为客户端数据集
-
在客户端数据集上训练模型
-
更新全局模型
-
重复上面的学习过程
Tensorflow代码示例
首先我们先建立一个简单的服务端:
import tensorflow as tf
# Set up a server and some client devices
server = tf.keras.server.Server()
devices = [tf.keras.server.ClientDevice(worker_id=i) for i in range(4)]
# Define a simple model and compile it
inputs = tf.keras.Input(shape=(10,))
outputs = tf.keras.layers.Dense(2, activation='softmax')(inputs)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Define a federated dataset and iterate over it
federated_dataset = tf.keras.experimental.get_federated_dataset(devices, model, x=X, y=y)
for x, y in federated_dataset:
# Train the model on the client data
model.fit(x, y)
然后我们实现模型聚合步骤:
1、简单平均
# Average the updated model weights
model_weights = model.get_weights()
for device in devices:
device_weights = device.get_weights()
for i, (model_weight, device_weight) in enumerate(zip(model_weights, device_weights)):
model_weights[i] = (model_weight + device_weight) / len(devices)
# Update the model with the averaged weights
model.set_weights(model_weights)
2、加权平均
# Average the updated model weights using weights based on the quality of the model or the amount of data used to train it
model_weights = model.get_weights()
total_weight = 0
for device in devices:
device_weights = device.get_weights()
weight = compute_weight(device) # Replace this with a function that returns the weight for the device
total_weight += weight
for i, (model_weight, device_weight) in enumerate(zip(model_weights, device_weights)):
model_weights[i] = model_weight + (device_weight - model_weight) * (weight / total_weight)
# Update the model with the averaged weights
model.set_weights(model_weights)
3、联邦平均
# Use federated averaging to aggregate the updated models
model_weights = model.get_weights()
client_weights = []
for device in devices:
client_weights.append(device.get_weights())
server_weights = model_weights
for _ in range(num_rounds):
for i, device in enumerate(devices):
device.set_weights(server_weights)
model.fit(x[i], y[i])
client_weights[i] = model.get_weights()
server_weights = server.federated_average(client_weights)
# Update the model with the averaged weights
model.set_weights(server_weights)
以上就是联邦学习中最基本的3个模型聚合方法,希望对你有所帮助