目标跟踪:Mobile Vision Transformer-based Visual Object Tracking

论文作者:Goutam Yelluru Gopal,Maria A. Amer
作者单位:Concordia University
论文链接:https://arxiv.org/pdf/2309.05829v1.pdf
项目链接:https://github.com/goutamyg/MVT
内容简介:
1)方向:目标跟踪算法
2)应用:大规模数据集上的目标跟踪
3)背景:近年来,引入了强大的骨干网络(如Vision Transformers),提高了目标跟踪算法的性能。然而,这些最先进的跟踪器在计算上很昂贵,因为它们具有大量的模型参数,并依赖于专用硬件(如GPU)进行更快的推理。另一方面,最近的轻量级跟踪器速度快,但准确性较低,特别是在大规模数据集上。
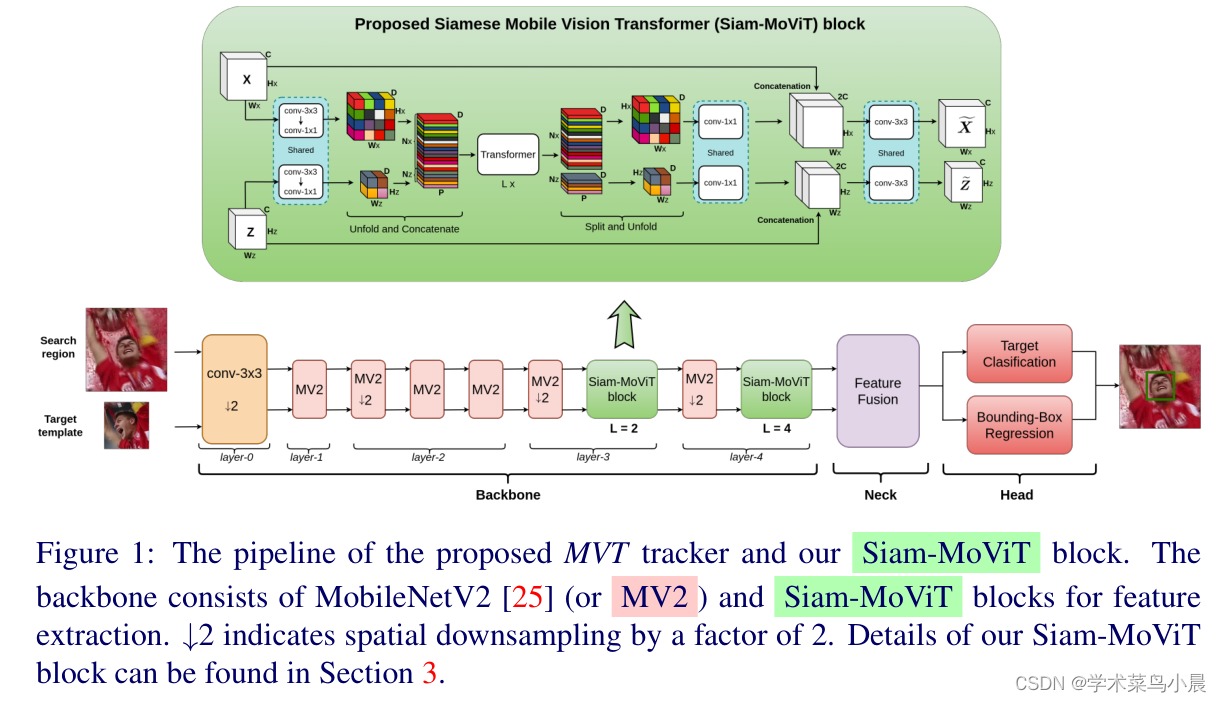
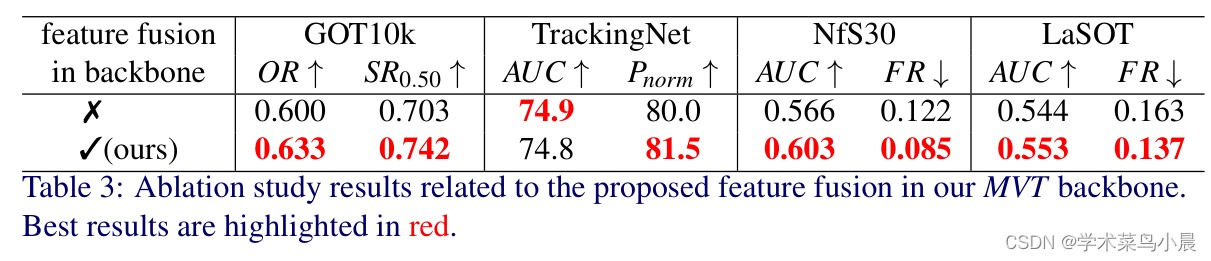
4)方法:本次工作,作者首次提出了一种使用Mobile Vision Transformers(MobileViT)作为骨干网络的轻量级、准确和快速跟踪算法。还提出了一种新的方法,将模板和搜索区域的表示融合在MobileViT骨干网络中,从而为目标定位生成优秀的特征编码。
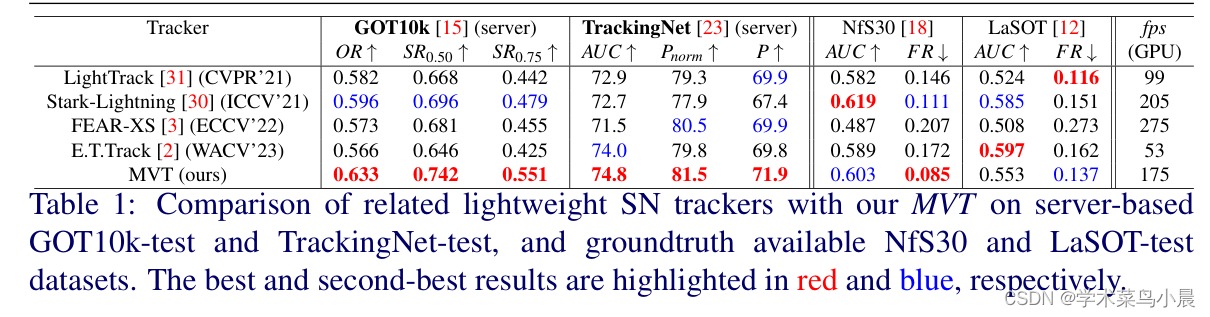
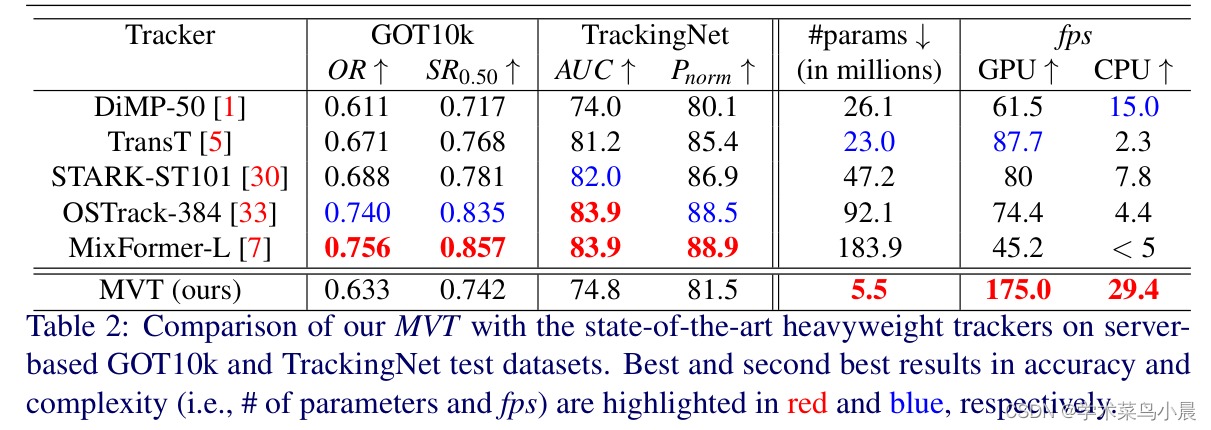
5)结果:实验结果表明,基于MobileViT的跟踪器MVT在大规模数据集GOT10k和TrackingNet上的性能超过了最近的轻量级跟踪器,并具有较高的推理速度。此外,该方法在GPU上的模型参数数量只有DiMP-50跟踪器的4.7倍,并以2.8倍的速度运行,但性能却更好。跟踪器的代码和模型可在https://github.com/goutamyg/MVT上获得。