图数据库选型对比
1、简介
属性图数据库,简称图数据库。图数据库完全和知识图谱契合,从底层的存储模型到支持的查询语言,甚至相关的概念都完全匹配。它们就是天造地设的一对,图数据库是知识图谱存储的首选。
2、常见的图数据库
常见的图数据库包括:JanusGraph、Neo4j、Dgraph、NebulaGraph、HugeGraph、OrientDB、 ArangoDB、TigerGraph等。下面列举,主流和推荐的几款图数据库的简介,应用场景和架构。
3、JanusGraph
3.1、JanusGraph简介
JanusGraph是一个可扩展的图数据库,可以把包含数千亿个顶点和边的图存储在多机集群上。它支持事务,支持数千用户实时、并发访问存储在其中的图。
JanusGraph是2016年12月27日从Titan fork出来的一个分支,之后TiTan的开发团队在2017年陆续发了0.1.0rc1、0.1.0rc2、0.1.1、0.2.0等四个版本,最新的版本是2017年10月12日。
3.2、JanusGraph使用场景
JanusGraph最大的一个好处就是:可以扩展图数据的处理,能支持实时图遍历和分析查询(Scaling graph data processing for real time traversals and analytical queries is JanusGraph’s foundational benefit.)。
因为JanusGraph是分布式的,可以自由的扩展集群节点的,因此,它可以利用很大的集群,也就可以存储很大的包含数千亿个节点和边的图。由于它又支持实时、数千用户并发遍历图和分析查询图的功能。所以这两个特点是它显著的优势。
它支持以下功能:
- 分布式部署,因此,支持集群。
- 可以存储大图,比如包含数千亿Vertices和edges的图。
- 支持数千用户实时、并发访问。(并发访问肯定是实时的,这个唉,没必要强调好像)
- 集群节点可以线性扩展,以支持更大的图和更多的并发访问用户。(Elastic and linear scalability for a growing data and user base)
- 数据分布式存储,并且每一份数据都有多个副本,因此,有更好的计算性能和容错性。(Data distribution and replication for performance and fault tolerance)
- 支持在多个数据中心做高可用,支持热备份。(Elastic and linear scalability for a growing data and user base)
- 支持各种后端存储系统,目前标准支持以下四种,当然也可以增加第三方的存储系统:
- Apache Cassandra®
- Apache HBase®
- Google Cloud Bigtable
- Oracle BerkeleyDB
- 通过集成大数据平台,比如Apache Spark、Apache Giraph、Apache Hadoop等,支持全局图数据分析、报表、ETL
- 支持geo(Gene Expression Omnibus,基因数据分析)、numeric range(这个的含义不清楚)
- 集成ElasticSearch、Apache Solr、Apache Lucene等系统后,可以支持全文搜索。
- 原生集成Apache TinkerPop图技术栈,包括Gremlin graph query language、Gremlin graph server、Gremin applications。
- 开源,基于Apache 2 Licence。
- 通过使用以下系统可以可视化存储在JanusGraph中的图数据:
- Cytoscape
- Gephi plugin for Apache TinkerPop
- Graphexp
- KeyLines by Cambridge Intelligence
- Linkurious
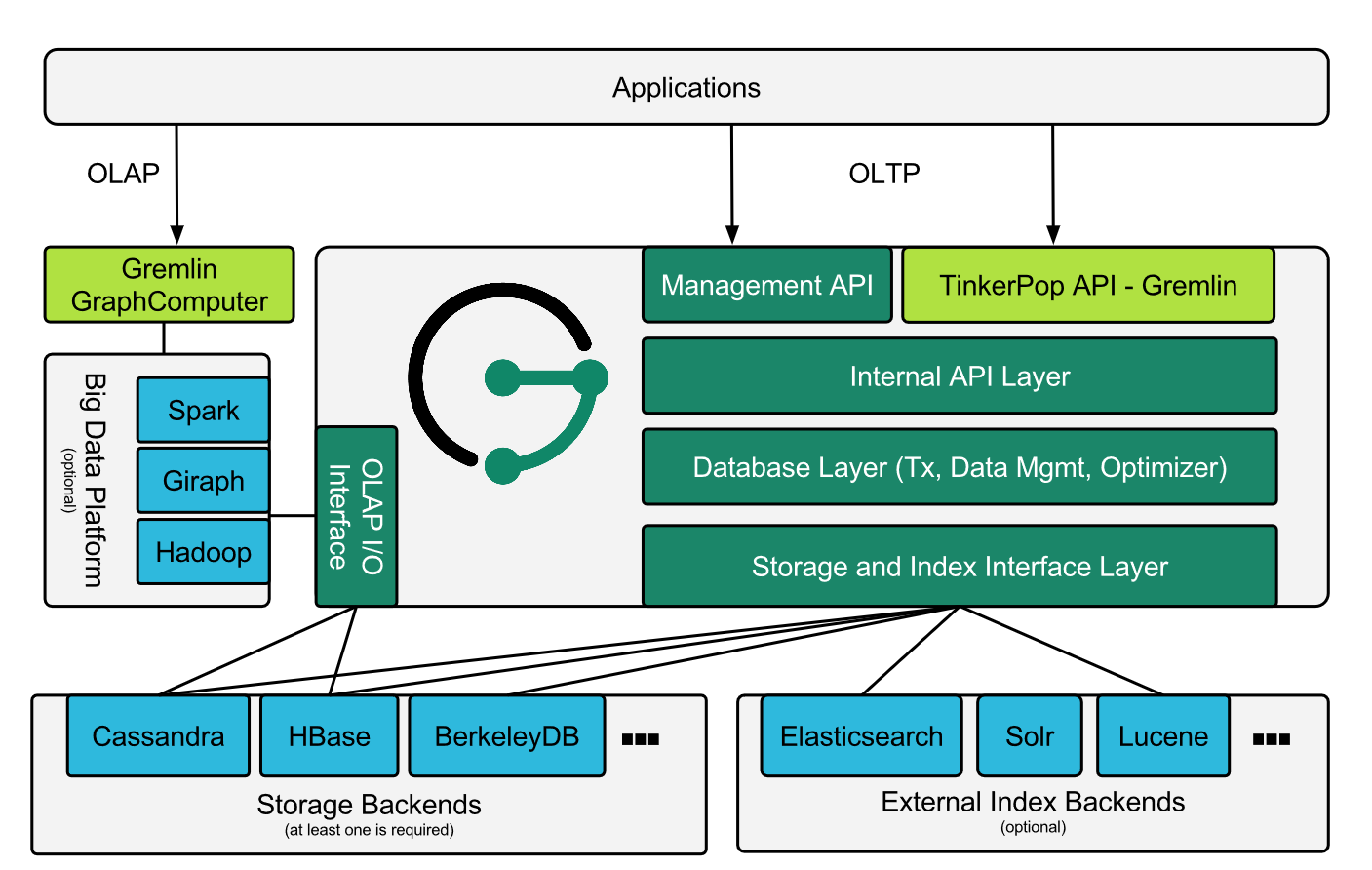
3.3、JanusGraph架构
JanusGraph是模块化的体系结构(JanusGraph has a modular architecture)。
它使用hadoop来做图的分析和图的批处理,使用模块化接口来做数据持久化、索引和客户端访问。
在JanusGraph和磁盘之间有多个后端存储系统和多个索引系统。(Between JanusGraph and the disks sits one or more storage and indexing adapters.)
它支持的外部存储系统,目前标准支持的有(当然也可以将第三方的存储系统作为JanusGraph的后端存储系统):
Apache Cassandra
Apache HBase
Oracle Berkeley DB Java Edition
Google Cloud BigTable
支持的外部索引系统:
Elasticsearch
Apache Solr
Apache Lucene
体系结构图:
4、Neo4j
4.1、Neo4j简介
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注。
Neo4j是一个嵌入式,基于磁盘的,支持完整事务的Java持久化引擎,它在图(网络)中而不是表中存储数据。Neo4j提供了大规模可扩展性,在一台机器上可以处理数十亿节点/关系/属性的图,可以扩展到多台机器并行运行。相对于关系数据库来说,图数据库善于处理大量复杂、互连接、低结构化的数据,这些数据变化迅速,需要频繁的查询——在关系数据库中,这些查询会导致大量的表连接,因此会产生性能上的问题。Neo4j重点解决了拥有大量连接的传统RDBMS在查询时出现的性能衰退问题。通过围绕图进行数据建模,Neo4j会以相同的速度遍历节点与边,其遍历速度与构成图的数据量没有任何关系。此外,Neo4j还提供了非常快的图算法、推荐系统和OLAP风格的分析,而这一切在目前的RDBMS系统中都是无法实现的。
由于使用了“面向网络的数据库”,人们对Neo充满了好奇。在该模型中,以“节点空间”来表达领域数据——相对于传统的模型表、行和列来说,节点空间是很多节点、关系和属性(键值对)构成的网络。关系是第一级对象,可以由属性来注解,而属性则表明了节点交互的上下文。网络模型完美的匹配了本质上就是继承关系的问题域,例如语义Web应用。Neo的创建者发现继承和结构化数据并不适合传统的关系数据库模型:
4.2、Neo4j使用场景
- 图搜索算法
- 寻路算法
- 中心性算法
- 社区检测算法
- 图嵌入
- 链接预测
- 连接特征提取
-
社交媒体和社交网络图。
-
知识图。
-
反欺诈多维关联分析。
-
企业关系图谱。
-
征信系统。
-
客户分析。
-
产品推荐。
-
风险管理。
图嵌入,金融欺诈检测,NLP中的知识图谱,物流分析,推荐系统等
说到图算法,就需要提到Neo4j GDS,图分析和建模平台,2.0版本发支持60+图算法。传统做法:很多业务应用直接使用Neo4j;GDS。
第一阶段:知识图谱
在关联数据中搜索特定的关联模式。例如构建企业级的应用知识图谱,借助知识图谱回答特定的问题。
第二阶段:图算法
使用无监督的机器学习技术识别图中的关联、异常值和趋势。例如了解图中最重要的是什么、哪里有相似性、应该在哪步做调查。
第三阶段:图原生机器学习
使用嵌入来学习图中那些可能之前不知道的重要特征,训练图内监督机器学习模型来预测链接、标签和缺失数据。例如哪些客户会购买哪些商品、哪些交易存在欺诈行为。
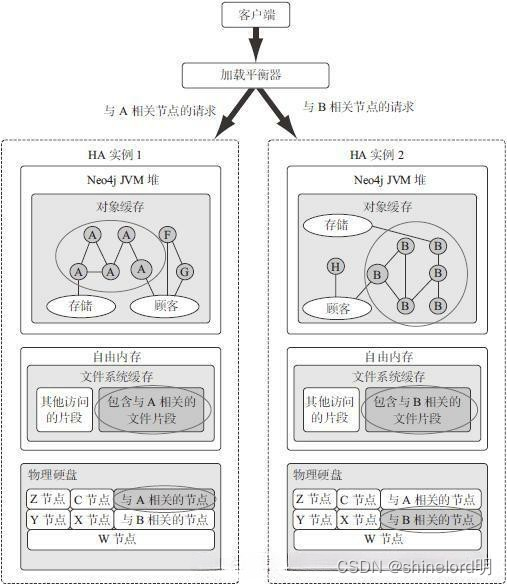
4.3、Neo4j架构
架构上,单机版数据库,本身不支持HA,需要其它辅助。
5、Dgraph
5.1、Dgraph简介
由Google公司开发的一款开源、分布式图数据库系统,为了满足其自身海量的网络搜索查询的需求,其前身是GraphD。截止目前(2020-11-24)最新版本为v20.07。
- 编写语言:Go编写
- 不支持SQL
- 查询语言:DQL
- 支持分布式
- 完全开源免费
- 副本:强一致性
- 自动数据均衡
- 支持全文检索
- 支持正则表达式
- 支持地理位置检索
- 支持可视化
- 维护成本低
- 写入性能高
- 查询速度快
Dgraph有一些缺点:
- 目前还不支持多重边
- 一个集群只支持一个图
- 与大数据生态兼容性不足。
Dgraph 从一开始就设计为在生产环境中运行,是带有图形后端的原生 GraphQL 数据库。它是开源的、可扩展的、分布式的、高可用的和闪电般的速度。
5.2、Dgraph使用场景
应用程序实现 GraphQL 后端的最简单方法。开箱即用地包含构建应用程序、整合数据和扩展运营所需的一切。
-
数据库和后端开发的单一模式方法
使用 Dgraph,只需创建您的架构、部署它,并拥有即时数据库和 API 访问权限。无需代码。几分钟内即可投入生产。 -
查询你想要的方式
从 GraphQL 中选择或使用 DQL 超越。即使以前没有任何图形数据库经验,也可以快速轻松地深入了解您的数据。 -
统一您的数据
轻松将数据导入或流式传输到 Dgraph,以利用统一数据图的强大功能。超越孤立数据的限制,在一个地方完成更多工作。 -
简化您的业务逻辑
使用 Dgraph Lambda,在 JavaScript 中快速创建可以在调用查询或突变时执行的自定义逻辑。 -
无缝扩展
即使在提供 TB 级数据时,也可以轻松进行水平扩展以保持高吞吐量和低延迟。Dgraph 是为 Google 规模设计的下一代图形系统,由前 Google 员工构建。
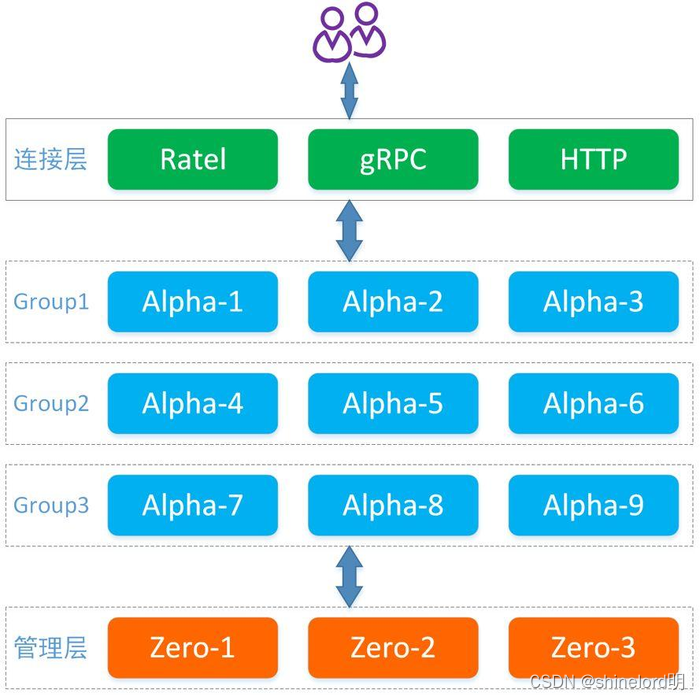
5.3、Dgraph架构
- ratel:提供用户界面来执行数据查询,数据修改及元数据管理。
- alpha:用于管理数据(谓词和索引),外部用户主要都是和 alpha 进行数据交互。
- group:多个 alpha 组成一个 group,group 中的多个 alpha 通过 raft 协议保证数据一致性。
- zero:用于管理集群,并在 group 之间按照指定频率去均衡数据。
6、NebulaGraph
6.1、NebulaGraph简介
NebulaGraph由杭州悦数科技有限公司研发的图数据库,作为一款开源 的分布式图数据库,NebulaGraph 擅长处理千亿个顶点和万亿条边的超大规模数据集。
作为一款高性能高可靠的图数据库,NebulaGraph 提供了线性扩容的能力,支持快照方式实现数据恢复功能。在查询语言方面,开发团队完全自研开发查询语言——nGQL,兼容 OpenCypher,让 Neo4j 的用户可无缝衔接使用 NebulaGraph。
6.2、NebulaGraph使用场景
NebulaGraph 可用于各种基于图的业务场景。为节约转换各类数据到关系型数据库的时间,以及避免复杂查询,建议使用 NebulaGraph。 欺诈检测 金融机构必须仔细研究大量的交易信息,才能检测出潜在的金融欺诈行为,并了解某个欺诈行为和设备的内在关联。这种场景可以通过图来建模,然后借助 NebulaGraph,可以很容易地检测出诈骗团伙或其他复杂诈骗行为。
-
开源:NebulaGraph 代码开源,采用 Apache 2.0 License,用户可以从 GitHub 下载源码自己编译,部署。欢迎提交 pr,成为 Contributor。
-
可扩展性:存储计算相分离的架构,当存储空间或计算资源不足时,支持对两者独立进行扩容,避免了传统架构需要同时扩容导致的经济效率低问题。云计算场景下,能实现真正的弹性计算。提供线性扩展的能力。
-
高可用:全对称分布式集群,无单点故障。并且支持多种类型快照方式实现数据恢复,保证在局部失败的情况下服务的高可用性。
-
HTAP: 支持 OLTP 实时查询的同时提供了 OLAP 的接口,真正在同一份数据上提供实时在线更新的前提下,也提供复杂分析和挖掘的能力。
-
安全性:内置授权登录与 ACL 机制,提供用户安全的数据库访问方式,也可接入 LDAP 认证。
-
类 SQL 查询语言 nGQL:类 SQL 的风格减少了程序员迁移的成本,同时具有表达能力强的优点。
6.3、NebulaGraph架构
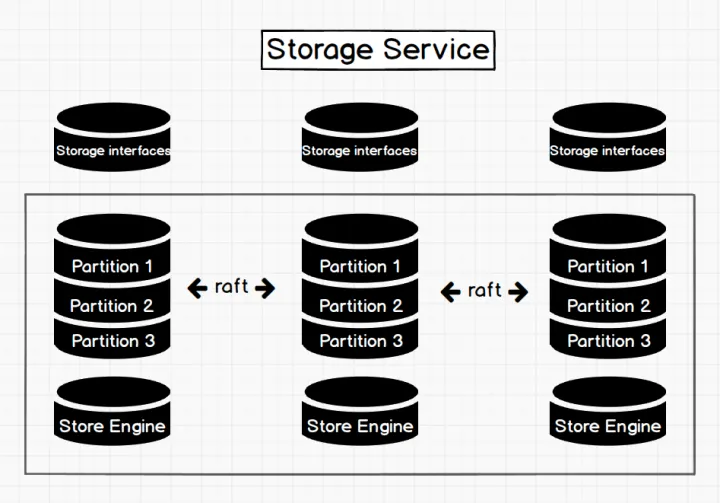
NebulaGraph整体分为存储 ( Storage ) 和计算 ( Query Engine ) ,每个数据库都有其独有的存储、计算方式, Nebula Graph 的存储部分Storage 。
Storage 包含两个部分, 一是 meta 相关的存储, 我们称之为 Meta Service ,另一个是 data 相关的存储, 我们称之为 Storage Service。 这两个服务是两个独立的进程,数据也完全隔离,当然部署也是分别部署
Storage Service 共有三层,最底层是 Store Engine,它是一个单机版 local store engine,提供了对本地数据的 get / put / scan / delete 操作,相关的接口放在 KVStore / KVEngine.h 文件里面,用户完全可以根据自己的需求定制开发相关 local store plugin,目前 Nebula 提供了基于 RocksDB 实现的 Store Engine。
在 local store engine 之上,便是我们的 Consensus 层,实现了 Multi Group Raft,每一个 Partition 都对应了一组 Raft Group,这里的 Partition 便是我们的数据分片。目前 Nebula 的分片策略采用了 静态 Hash 的方式,具体按照什么方式进行 Hash,在下一个章节 schema 里会提及。用户在创建 SPACE 时需指定 Partition 数,Partition 数量一旦设置便不可更改,一般来讲,Partition 数目要能满足业务将来的扩容需求。
在 Consensus 层上面也就是 Storage Service 的最上层,便是我们的 Storage interfaces,这一层定义了一系列和图相关的 API。 这些 API 请求会在这一层被翻译成一组针对相应 Partition 的 kv 操作。正是这一层的存在,使得我们的存储服务变成了真正的图存储,否则,Storage Service 只是一个 kv 存储罢了。而 Nebula 没把 kv 作为一个服务单独提出,其最主要的原因便是图查询过程中会涉及到大量计算,这些计算往往需要使用图的 schema,而 kv 层是没有数据 schema 概念,这样设计会比较容易实现计算下推。
7、主流图数据库对比总结
JanusGraph(推荐)、Neo4j(老牌先入为主不一定最佳)、Dgraph(尚可)、NebulaGraph(推荐)四款图数据库比较。
| 特性 | JanusGraph | Neo4j | Dgraph | NebulaGraph |
| 首次发布 | 2017年 | 2007年 | 2016年 | 2019年 |
| 开发语言 | Java | Java | Go | C++ |
| 开源 | 是 | 是 | 是 | 是 |
| 属性图模型 | 完整的属性图模型 | 完整的属性图模型 | 类RDF存储 | 完整的属性图模型 |
| 架构 | 分布式 | 单机 | 分布式 | 分布式 |
| 存储后端 | Hbase、Cassandra、 BerkeleyDB |
自定义文件格式 | 键值数据库BadgerDB | 键值数据库 RocksDB |
| 高可用性 | 支 持 | 不支持 | 支持 | 支持 |
| 高可靠性 | 支 持 | 不支持 | 支持 | 支持 |
| 一致性协议 | Paxos等 | 无 | RAFT | RAFT |
| 跨数据中心复制 | 支 持 | 不支持 | 支持 | 不支持 |
| 事务 | ACID或BASE | 完全的ACID | 0mid修改版 | 不支持 |
| 分区策略 | 随机分区,支持显式指定分区策略 | 不支持分区 | 自动分区 | 静态分区 |
| 大数据平台集成 | Spark、Hadoop、Giraph | Spark | 不支持 | Spark、Flink |
| 查询语言 | Gremlin | Cypher | GraphQL | nGQL |
| 全文检索 | ElasticSearch、Solr、Lucene | 内置 | 内置 | ElasticSearch |
| 多个图 | 支持创建任意多图 | 一个实例只能有一个图 | 一个集群只能有一个图 | 支持创建任意多图 |
| 属性图模式 | 多种约束方法 | 可选模式约束 | 无模式 | 强制模式约束 |
| 客户端协议 | HTTP、WebSockets | HTTP、BOLT | HTTP、gRPC等 | HTTP |
| 客户端语言 | Java、Python、C#、Go、Ruby 等 |
Java、Python、Go等 | Java、Go、Python、等 | Python、Java等 |