SGPT: GPT Sentence Embeddings for Semantic Search
简介
语义搜索分为两个部分:
1.搜索和query 相关的topk文档。
2.理解文档和query后面隐藏的语义信息,而不是字面含义。
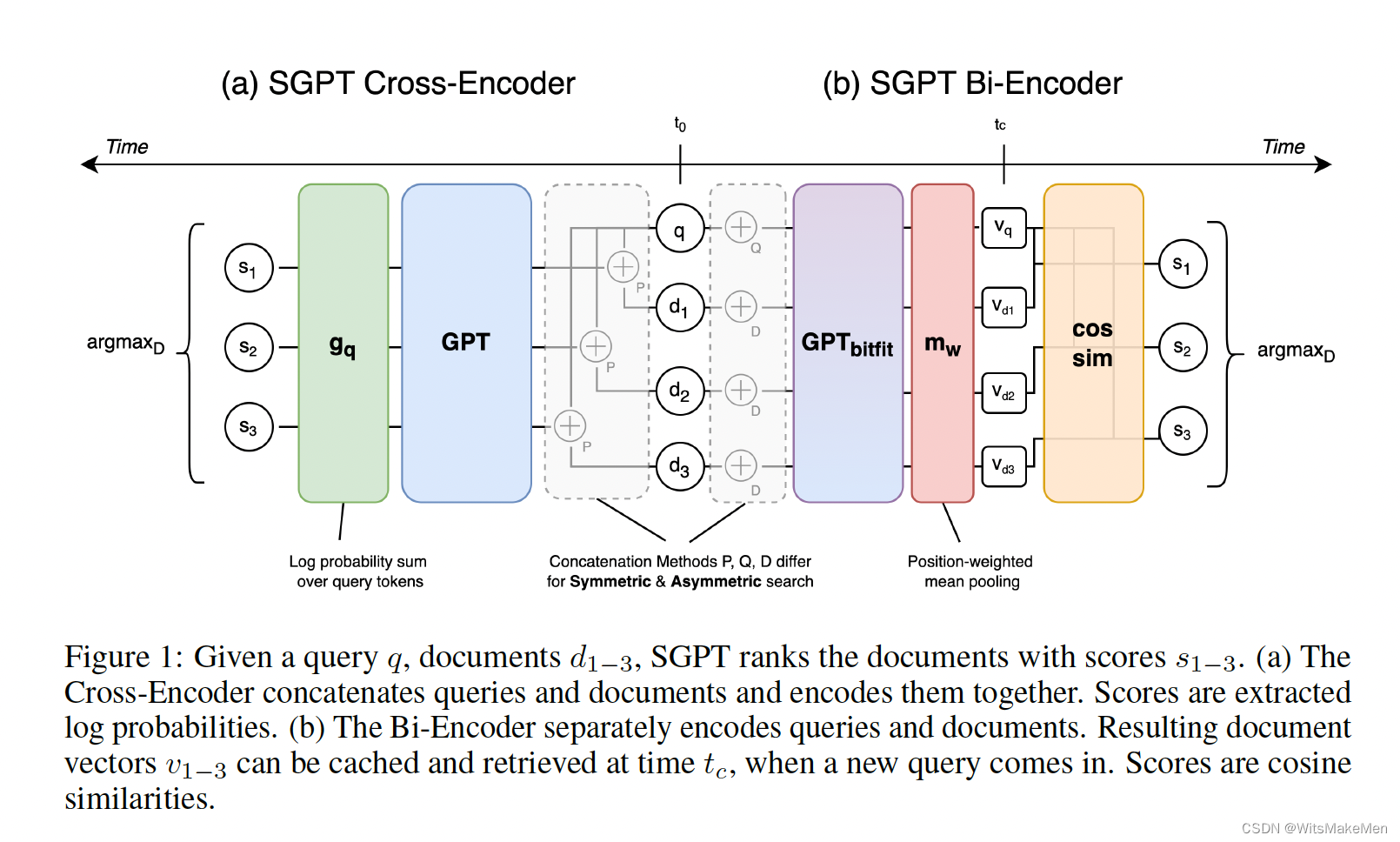
这篇论文提出了SGPT模型,只用decoder-only的transformer来进行语义搜索和sentence向量的提取。
1.SGPT-BE:来对文档和query进行粗略的相关度计算,由于可以对文档的向量进行缓存,所以计算量和文档的数量线性相关,SGPT使用了BitFit的方式只对模型bias等少部分参数进行微调,大部分模型参数在微调的过程中是被冻结的,所以能够大大提升模型的训练效率。
2.SGPT-CE:对文档和query进行concat拼接,拼接后输入到gpt模型中去,对模型输出的query token的概率进行sum pooling的方式,作为文档的得分。由于CE的方式每一个query都需要重复计算很多次,所以计算量比较大,所以一般是在BE之后,对top的文档进行encoder概率计算。
SGPT Cross-Encoder


SGPT Bi-Encoder
