Oracle开窗函数(分析函数)以及滑动窗口
Oracle窗口函数也叫分析函数,是系统自带的一种函数。可以对数据的结果集进行分组操作,然后对分组的数据进行分析统计,可以在每个分组的每一行中返回统计值。
这里要注意:分析函数和分组统计函数group by不是一个概念,group by只是对数据集进行分组操作然后返回值,而且不能够在原来的数据集上返回,分析函数则可以在原来的数据集上新增列,这一列就可以写不同分析函数的返回值。
分析函数通常和over()开窗函数结合使用。
1.聚合开窗函数
常见的有sum() count() avg() max() min() wm_concat()
着重注意:聚合开窗函数很少使用order by排序,因为在使用的时候要注意滑动窗口(后续详解)。
2.排序开窗函数
row_number() dense_rank() rank()
排序开窗函数可以使用partition by和order by语句。
三者区别为:
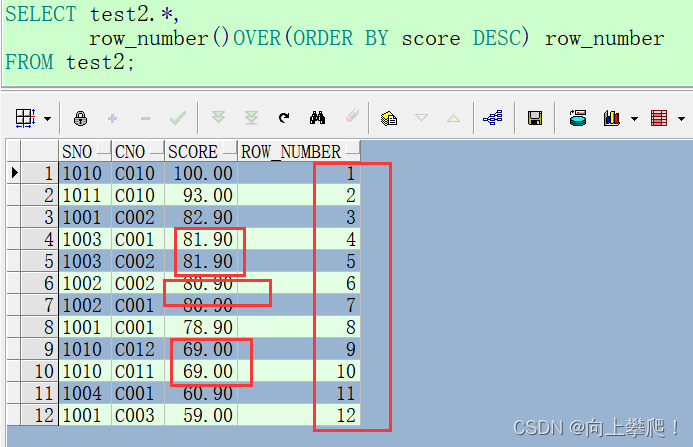
row_number()不考虑重复值,序号是连续的
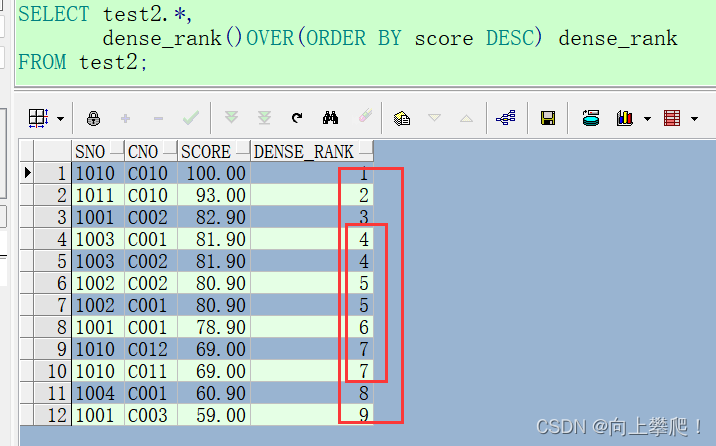
dense_rank()考虑重复值,序号是连续的
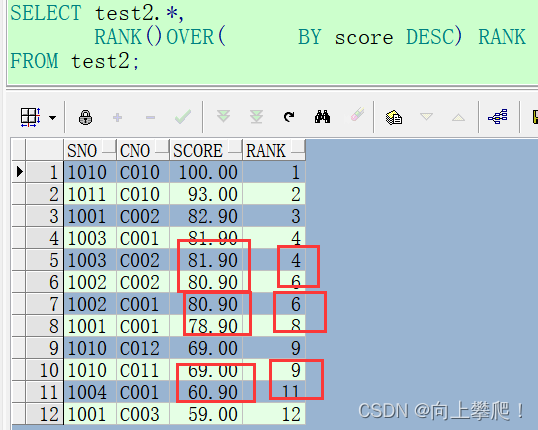
rank()考虑重复值,序号不连续
3.其他的一些分析函数
FIRST_VALUE 获取窗口的第一个值
LASY_VALUE 获取窗口的最后一个值
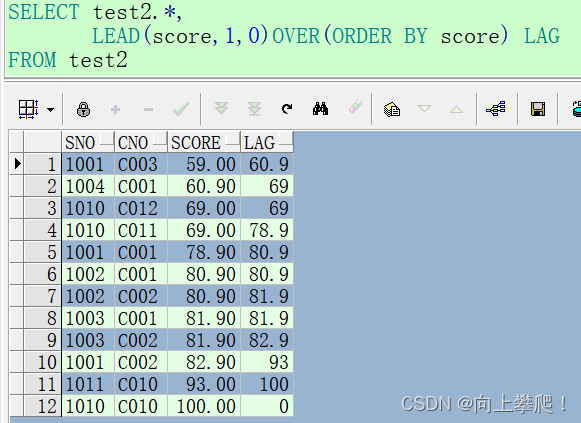
LEAD 获取当前行后面的值
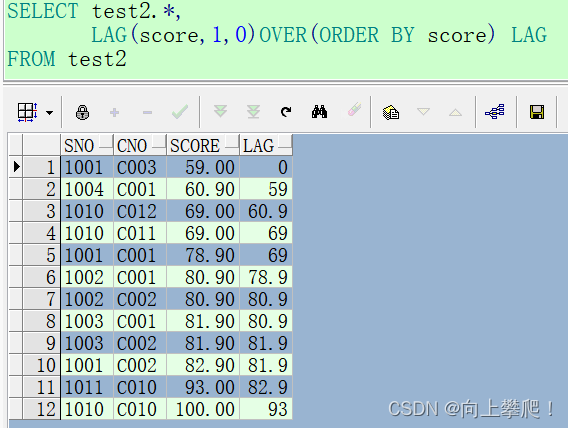
LAG 获取当前行前面的之
NTH_VALUE 获取指定行的数据
NTILE 根据设定的组数对记录进行平均分组并编号
PERCENT_RANK 类似于RANK,[0,1]
CUME_DIST 类似于RANK,(0,1],不会返回0
LAG():
LEAD():
4.滑动窗口
①BETWEEN 开始关键字 AND 结束关键字
为保证时间复杂度O(1),聚合函数和last_value函数的滑动窗口边界为分区的第一个和当前行.所以使用聚合函数搭配order 和last_value函数的输出结果有些怪异,每次都不和分区内的后面数据计算,这时候就需要指定窗口边界.
窗口边界:
unbounded:无界限
current row:当前行,偏移量为0,一般和其他范围关键字一起使用
unbounded preceding 边界是分区中的第一行
unbounded following 边界是分区中的最后一行
N preceding 边界是当前行减去N的值,N为相对当前行向前的偏移量.从分区第一行头开始,则为 unbounded.
N following 边界是当前行加上N的值,N为相对当前行向后的偏移量.与preceding相反,到该分区结束,则为 unbounded.
实例:
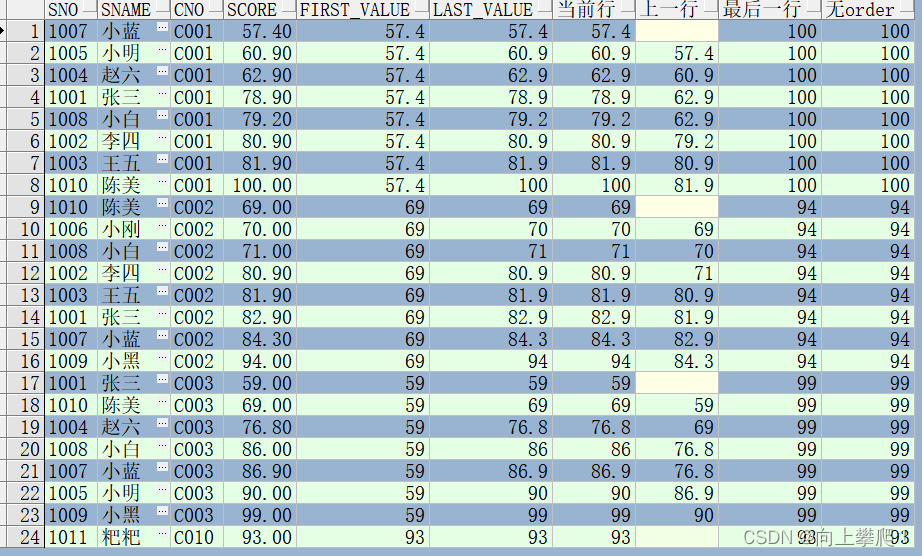
SELECT sno,sname,cno,score,
--first_value取窗口第一行
first_value(score)OVER(PARTITION BY cno ORDER BY score) first_value,
--last_value取窗口当前行
last_value(score)OVER(PARTITION BY cno ORDER BY score) last_value,
--使用聚合开窗的时候,默认窗口边界是当前行
MAX(SCORE)OVER(PARTITION BY cno ORDER BY score) "当前行",
--取分组的上一行:range between unbounded preceding and N preceding,N为前几行
MAX(score)OVER(PARTITION BY cno ORDER BY score RANGE BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) "上一行",
--取分组的最后一行:range between unbounded preceding and unbounded following
MAX(score)OVER(PARTITION BY cno ORDER BY score RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) "最后一行",
--无order关键字
MAX(score)OVER(PARTITION BY cno) "无order"
FROM STU_TEST2;
②NTH_VALUE()
--NTH_VALUE(col,N):(字段名,位移量)
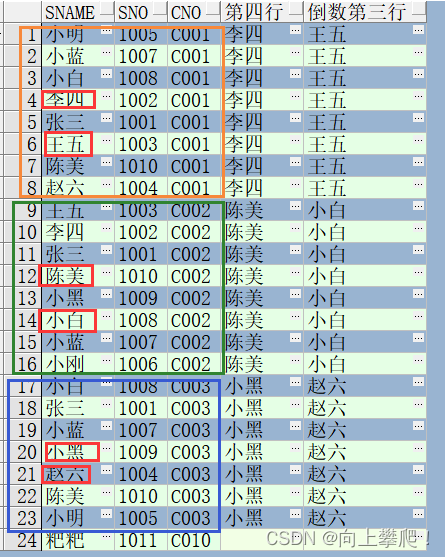
SELECT t.sno,t.sname,t.cno,
NTH_VALUE(sname,4)OVER(PARTITION BY cno ORDER BY score RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) "第四行",
NTH_VALUE(sname,2)OVER(PARTITION BY cno ORDER BY score RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) "第二行"
FROM stu_test2 t
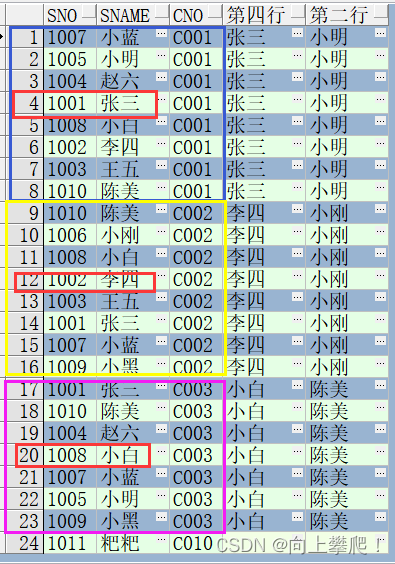
可以看到,对课程号进行分组后,可以取出每一组位移量处的字段值。
③
FROM FIRST:从窗口的第一行开始找位移后的数据行
FROM LAST:从窗口的最后一行开始找位移后的数据行
SELECT t.sname,t.sno,t.cno,
NTH_VALUE(sname,4) FROM FIRST OVER(PARTITION BY cno) "第四行",
NTH_VALUE(sname,3) FROM LAST OVER(PARTITION BY cno) "倒数第三行"
FROM stu_test2 t;