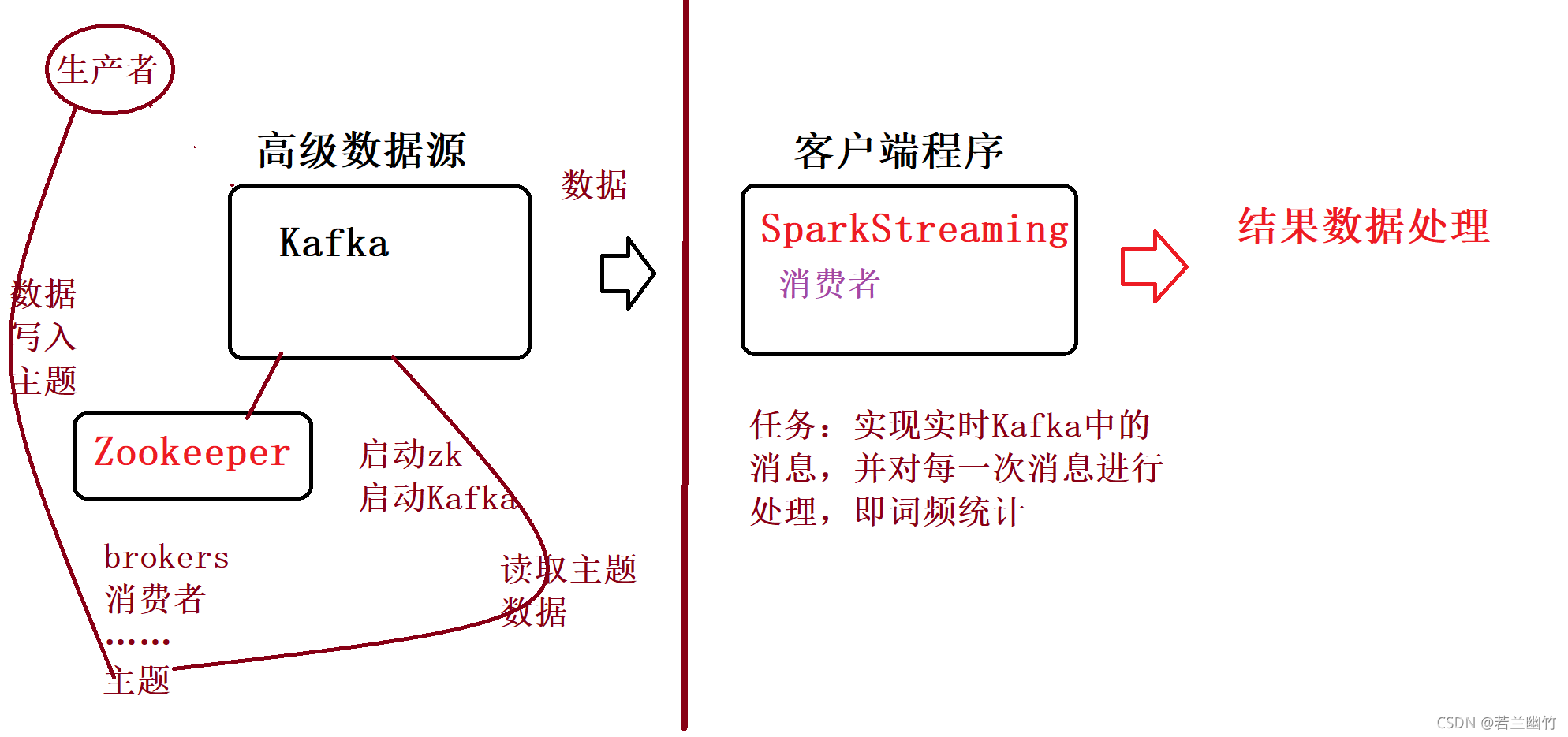
编写程序,如下所示:package com.spark.streaming.kafka
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object KafkaDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("KafkaTest")
val streamingContext = new StreamingContext(sparkConf, Seconds(2))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "niit01:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("test", "t100")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
val mapDStream: DStream[(String, String)] = stream.map(record => (record.key, record.value))
val resultRDD: DStream[(String, Int)] = mapDStream.flatMap(_._2.split(" ")).map((_, 1)).reduceByKey(_ + _)
resultRDD.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}