数据离散化
数据离散化
- 时间数据离散化
将时间格式的数据(datatime)以固定转换方式进行转换。
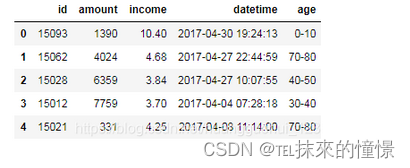
这里转换为周数
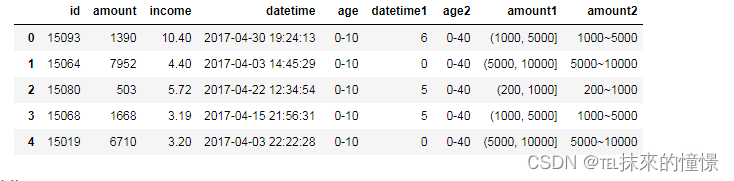
#针对时间数据的离散化
df['datetime1']=pd.to_datetime(df['datetime']).apply(lambda x:x.weekday())
df.head()
- 多数据离散化
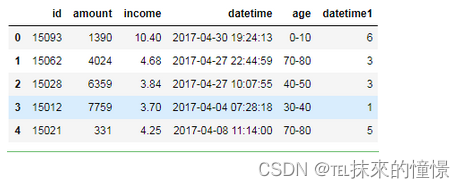
需要重新离散化数据时,重新划分区间
merge将指定列df和map_df按on中的值为参考合并
#对age的值域进行重构
map_df=pd.DataFrame([['0-10','0-40'],['10-20','0-40'],['20-30','0-40'],['30-40','0-40'],
['40-50','40-80'],['50-60','40-80'],['60-70','40-80'],['70-80','40-80'],
['80-90','>80'],['>90','>80']],columns=['age','age2'])
map_df
#离散化
df=pd.merge(df,map_df,how='inner',on=['age'])
df
- 自定义区间
在pandas中使用pd.qcut或者是pd.cut方法实现数据切割。
pd.qcut(data,q)的函数意义为:
data:需要被切割的数据。
q:需要切割多少个组。
自动分组
qcut = pd.qcut(df['字段'], 6)
qcut.value_counts()
自己指定切割的区间和数量。
这时候可以使用pd.cut实现。
pd.cut(data, bins)参数意义如下:
data:需要被切割的数据。
bins:切割的区间列表。
cut = pd.cut(df["字段"], bins=[-10, -5, 0, 5, 10, 15])
cut.value_counts()
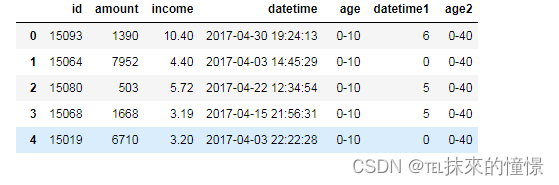
#1、自定义分箱区间
#1)cut方法
bins=[0,200,1000,5000,10000]
df['amount1']=pd.cut(df['amount'],bins)
df
#2)digitize方法
bins=[0,200,1000,5000,10000] #注意:bins数据是有要求的,bins内的数据一定要是降序或者升序的数据,不能是一堆无序数据。
indices=np.digitize(df['amount'],bins) #返回值为每个值所属区间的索引。
indices
df['amount2']=[str(bins[i-1])+"~"+str(bins[i]) for i in indices]
df
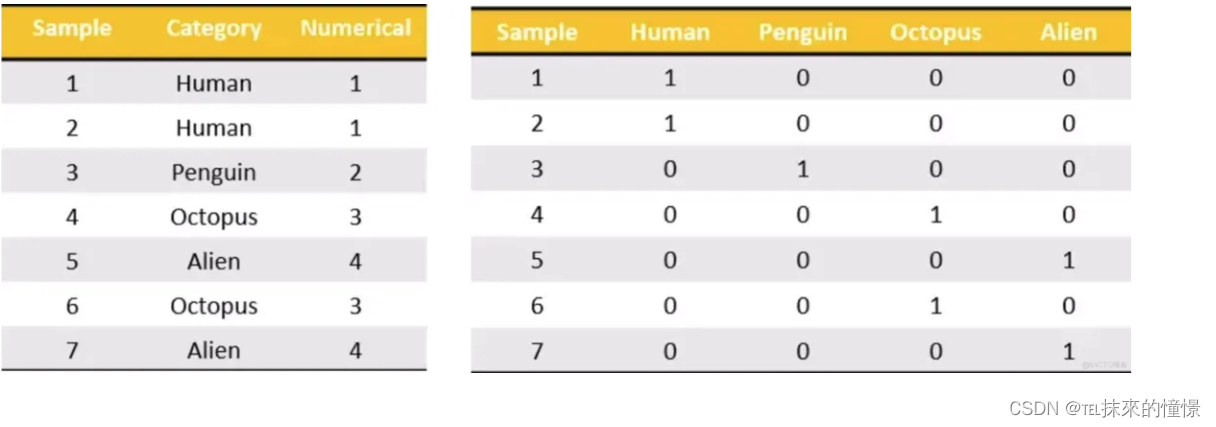
- 独热编码(One-hot编码)离散化
One-Hot编码是将分类数据的所有项,全部都变成列,然后如果某一行中出现这一列,那么就标记为1,否则就标记为0。比如下图将左边的Category变为One-Hot编码后,会把Category中所有唯一的值都添加为新的列。
说口水话就是将一列数据所有可能出现的类别,弄成列名,如果第一行(按原数据的行数)出现了对应的类别,就在该类别下标上1,其余的都是0。这样就能把所有的类别弄成1000、0010、0001这种形式的。
弄成这种形式过后,使用欧式距离(sqrt(a²+b²))计算出类别之间的距离
get_dummies将类别变量转为哑变量
我们看一下它的定义:
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False, dtype=None)
各参数的含义:
data: array-like, Series, DataFrame
prefix: string, list of strings, dict of strings, default None
prefix_sep: str, default ‘_’ (转换后列名的前缀)
dummy_na: bool, default False(增加一列表示空缺值,如果False就忽略空缺值)
columns: list-like, default None (指定需要实现类别转换的列名)
sparse: bool, default False
drop_first: bool, default False (获得k中的k-1个类别值,去除第一个)
dtype: dtype, default np.uint8
pd.get_dummies(df['Product'], prefix="Product")
# df['Product']中的元素前面以Product_列名的形式