阿里云高级技术专家林立翔:基于阿里云弹性GPU服务的神龙AI加速引擎,无缝提升AI训练性能
2023 年 3 月 23 日 14:00,NVIDIA GTC 开发者大会阿里云开发者社区观看入口正式开放,阿里云高级技术专家林立翔带来了题为《基于阿里云弹性 GPU 服务的神龙 AI 加速引擎,无缝提升 AI 训练性能》的分享,以下是他的演讲内容整理。
阿里云弹性 GPU 服务是阿里云为云上客户提供的包括 NVIDIA GPU 在内的 IAAS 实例,神龙 AI 加速引擎是构建在阿里云 GPU IAAS 服务之上的软件工具,旨在用户使用阿里云 GPU IAAS 服务进行人工智能计算时,可以高效地发挥 GPU 实例的效率。
云上用户进行人工智能训练的场景与分布,对我们分析用户的使用习惯与痛点并针对性地提供优化解决方案,具有很好的指导意义。
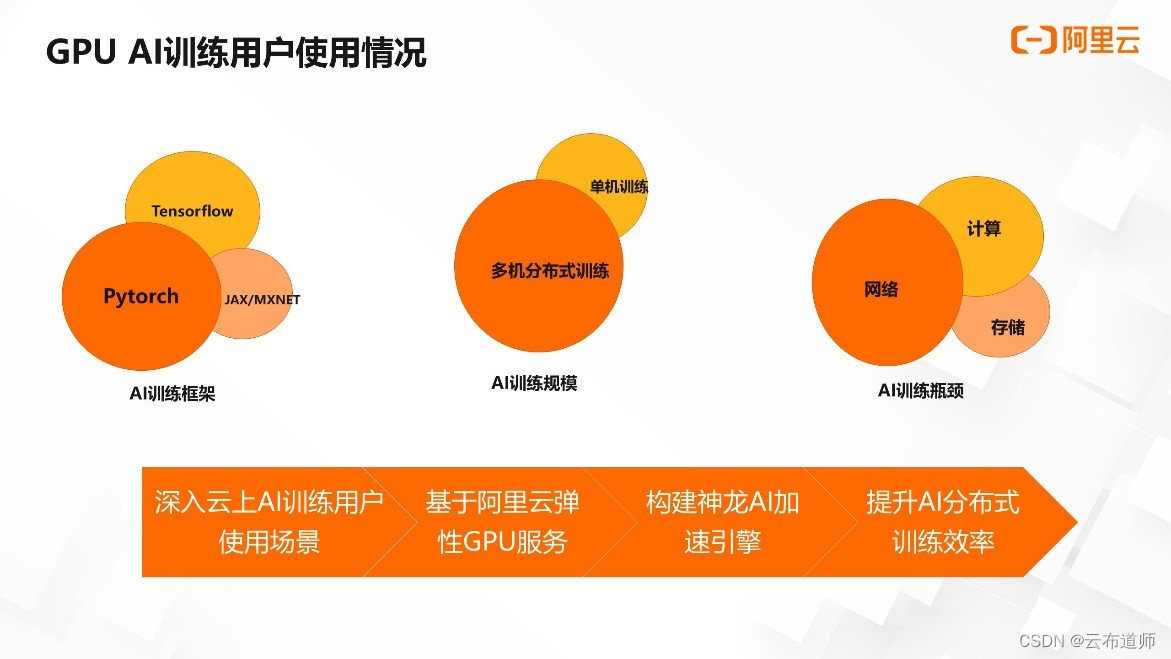
Pytorch 框架的易用性在学术界深入人心并逐渐蔓延到工业界。目前,Pytorch 几乎已经成为云上 AI 用户训练新的 AI 模型的框架首选。此外,在推荐系统等场景上 Tensorflow 仍然占有重要的一席之地,而 MXNET 与 JAX 目前被使用的频次越来越低。
其次,在 AI 训练任务的机器规模上,目前阿里云上提供单机 8 卡 GPU 的裸金属/虚拟机实例,用户可以使用单机或通过网卡互联组建多机的训练集群。阿里云同时也提供了单卡/两卡/四卡等虚拟机实例供用户选择。
目前一部分用户的训练任务可以通过单机实现,比如部分 fintune 模型与训练时长可以接受的中小模型。有相当大的一部分用户有多台 GPU 实例组成训练集群,进行数据并行或模型并行训练任务的诉求,比如拥有海量训练数据集的预训练模型的训练任务或超大规模模型的训练任务。
在 AI 训练过程中,用户往往利用 AI 框架本身与 NVIDIA 提供的构建在 cuda 之上、AI 框架之下的加速软件达成训练 AI 模型的目的。但在实际端到端训练任务过程中,往往会存在计算、网络、存储等三大瓶颈,尤其在使用多机多卡进行分布式训练的场景下,机器之间的网络效率问题是常见且主要的 AI 训练任务的性能瓶颈。
在深入理解用户使用云上 GPU 实例进行训练任务的场景与使用痛点后,如何基于阿里云弹性 GPU 服务之上,软硬结合地解决用户痛点并最终提升用户 AI 训练的性能,尤其是分布式训练的性能,是神龙 AI 加速引擎的目标。
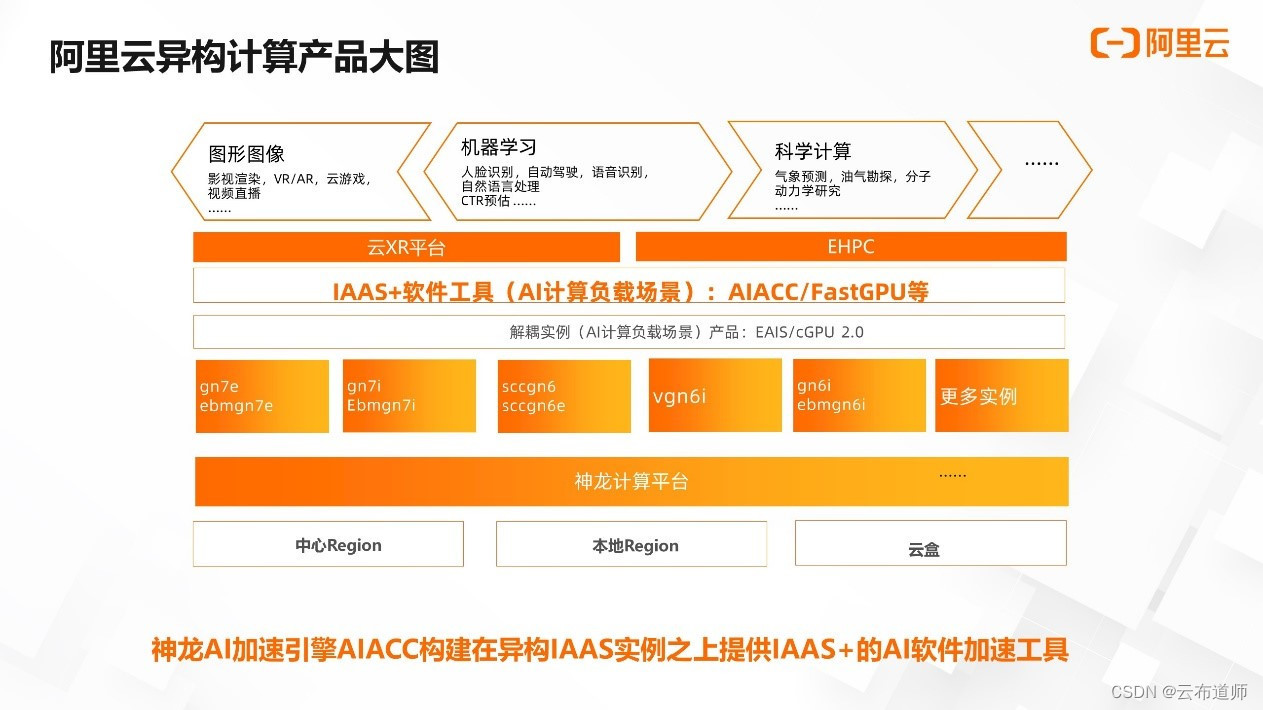
阿里云异构计算构建在神龙计算平台的底座之上,提供 NVIDIA GPU 与其他异构器件等多种异构实例产品。另外,在提供传统实例的同时,也提供 AI 计算负载解耦的实例,如 EAIS。
神龙 AI 加速引擎 AIACC 如图所示,构建在异构实例之上。在平台层之下,作为 IAAS+ 的软件工具形态,用于加速 AI 计算负载的场景。除了 AIACC 之外,该层还提供了 fastgpu 等工具,用于方便快速地搭建 GPU 集群。
神龙 AI 加速引擎 AIACC 提供的软件包括 AI 训练与 AI 推理两个方面。
在 AI 训练领域,神龙 AI 加速引擎 AIACC 针对用户使用云上实例进行 AI 训练的主要痛点,分别在分布式训练与训练计算图上进行了软硬结合的优化,形成了相应的软件工具来加速用户的 AI 训练性能。

上图为神龙 AI 加速引擎 AIACC 在分布式训练方面的软件架构图,软件代码称为 Acspeed(下文将以 Acspeed 来统称 AIACC 在分布式训练上的软件优化工具)。
在海量数据背景下,分布式训练是用户进行 AI 训练的普遍诉求。而云上实例能提供的网卡间通信能力,相较于单机内部能提供的 nvlink/nvswitch 等,不管是在通信延时还是在通信带宽上,都具有不止一个数量级的优势。
机器之间互联能力与机器内互联能力的差异,在数据并行与模型并行等分布式训练场景下,往往会使机器之间的数据交换成为整个训练效率的短板,这也是 Acspeed 需要重点解决的性能问题。
从用户的使用习惯看,Pytorch 是目前新模型训练的主要框架,而 Pytorch ddp 是 Pytorch 进行分布式训练的原生选择。
因此,除了对底层网络的性能优化外,Acspeed 同时需要保障与原生 ddp 的使用习惯兼容,使用户的使用成本降到最低。因此,Acspeed 在软件架构上采用了分层解耦的形式,对上实现了与 AI 框架的无缝兼容,对下实现了对底层基础设施的性能优化,跨层间实现了特定 AI 场景下通信效率的多维调优。
如图所示,Acspeed 针对分布式训练的瓶颈,通过 AI 框架层集合通信算法层与网络层分层解耦的方式实现了软硬结合的无感性能优化。
在 AI 框架层,Acspeed 使用 Pytorch 从 c10d-plugin 的接口与对应的 wrapper,实现对 Pytorch ddp 使用方式的无感支持与 bucket 层级的优化;对使用 Tensorflow 的用户,Acspeed 同样提供 horovo-api 的兼容层。
在集合通信算法层,Acspeed 使用集合通信编译器的技术,在 nccl runtime 的基础上,针对 nvlink/nvswitch/PCIe/NIC 交换机等互联信息进行自适应的拓扑感知与算法优化。
在网络层,Acspeed 针对阿里云 VPC 网络与 eRDMA 网络的基础设施进行了深入优化。由于对 Pytorch ddp 使用方式的无缝支持,用户无需改动业务代码即可享受到 Acspeed 带来的分布式训练性能的优化效果。
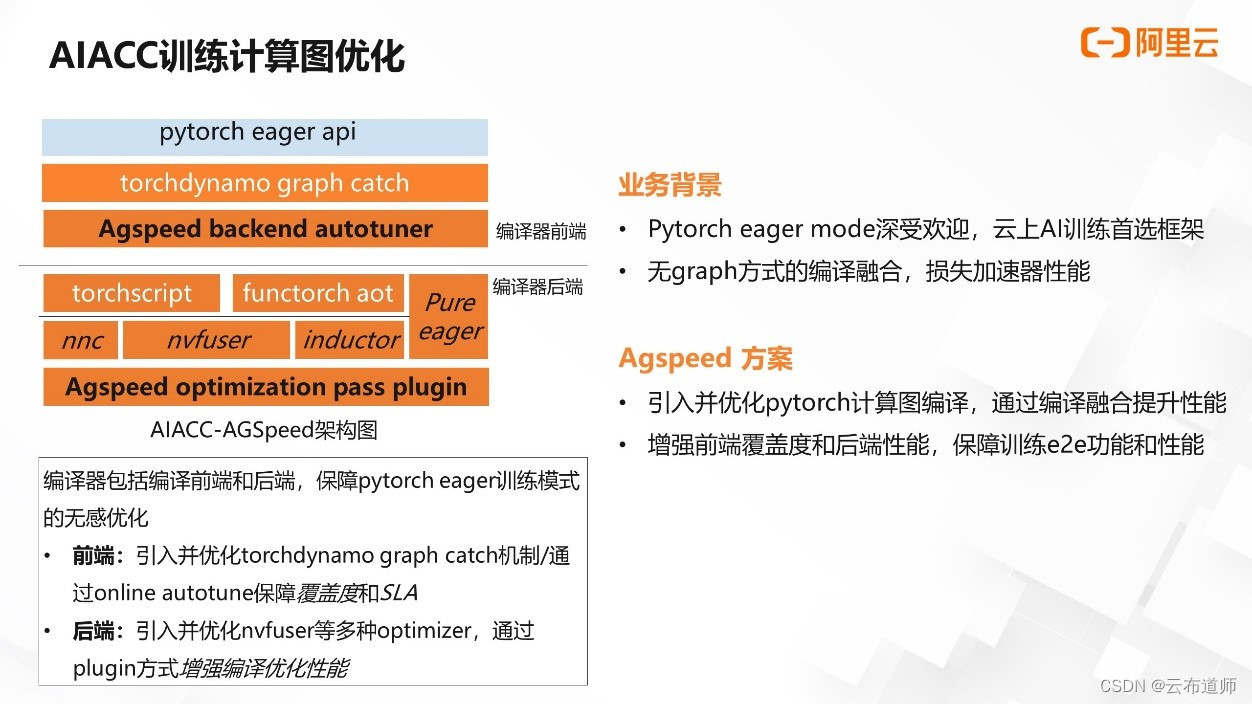
AIACC 也针对 Pytorch 训练计算图进行了编译优化,软件代码为 Agspeed(后文将统一使用 Agspeed 来表示 AIACC 在 Pytorch 计算训练图的优化工作)。
众所周知,Pytorch 的模式以其出众的易用性席卷学术界与工业界。相对于 graph 模式,Pytorch 模式虽然直接,但缺少了图融合的机制,在部分场景下会不同程度地导致 GPU 计算效率不高。Pytorch 社区也发现了该问题,并且已经着手 graph 模式的工作,在保障使用体验不受影响的前提下进行计算图的优化,涌现了包括 torchscrip、torchdynamo、inductor 等出色的项目,并进行了持续的集成与迭代。到 Pytorch2.0 时代后,计算图编译的功能将成为 Pytorch 框架缺省的选项。
目前,整个 Pytorch 训练计算图组件在端到端场景仍有待改善的环节,包括频繁的 graph recompile、graph break 等问题,限制了在用户场景的落地与使用。
Agspeed 在吸收社区优秀工作的基础上,针对目前 Pytorch 计算图的不足,在端到端场景做了长足的覆盖性与优化工作。
如图所示,Agspeed 上层保障用户侧 Pytorch eager API 使用场景不变,重点针对编译器的前端与后端进行了覆盖度的优化。在编译器前端,Agspeed 引入了 torch dynamo 的 graph catch 机制,针对 catch 的异常做了捕获与优化。通过前端的 autotuner 自动选择性能最优的后端优化器。在编译器后端,Agspeed 引入了包括 torchscript、Functor aot、nvfusor、inductor 等后端,并且针对端到端模型在特定后端的性能不足问题,通过 plugin 的方式添加到优化路径中。
Agspeed 相较于 eager 模式与目前的编译手段,保障了用户端到端性能的增强以及提供了 SLA 保障。
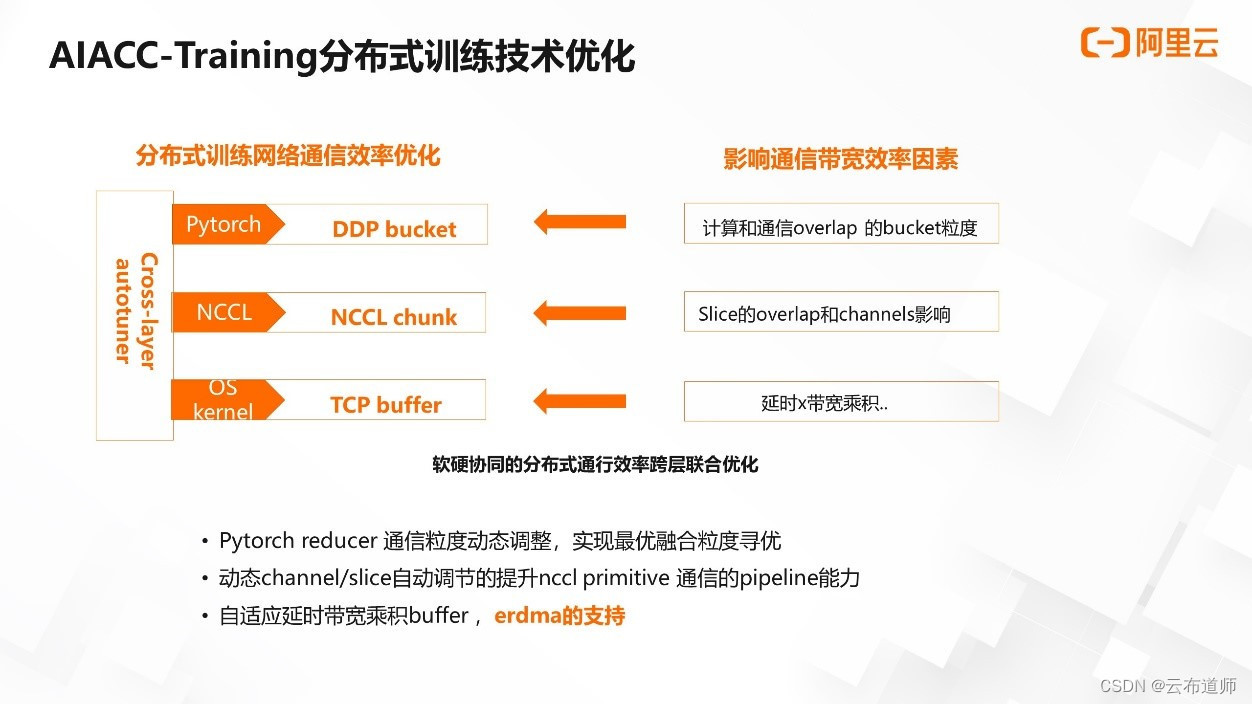
我们将 Acspeed 软件的优化栈分为 AI 框架层、集合通信算法层与网络层。特例到使用 Pytorch 进行 AI 训练的场景,即对应着 Pytorch 层、nccl 层与操作系统的 TCP 层。
在分布式训练中,Pytorch、nccl、TCP 不同层级分别有不同的通信数据结构作为载体,承接进行分布式通信的任务。比如,对应 Pytorch 框架的是 ddp 的 bucket,它是在框架层的通信传输数据结构;对应 nccl 的通信载体是 nccl 侧的 chunk,它是 nccl 进行通信传输的数据结构;tcp 层对应的是 tcp 的 buffer,它是 tcp 进行通信的真实传输数据。
影响不同层次通信载体或数据结构的带宽利用率的因素不尽相同又相互关联。
不尽相同的部分在于:对于 ddp bucket,影响通信效率的主要因素是计算与通信 overlap 的 bucket 粒度;nccl chunk 影响通信效率的主要因素是 slice 的 overlap 与 channel 的影响等;TCP buffer 影响通信效率的主要因素是延时带宽的乘积等。
而相互关联的部分在于:pytorch 的 ddp bucket 向下会拆解为 nccl 的 chunk 进行传输,而 nccl 的 chunk 又会向下拆解成 tcp 的 buffer 进行传输。
上层的通信数据划分粒度与策略会影响下层通信的效率与策略的选择。
Acspeed 在架构上打通了框架层、集合通信算法层到网络层,同时对多层的影响因素进行跨层的 autotune 来实现整体通信效率的提升。与此同时,针对影响不同层的通信效率问题,在工程上做了进一步软硬结合的优化。
在 AI 框架层,对 Pytorch reducer 的通信粒度进行了动态调整,实现了最佳的融合粒度寻优;在 nccl 侧工程上,通过动态 channel slice 的自动调节,提升了 nccl primitive 通信的 pipeline 能力;在网络层,实现了自适应延迟带宽乘积的 buffer,并且支持阿里云特有的 eRDMA 功能。
不同于传统的 TCP/IP,RDMA 可以将网络协议栈卸载在网卡上,从而优化网络间的通信。RDMA 在使用方式上相较于 TCP/IP 也会有所不同。
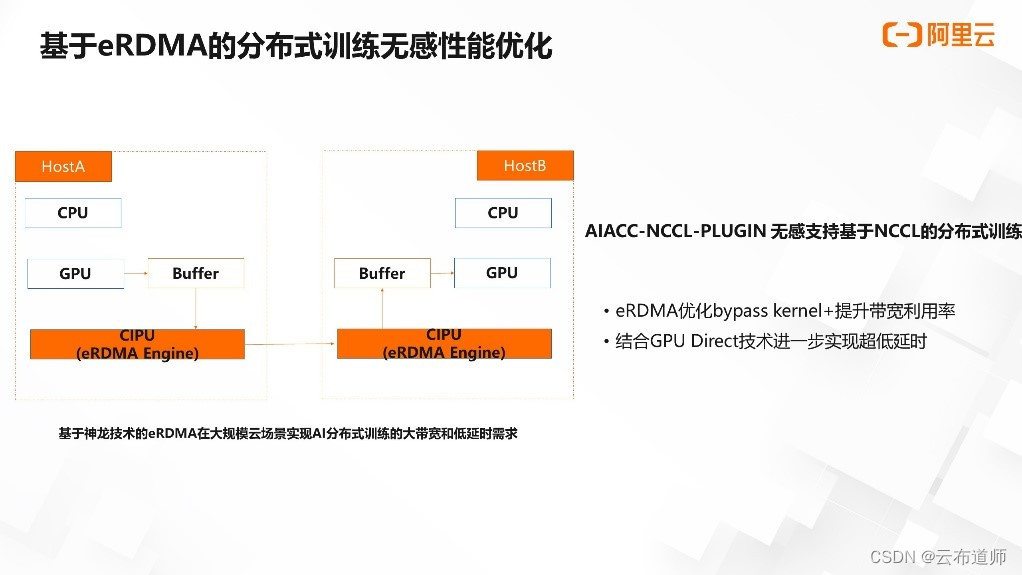
eRDMA 是阿里云创新性提出的大规模云网络使用 RDMA 的解决方案,实现了在云化网络的大规模 RDMA 集群组网能力。它不仅可以实现通信软件栈的 Bypass os kurnel 的能力以提升通信带宽的利用率,同时,针对 GPU 训练场景,结合 GPU Direct RDMA 技术可以 bypass host,实现 GPU buffer 的高效跨机传输。
如图所示,eRDMA 最大效率实现了在大规模云场景下,AI 分布式训练对网络大带宽与延迟的要求。由于 eRDMA 与传统的 TCP/IP 程序逻辑上存在着较大的区别,Acspeed 在通信层提供的 nccl plugin 可以无感支持 nccl 对 RDMA 能力的使能与优化,让用户在无需改变任何现有使用方式的前提下,享受 eRDMA 在分布式训练带来的效果。
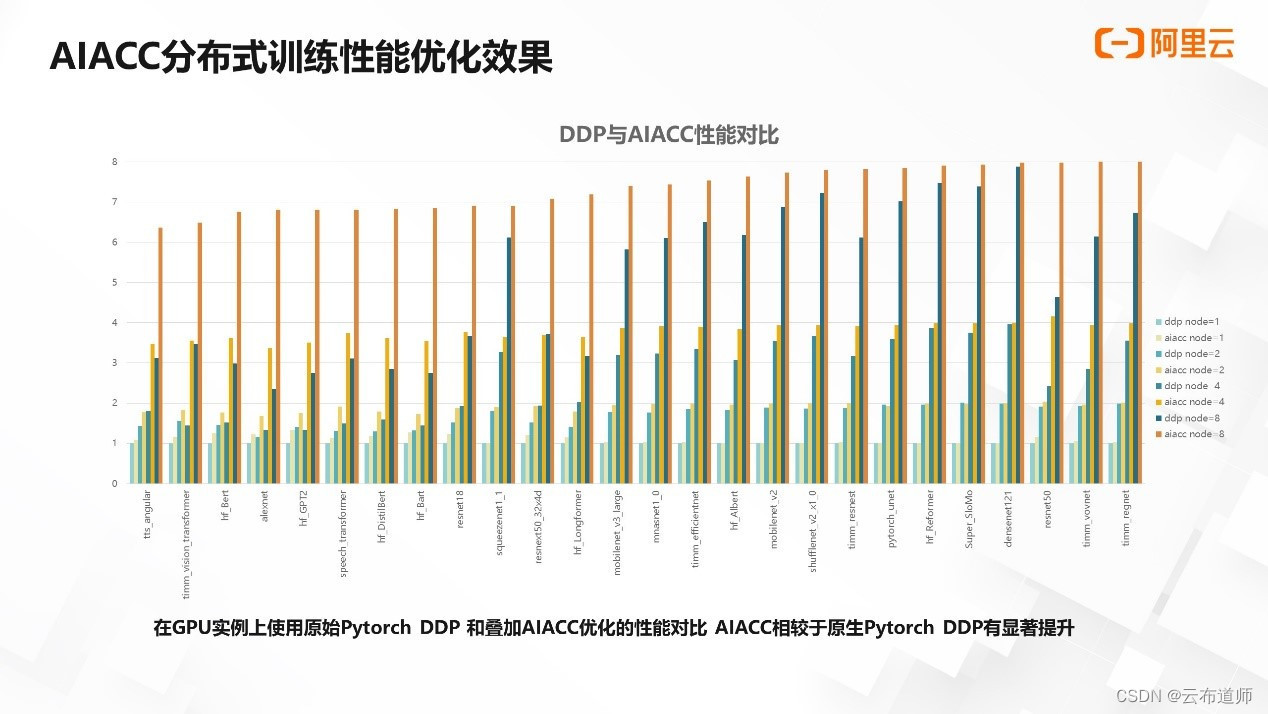
我们选取的阿里云上某款实例单机到 8 机进行分布式训练扩展的 benchmark,比较 Pytorch 原生 ddp 与叠加了 AIACC 优化能力的性能。
上图横坐标表示各个不同模型在不同机器规模下使用 Pytorch ddp、Acspeed 与 Agspeed 进行训练的数据。纵坐标是归一化的性能数据,单机的性能表示为 1,理想的 8 机的性能为 8。可以看出,从单机 8 卡到 8 机 64 卡,AIACC 的扩展性更优,相对于 Pytorch 原生的 ddp 有显著的性能提升,提升效果在 30% 到 150% 不等。
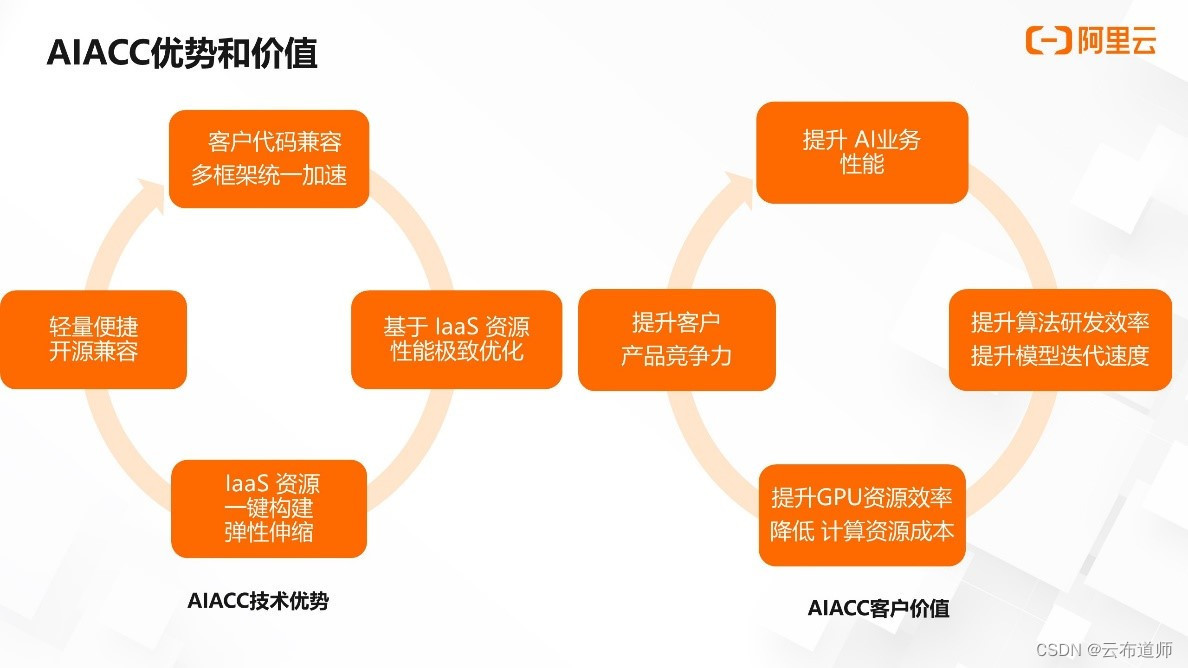
AIACC 实现了对客户代码的兼容,客户可以无感使用 AIAC 进行加速,结合阿里云的 IAAS 资源实现了软硬结合的深度优化。而以上所有能力都以便捷、开源、兼容的方式提供给客户,提升了客户 AI 训练的业务性能,加快了客户算法的研发效率与模型的迭代速度,同时也提升了用户使用 GPU 资源的效率,降低计算资源的成本,最终提升客户产品的竞争力,也体现了 AIACC 的客户价值。

最后,欢迎大家使用 AIACC 加速云上的训练业务。
我们提供了一键勾选、软件包安装等多种方式,方便用户直接在异构实例上或容器上运行 AIACC。以 Acspeed 为例,只需在业务代码上 import torch 后加上 import acspeed 的一行代码,便可以开启您的 AIACC 加速之旅。
AI 分布式训练通信优化库 AIACC-ACSpeed 官方使用文档
https://help.aliyun.com/document_detail/462031.html
AI 训练计算优化编译器 AIACC-AGSpeed 官方使用文档
https://help.aliyun.com/document_detail/467465.html
点击文末“阅读原文”即可观看完整视频。