用Python的pandas读取excel文件中的数据
一、前言
hello呀!各位铁子们大家好呀,今天呢来和大家聊一聊用Python的pandas读取excel文件中的数据。
二、读取Excel文件
使用pandas的read_excel()方法,可通过文件路径直接读取。注意到,在一个excel文件中有多个sheet,因此,对excel文件的读取实际上是读取指定文件、并同时指定sheet下的数据。可以一次读取一个sheet,也可以一次读取多个sheet,同时读取多个sheet时后续操作可能不够方便,因此建议一次性只读取一个sheet。
当只读取一个sheet时,返回的是DataFrame类型,这是一种表格数据类型,它清晰地展示出了数据的表格型结构。具体写法为:
(1)不指定sheet参数,默认读取第一个sheet,
df=pd.read_excel("data_test.xlsx")
(2)指定sheet名称读取,
df=pd.read_excel("data_test.xlsx",sheet_name="test1")
(3)指定sheet索引号读取,
df=pd.read_excel("data_test.xlsx",sheet_name=0) #sheet索引号从0开始
*同时读取多个sheet,以字典形式返回。(不推荐)
(1)指定多个sheet名称读取, df=pd.read_excel("data_test.xlsx",sheet_name=["test1","test2"])
(2)指定多个sheet索引号读取,
df=pd.read_excel("data_test.xlsx",sheet_name=[0,1])
(3)混合指定sheet名称和sheet索引号读取,
df=pd.read_excel("data_test.xlsx",sheet_name=[0,"test2"])
点我免费领取全套软件测试(自动化测试)视频资料(备注“知乎AAA”)
三、DataFrame对象的结构
对内容的读取分有表头和无表头两种方式,默认情形下是有表头的方式,即将第一行元素自动置为表头标签,其余内容为数据;当在read_excel()方法中加上header=None参数时是不加表头的方式,即从第一行起,全部内容为数据。读取到的Excel数据均构造成并返回DataFrame表格类型(以下以df表示)。
对有表头的方式,读取时将自动地将第一行元素置为表头向量,同时为除表头外的各行内容加入行索引(从0开始)、各列内容加入列索引(从0开始)。如图所示
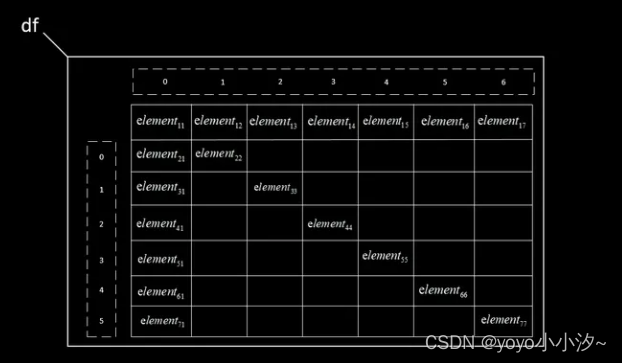
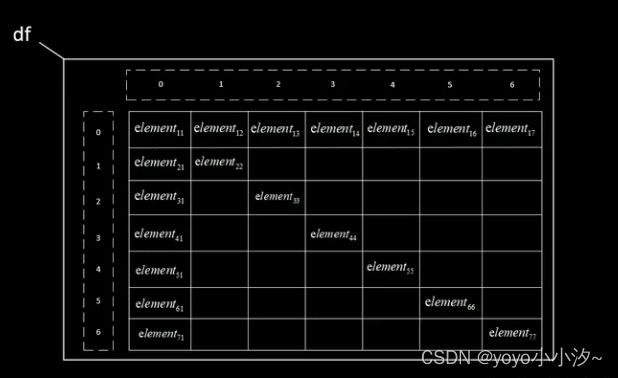
对无表头的方式,读取时将自动地为各行内容加入行索引(从0开始)、为各列内容加入列索引(从0开始),行索引从第一行开始。如图所示
四、用values方式获取数据
1.基本方法
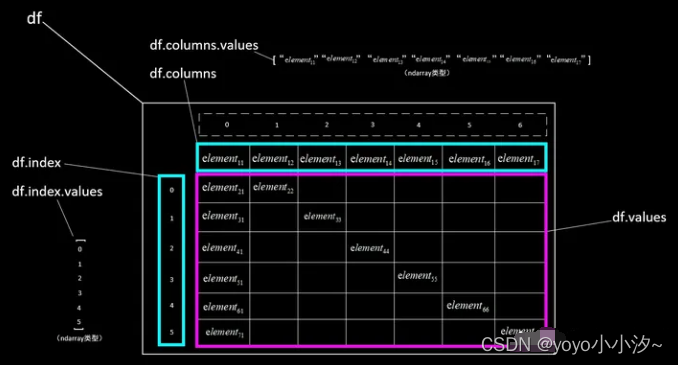
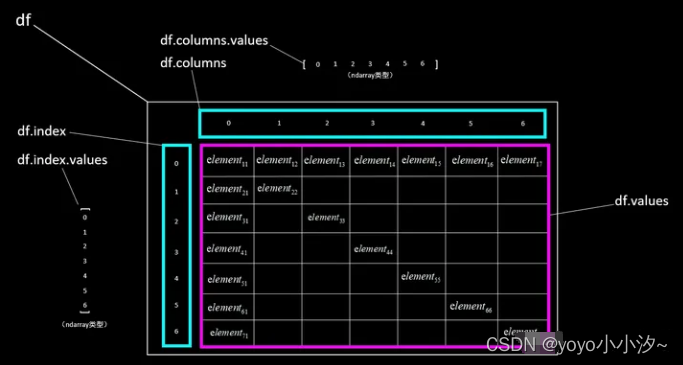
df.values,获取全部数据,返回类型为ndarray(二维);
df.index.values,获取行索引向量,返回类型为ndarray(一维);
df.columns.values,获取列索引向量(对有表头的方式,是表头标签向量),返回类型为ndarray(一维)。
根据具体需要,通过ndarray的使用规则获取指定数据。数据获取的结构示意图如下所示。
有表头
无表头
2.获取指定数据的写法
(1)获取全部数据:
df.values,获取全部数据,返回类型为ndarray(二维)。
(2)获取某个值:
df.values[i , j],第i行第j列的值,返回类型依内容而定。
(3)获取某一行:
df.values[i],第i行数据,返回类型为ndarray(一维)。
(4)获取多行:
df.values[[i1 , i2 , i3]],第i1、i2、i3行数据,返回类型为ndarray(二维)。
(5)获取某一列:
df.values[: , j],第j列数据,返回类型为ndarray(一维)。
(6)获取多列:
df.values[:,[j1,j2,j3]],第j1、j2、j3列数据,返回类型为ndarray(二维)。
(7)获取切片:
df.values[i1:i2 , j1:j2],返回行号[i1,i2)、列号[j1,j2)左闭右开区间内的数据,返回类型为ndarray(二维)。
3.示例
带表头,excel内容为
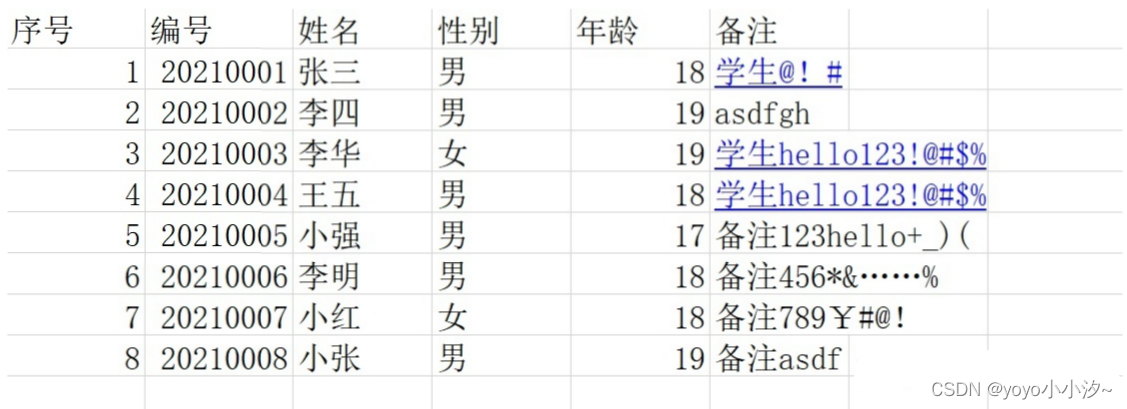
Python脚本为
`import pandas as pd
df = pd.read_excel("data_test.xlsx")
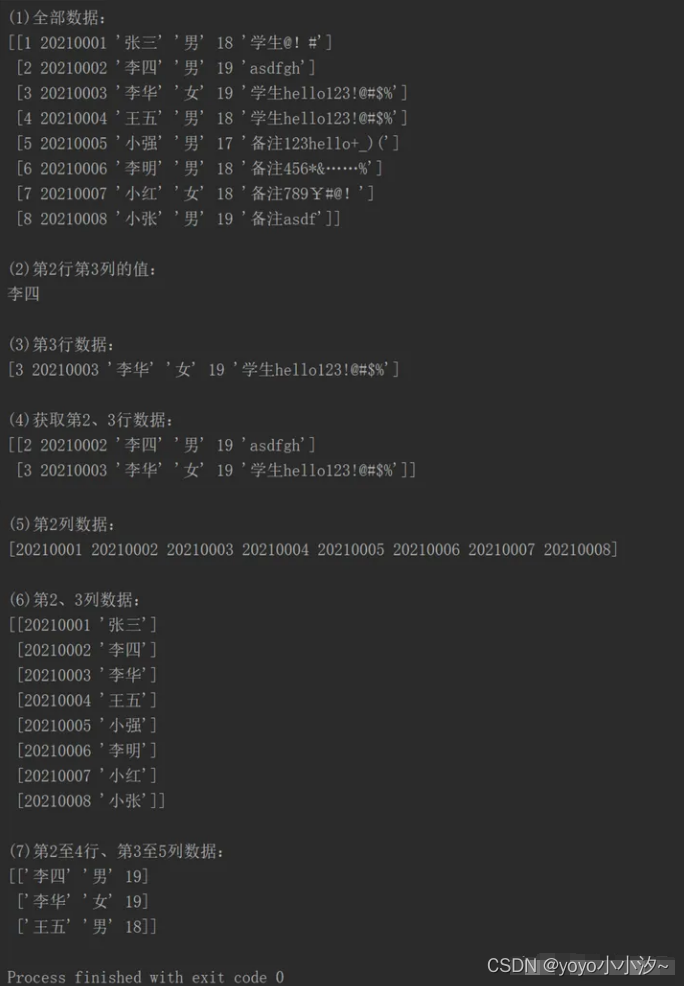
print("n(1)全部数据:")
print(df.values)
print("n(2)第2行第3列的值:")
print(df.values[1,2])
print("n(3)第3行数据:")
print(df.values[2])
print("n(4)获取第2、3行数据:")
print(df.values[[1,2]])
print("n(5)第2列数据:")
print(df.values[:,1])
print("n(6)第2、3列数据:")
print(df.values[:,[1,2]])
print("n(7)第2至4行、第3至5列数据:")
print(df.values[1:4,2:5])
执行结果
五、用loc和iloc方式获取数据
1.基本写法
loc和iloc方法是通过索引定位的方式获取数据的,写法为loc[A, B]和iloc[A, B]。其中A表示对行的索引,B表示对列的索引,B可缺省。A、B可为列表或i1:i2(切片)的形式,表示多行或多列。
这两个方法的区别是,loc将参数当作标签处理,iloc将参数当作索引号处理。也就是说,在有表头的方式中,当列索引使用str标签时,只可用loc,当列索引使用索引号时,只可用iloc;在无表头的方式中,索引向量也是标签向量,loc和iloc均可使用;在切片中,loc是闭区间,iloc是半开区间。
获取指定数据的写法:
(1)获取全部数据:
df.loc[: , :].values
或
df.iloc[: , :].values,返回类型为ndarray(二维)。
(2)获取某个值:
无表头
df.loc[i, j]
或
df.iloc[i, j],第i行第j列的值,返回类型依内容而定。
有表头
df.loc[i, "序号"],第i行‘序号’列的值。
或
df.iloc[i, j],第i行第j列的值。
(3)获取某一行:
df.loc[i].values
或
df.iloc[i].values,第i行数据,返回类型为ndarray(一维)。
(4)获取多行:
df.loc[[i1, i2, i3]].values,
或
df.iloc[[i1, i2, i3]].values,第i1、i2、i3行数据,返回类型为ndarray(二维)。
(5)获取某一列:
无表头
df.loc[:, j].values
或
df.iloc[:, j].values,第j列数据,返回类型为ndarray(一维)。
有表头
df.loc[:,"姓名"].values,‘姓名’列数据,返回类型为ndarray(一维)。
或
df.iloc[:, j].values,第j列数据,返回类型为ndarray(一维)。
(6)获取多列:
无表头
df.loc[:, [j1 , j2]].values
或
df.iloc[:, [j1 , j2]].values,第j1、j2列数据,返回类型为ndarray(二维)。
有表头
df.loc[:, ["姓名","性别"]].values,‘姓名’、‘性别’列数据,返回类型为ndarray(二维);
df.iloc[:, [j1 , j2]].values,第j1、j2列数据,返回类型为ndarray(二维)。
(7)获取切片:
无表头
df.loc[i1:i2, j1:j2].values,返回行号[i1,i2]、列号[j1,j2]闭区间内的数据,返回类型为ndarray(二维);
df.iloc[i1:i2, j1:j2].values,返回行号[i1,i2)、列号[j1,j2)左闭右开区间内的数据,返回类型为ndarray(二维)。
有表头
df.loc[i1:i2, "序号":"姓名"].values,返回行号[i1,i2]、列号["序号","姓名"]闭区间的数据,返回类型为ndarray(二维);
df.iloc[i1:i2, j1:j2].values,返回行号[i1,i2)、列号[j1,j2)左闭右开区间内的数据,返回类型为ndarray(二维)。
2.示例
带表头,excel内容为
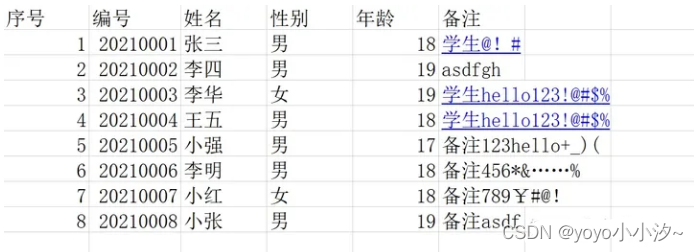
Python脚本为
`import pandas as pd
df = pd.read_excel("data_test.xlsx")
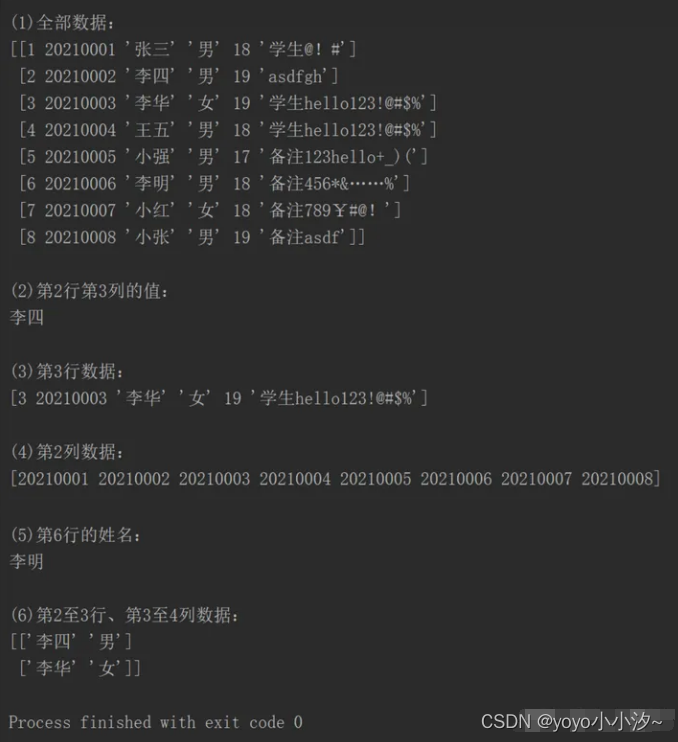
print("n(1)全部数据:")
print(df.iloc[:,:].values)
print("n(2)第2行第3列的值:")
print(df.iloc[1,2])
print("n(3)第3行数据:")
print(df.iloc[2].values)
print("n(4)第2列数据:")
print(df.iloc[:,1].values)
print("n(5)第6行的姓名:")
print(df.loc[5,"姓名"])
print("n(6)第2至3行、第3至4列数据:")
print(df.iloc[1:3,2:4].values)`
执行结果
最后: 为了回馈铁杆粉丝们,我给大家整理了完整的软件测试视频学习教程,朋友们如果需要可以自行免费领取 【保证100%免费】
全套资料获取方式:点击下方小卡片自行领取即可
