ABAP 新语法--Data Processing
1. String Template
新语法引入了字符串模板,用于处理字符串连接以及格式转换
字符串模板在 | … | 之间定义,主要分为两部分,固定文本和变量
其中,变量只能在 { … } 内使用,大括号之外的所有字符均作为固定文本使用,空格始终不会被忽略,见例1
在使用变量时,可以通过控制语句来指定数据的显示格式,如例2,将日期用系统格式输出
在固定文本中,如果出现 | ,{ } 或 等特殊字符时,需要使用转义符
DATA: lv_str TYPE char5 VALUE '123'.
" 在竖线中间没有被大括号包裹的部分将始终被视为固定文本,空格始终不被忽略
lv_str = | { lv_str }|.
WRITE: / lv_str.
lv_str = '123'.
" 尾部被截断
lv_str = |567{ lv_str }|.
WRITE: / lv_str.

2. Format Option
2.1 COUNTRY
根据指定国家 cty 格式化数据(数值/日期/时间),参考表 T005X 【 COUNTRY = cty 】
DATA lv_str TYPE string.
DATA lv_num TYPE p DECIMALS 3.
" country可以根据t005x国家的配置表自动选择合适的日期/时间/数值
DATA(lv_date) = CONV d( '20230614' ).
DATA(lv_time) = CONV t( '161810' ).
lv_num = '123456.123'.
WRITE: / '中国:'.
lv_str = |{ lv_date COUNTRY = 'CN ' }|.
WRITE: / lv_str.
lv_str = |{ lv_time COUNTRY = 'CN ' }|.
WRITE: / lv_str.
lv_str = |{ lv_num COUNTRY = 'CN ' }|.
WRITE: / lv_str.
WRITE: / .
WRITE: / '美国:'.
lv_str = |{ lv_date COUNTRY = 'US ' }|.
WRITE: / lv_str.
lv_str = |{ lv_time COUNTRY = 'US ' }|.
WRITE: / lv_str.
lv_str = |{ lv_num COUNTRY = 'US ' }|.
WRITE: / lv_str.

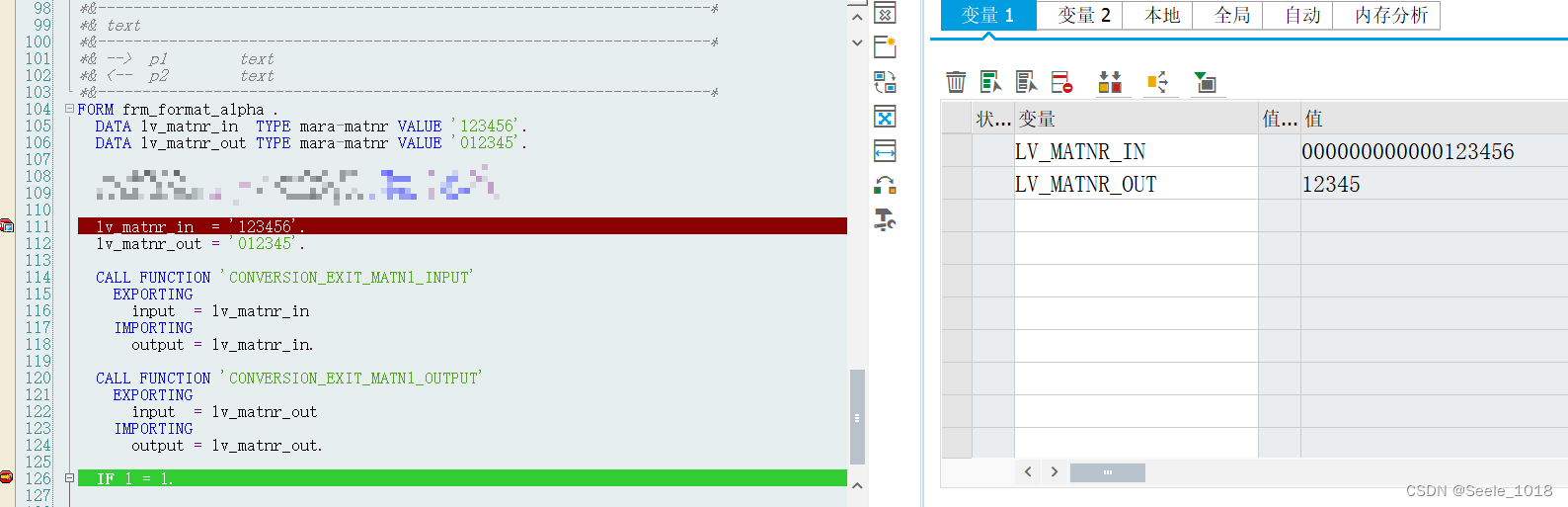
2.2 ALPHA
添加/移除前导零,返回值与字段类型一致,可使用CONV转换成其他的类型进行处理。默认不做变更(RAW)【 ALPHA = [ IN | OUT | RAW ] 】
以物料号加前导0作为示例
DATA lv_matnr_in TYPE mara-matnr VALUE '123456'.
DATA lv_matnr_out TYPE mara-matnr VALUE '012345'.
" 这种方式会直接按数据元素的长度补前导0
" 物料号直接补齐40位前导0,不太对劲
lv_matnr_in = |{ lv_matnr_in ALPHA = IN }|.
lv_matnr_out = |{ lv_matnr_out ALPHA = OUT }|.
lv_matnr_in = '123456'.
lv_matnr_out = '012345'.
" 这个是专用于料号编码转换的函数
" 删前导0无所谓两种方法都行,补前导0特殊字段特殊处理
CALL FUNCTION 'CONVERSION_EXIT_MATN1_INPUT'
EXPORTING
input = lv_matnr_in
IMPORTING
output = lv_matnr_in.
CALL FUNCTION 'CONVERSION_EXIT_MATN1_OUTPUT'
EXPORTING
input = lv_matnr_out
IMPORTING
output = lv_matnr_out.

2.3 CASE
将字符串进行大小写转换,默认为 RAW,该选项不会更改大小写格式【 CASE = [ RAW | LOWER | UPPER ] 】
" CASE 在String Template当中可以转换字母的大小写
DATA(lv_str) = 'AbCdEfG'.
WRITE / |{ lv_str CASE = LOWER }|. " 小写
WRITE / |{ lv_str CASE = UPPER }|. " 大写
WRITE / |{ lv_str CASE = RAW }|. " 默认
2.4 ZERO
" ZERO 关键字的存在类似与一个if else语句,若为0则置空,否则保留源字符串
DATA(lv_zero) = |{ 0 ZERO = NO }|.
DATA(lv_str) = |{ 123 ZERO = NO }|.
3. String Functions
3.1 STRLEN
获取字符串长度,当字符串类型为 CHAR 时,尾部空格会被忽略,当字符串类型为 STRING 时,尾部空格不会被忽略,仍会按字符被计入长度内
DATA(lv_strlen_c) = strlen( CONV char10( |1234567 | ) ). " 7
DATA(lv_strlen_s) = strlen( CONV string( |ACDEFGH | ) ). " 10
3.2 FIND
搜索指定字符串并计算偏移量,没有遍历到时返回 -1
可以使用 SUB ( 固定文本 ) 或者 REGEX ( 正则表达式 ) 作为指定条件进行搜索
CASE = [ abap_true | abap_false ]:大小写检查,默认为 abap_true,即区分大小写
OCC = N:指定字符串在第 N 次出现,当 N 是负数时,从字符串右边开始遍历
OFF = N LEN = M:指定搜索区域,从第 N+1 为字符开始长度为 M 的范围
DATA(lv_find_sub) = find( val = 'ABA123CAD' sub = 'a' case = ' ' occ = 3 ).
DATA(lv_find_reg) = find( val = 'ABA123CAD' regex = 'd' off = 0 len = 3 ).
3.3 COUNT
- COUNT
用法与 FIND 类似,但是返回值是指定字符串出现的次数,因此不能指定 OCC 参数 - COUNT_ANY_OF
计算指定字符串中的任一字符出现的总次数 - COUNT_ANY_NOT_OF
计算非指定字符串中任意字符出现的总次数
例:
DATA(lv_count) = count( val = 'ABA123CAD' sub = 'a' case = ' ' ).
DATA(lv_count_any) = count_any_of( val = 'ABA123CAD' sub = '1B' ).
DATA(lv_count_not) = count_any_not_of( val = 'ABA123CAD' sub = '1B' ).
3.4 REPLACE
替换字符串,可以指定位置进行替换,也可以查找指定字符串并替换
WITH = new 指定用于替换的字符串
OCC = N 指定字符串第 N 次出现时进行替换,N 为 0 时表示需要全部替换
其他参数可参照 FIND 表达式
例:
DATA(lv_replace) = replace( val = 'ABA123CAD' off = 0 len = 4 with = '@12@' ).
DATA(lv_replace_sub) = replace( val = 'ABA123CAD' sub = 'a' with = '@' case = ' ' ).
DATA(lv_replace_reg) = replace( val = 'ABA123CAD' regex = 'd' with = '#' occ = 0 ).
3.5 INSERT
插入字符串,可以使用 OFF 指定插入的位置,默认为 0
例:
DATA(lv_insert) = insert( val = 'ABCD' sub = '123' off = 2 ).
3.6 CONDENSE
压缩字符串,默认会移除头部/尾部的空格,其他部分的空格都会被压缩至 1 位
DEL = del 指定需要删除的字符,指定后,从字符串两侧开始遍历并删除字符,直到出现非指定字符
FROM = from TO = to 处理完 DEL 后,再遍历字符串,将 from 中出现的字符,替换成 to 的第一位字符
在遍历过程中,当同一个字符连续出现时,会被当成一个整体进行替换,所有字符均区分大小写
例:
DATA(lv_condense_space) = condense( | This is test | ).
DATA(lv_condense) = condense( val = ' XXThis ISSS X sTringXX'
del = |X |
from = 'TS'
to = 'to' ).
3.7 CONCAT_LINES_OF
将内表中所有的记录连接起来,通过 sep 指定分隔符
例:
DATA: lt_data TYPE TABLE OF char10.
lt_data = VALUE #( ( 'ABC' ) ( '123' ) ( 'DEF' ) ).
DATA(lv_concat_lines) = concat_lines_of( table = lt_data sep = '@' ).
3.8 REVERSE
字符串反转
例:
DATA(lv_reverse) = reverse( 'DEMO' ).
3.9 TO_UPPER/TO_LOWER
将字符串转换成大写/小写
例:
DATA(lv_to_mixed) = to_mixed( val = 'THIS is @A STRIN@G' sep = '@' case = 'X’ min = 10 ).
DATA(lv_from_mixed) = from_mixed( val = 'This IS a string' ).
DATA(lv_to_upper) = to_upper( val = 'this IS a string' ).
DATA(lv_to_lower) = to_lower( val = 'THIS IS A STRING' ).
4. Internal Table
4.1 Expressions
内表读取不再需要使用 READ TABLE,直接使用类似于数组的方式去读取
与READ TABLE读表方式类似,可以通过 INDEX 去读取指定位置的行,也可以根据条件去获取行,但无法指定BINARY SEARCH
默认情况下如果没有读到记录,会抛出异常 CX_SY_ITAB_LINE_NOT_FOUND
使用 OPTIONAL 语句时,没有读到记录也不会抛异常,而是返回空的结构
使用 DEFAULT 语句,在没有读到记录时,返回一个默认值,如果系统不支持这两种,则需要使用 TRY 语句来捕获异常
SELECT carrid, connid, countryfr, cityfrom
FROM spfli INTO TABLE @DATA(lt_table) UP TO 3 ROWS.
DATA(lv_line_index) = lt_table[ 1 ]-carrid.
DATA(lwa_line_field) = lt_table[ carrid = 'AZ'
connid = '0555' ].
DATA(lwa_line_optional) = VALUE #( lt_table[ 4 ] OPTIONAL ).
DATA(lwa_line_default) = VALUE #( lt_table[ 4 ] DEFAULT VALUE #( carrid = 'ZZ'
connid = '0239'
countryfr = 'SU'
cityfrom = 'CITY_NO' ) ).
4.2 Functions
LINES 计算内表总行数
LINE_EXISTS 判断根据特定条件能否在内表中读取到记录,返回值为布尔型数据
LINE_INDEX 获取内表中满足特定条件的记录所在的行数( INDEX )
例:
SELECT * FROM spfli INTO TABLE @DATA(lt_table) UP TO 3 ROWS.
DATA(lv_lines) = lines( lt_table ).
DATA(lv_exist) = xsdbool( line_exists( lt_table[ carrid = 'AZ' ] ) ).
DATA(lv_index) = line_index( lt_table[ carrid = 'AZ' ] ).