【分布式架构的原理】淘宝的演进过程
目录结构
一、分布式架构的原理:
1. 高并发,大流量
google的日平均pv(35亿),page view,日平均独立访问(ip),3亿。qq/wx的最大在线用户数2019年春节8亿。
2. 高可靠,高可用
系统全年365天不间断运行。阿里云服务器提供99.9999%,一年不超过32秒的服务中断。
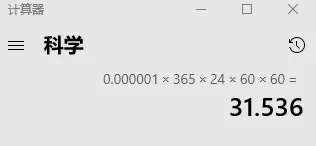
集群备份,异地容灾
3. 海量数据存储
facebook每天上传照片10亿张。腾讯每天8亿张。海量数据存储需要硬件和软件支持。(磁盘阵列,HDFS(mapreduce),分布式文件系统,TFS 阿里和腾讯自建的分布式文件系统。)
服务器的部署场景:
- 本地部署 (自己建机房,自己买机房的配套设备,安全性高)
- 公有云 (普通的中小型企业和普通用户)
- 私有云(通过专线访问,安全性高于公有云)
- 入住酒店,房间就是公有云,弹性扩展,不需要自己维护。
- 租房相当于私有云,房间是专属你。
- 本地化部署。自己买房,自己装修,安全自己负责。
4. 用户分布广,网络情况复杂
用户分布在全世界,每个国家的网络情况不同。针对不同的网络,提供不同的服务。
5. 网络安全环境恶劣
互联网是开放性的,大型的知名网站每天都在遭受网络攻击。
6. 需求变更频繁,版本迭代快
用户达到5000W经过了多少时间(获客):
| 名称 | 时间 |
|---|---|
| 电话 | 75年 |
| 广播 | 38年 |
| 电视 | 13年 |
| 互联网 | 4年 |
| 3年 | |
| Google+ | 88天 |
| 王者荣耀 | 24天 |
版本更新
好的系统不是设计出来的,是改出来的。
二、大型网站的发展演变过程(淘宝)
1. 原始阶段
淘宝网站诞生在马云家里,去国外买了一个电商网站(php+mysql),只有一台服务器。
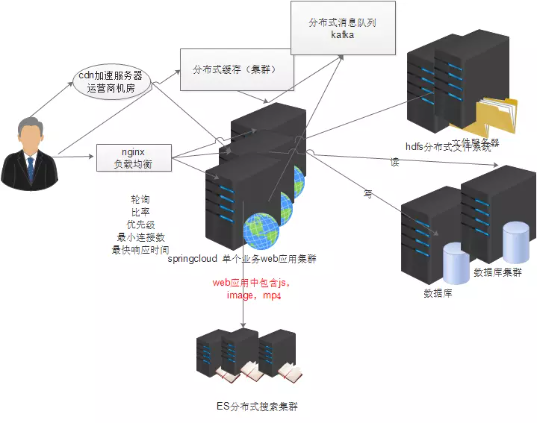
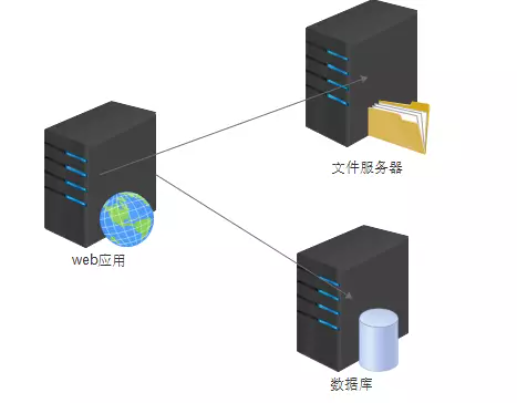
2. 应用服务和数据分离
随着业务扩展,用户量上升,一台服务性能不够,需要把数据库和文件存储拆分。
3. 加入缓存 提升网站访问速度
在互联网有个规律,二八定律,经常访问的数据只占20%,80%的数据不经常访问,一般将20%的数据放入到缓存中。提高缓存的命中率。
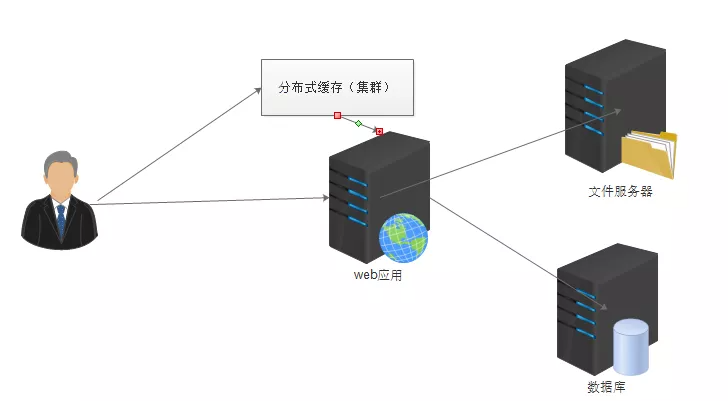
4. 使用服务器集群避免单点故障
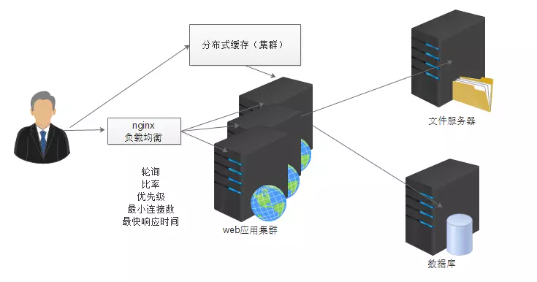
软件的负载均衡使用的是nginx
有钱的企业,购买硬件的负载均衡(F5)
5. 使用数据库集群
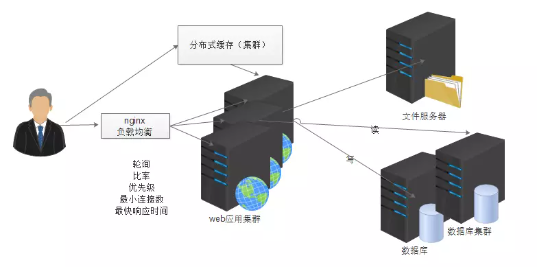
mycat实现数据库的读写分离,和分库分表
6. 使用cdn加速网站响应
CDN的全称是Content Delivery Network,即内容分发网络。CDN是构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。CDN的关键技术主要有内容存储和分发技术。
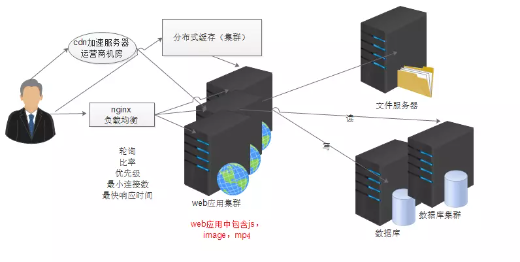
7. 使用分布式文件系统
文件服务器存在单点故障,并且存在容量限制
使用hdfs分布式文件系统,理论上没有容量限制,并且提供附件副本的备份。
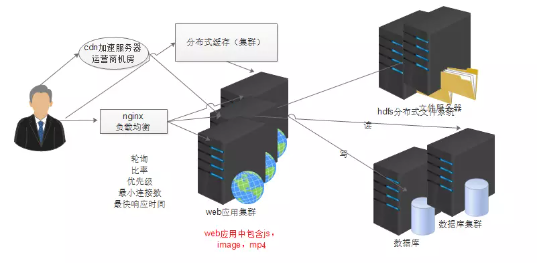
8. 使用分布式搜索引擎
解决海量数据的快速搜索,例如淘宝的商品搜索,github的代码搜索,百度的新闻搜索,Lucene,slor,ES(elasctic search)
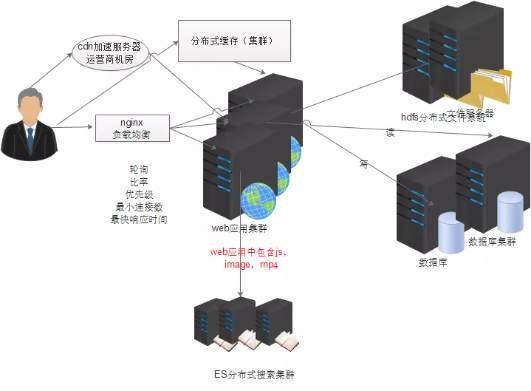
9. 业务拆分
之前的垂直架构项目,修改一个模块,整个项目需要重新打包部署,并且各个模块相互依赖。存在资源浪费。
每个业务独自建立一个工程,修改单个业务的时候,只需重新编译上线单独的服务器,对其他服务器不影响。
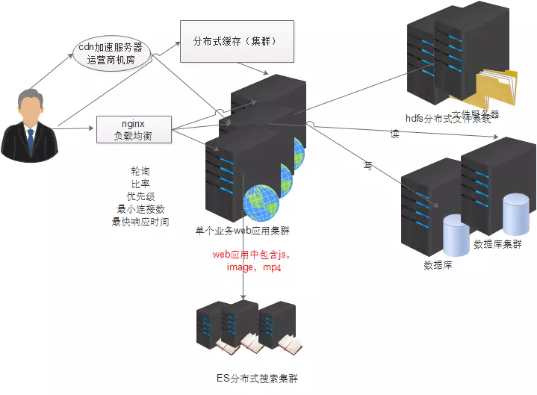
10. 使用分布式框架解决服务治理问题
上面的业务拆分,后果就是出现了一大堆的各种服务,没有一个人能够理清。