常用重点【字符串函数】和【内存函数】总结(万字)
目录
秃头侠们好呀,今天来聊聊字符串函数和内存函数
本章重点
求字符串长度
strlen
长度不受限制的字符串函数
strcpy
strcat
strcmp
长度受限制的字符串函数介绍
strncpy
strncat
strncmp
字符串查找
strstr
strtok
错误信息报告
strerror
字符操作
内存操作函数
memcpy
memmove
memset
memcmp
注意一下:
C语言中对字符和字符串的处理很是频繁,但是C语言本身是没有字符串类型的,字符串通常放在 常量字符串 中或者 字符数组 中。 字符串常量 适用于那些对它不做修改的字符串函数
字符串函数
strlen
strlen 求字符串长度
size_t strlen ( const char * str );
- 字符串以 ‘’ 作为结束标志,strlen函数返回的是在字符串中 ‘’ 前面出现的字符个数(不包含 ‘’ )。
- 参数指向的字符串必须要以 ‘’ 结束。
- 注意函数的返回值为size_t,是无符号的( 易错 )
- 学会strlen函数的模拟实现(比如用:
递归,计数器,指针-指针等方法)
递归 方法
//递归
int my_strlen(char* s)
{
if (*s != '')
{
return 1 + my_strlen(s + 1);
}
else
{
return 0;
}
}
指针-指针 方法
//指针-指针
int my_strlen(char* s)
{
char* head = s;
while (*s!='')
{
s++;
}
size_t ret = s - head;
return ret;
}
计数器 方法
//计数器
int my_strlen(char* s)
{
int count = 0;
while (*s!='')
{
count++;
s++;
}
return count;
}
递归和计数器方法对于大家来说都很easy~
主要来说一下指针-指针的方法
首先我们得知道指针减指针的前提是
两指针必须是指向同一块连续的空间地址
两指针相减得到的是两指针之间元素个数
我想你应该明白我的意思
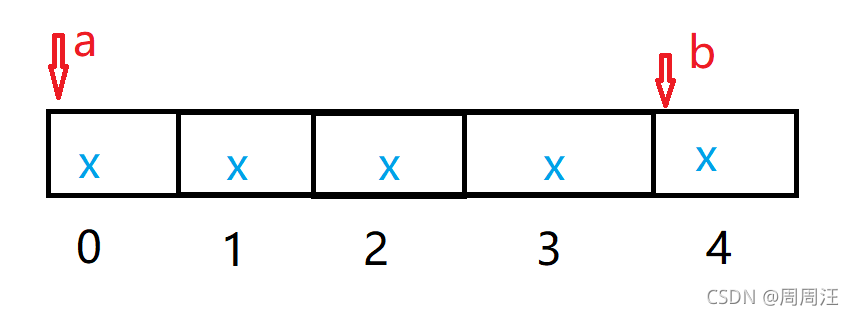 指针b减指针a得到的他们之间的元素个数是4
指针b减指针a得到的他们之间的元素个数是4
(注意不是他们地址数值的差,是元素个数)
我们来看一个代码
#include <stdio.h>
int main()
{
const char* str1 = "abcdef";
const char* str2 = "bbb";
if (strlen(str2) - strlen(str1) > 0)
{
printf("str2>str1n");
}
else
{
printf("srt1>str2n");
}
return 0;
}
想必你也猜到事情并不简单
认真看strlen的返回类型是什么?
size_t!!!
所以size_t减size_t还是size_t类型,而size_t是无符号整形所以恒>=0
strcpy
strcpy字符串拷贝
char* strcpy(char * destination, const char * source );
- 把source的源字符串拷贝到destination的目标空间
- 从头到都要拷贝,包括
- source必须是一个字符串,以结尾
- destination的空间必须足够大,能放得进去source
- destination必须是可修改的
- 模拟实现strcpy
//模拟实现
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
char* my_strcpy(char* dest, const char* sor)
{
char* s = dest;
while (*dest++=*sor++)
{
;
}
return s;
}
int main()
{
char a[100] = "xxxxxxxxx";
const char* s = "abcd";
char* ret = my_strcpy(a, s);
printf("%sn", ret);
return 0;
}
strcat
strcat字符串连接(追加)
char * strcat ( char * destination, const char * source );
- 将源字符串追加到目标字符串后面,源字符串的第一个元素会覆盖目标字符串末尾的
,两个字符串由此连接在一起 - 源字符串必须以
结尾 - 目标空间必须有足够的大,能容纳下源字符串的内容
- 目标空间必须可修改
- 模拟实现
//模拟实现
char* my_strcat(char* dest, const char* src)
{
assert(dest && src);
char* s = dest;
while (*dest)
{
dest++;
}
while (*dest++ = *src++)
{
;
}
return s;
}
strcmp
strcmp字符串比较
int strcmp ( const char * str1, const char * str2 );
- 第一个字符串大于第二个字符串,则返回大于0的数字
- 第一个字符串等于第二个字符串,则返回0
- 第一个字符串小于第二个字符串,则返回小于0的数字
- 从两个字符串的第一个字符开始比较,比较的是字符对应ASCII值的大小
- 注意不是比较字符串长短(比如:abc>ababcde,前面ab相同第三个字符c大于a所以前者大于后者)
- 模拟实现
//模拟实现
int my_strcmp(const char* s1, const char* s2)
{
while (*s1==*s2)
{
if (*s1 == '')
return 0;
s1++;
s2++;
}
return s1 - s2;
}
上面这3个有关字符串的函数
strcpy
strcat
strcmp
这三种形式是长度不受限制的字符串函数,不够严谨安全,存在缓冲区溢出的漏洞,所以在某些高级点的编译器会提醒你说,这种字符串函数不安全,让你使用
strcpy_s
strcat _s
strcmp_s
但是这种形式是针对不同编译器的,在不同编译器上可能无法同样适应,
没有很好的跨平台性,
所以为了安全起见,有了
strncpy
strncat
strncmp
这三个是长度受限制的字符串函数,相对更加安全一点(不是绝对哦)
那么strcpy strcat strcmp为什么不安全?
下面用strcpy来验证一下
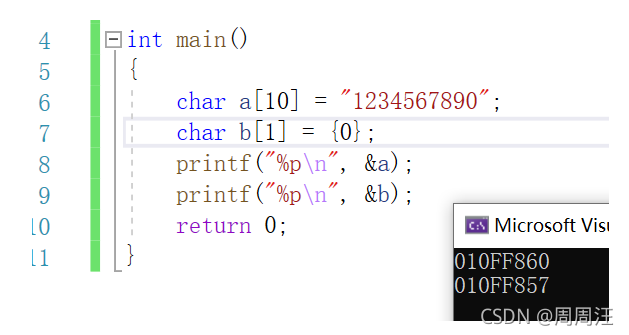
根据这两个变量的地址,我们画出C程序地址空间图(main函数是在栈上开辟的,在栈中,先使用高地址,后使用低地址)
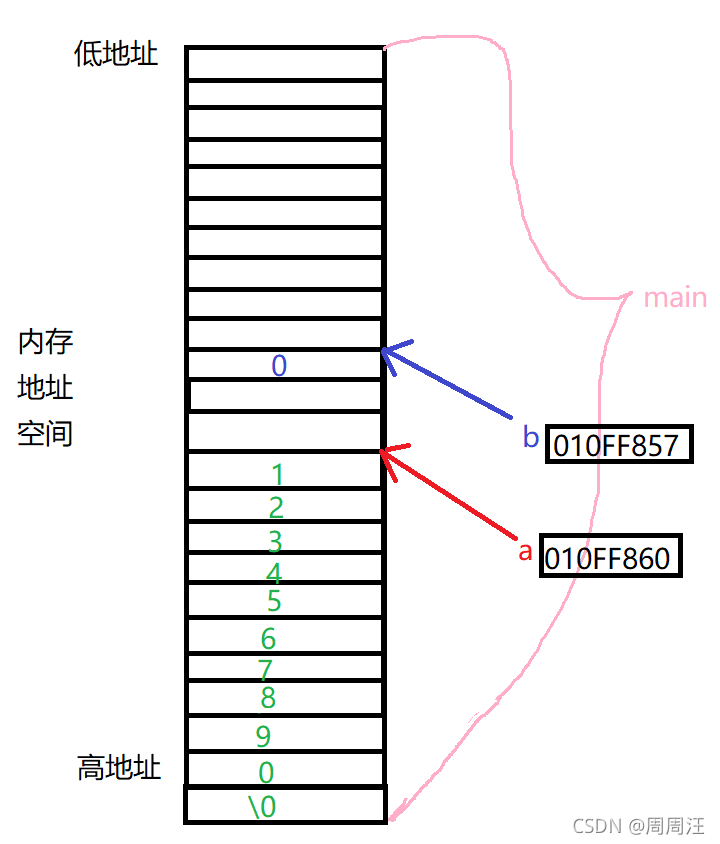
如果我们strcpy(b,a);
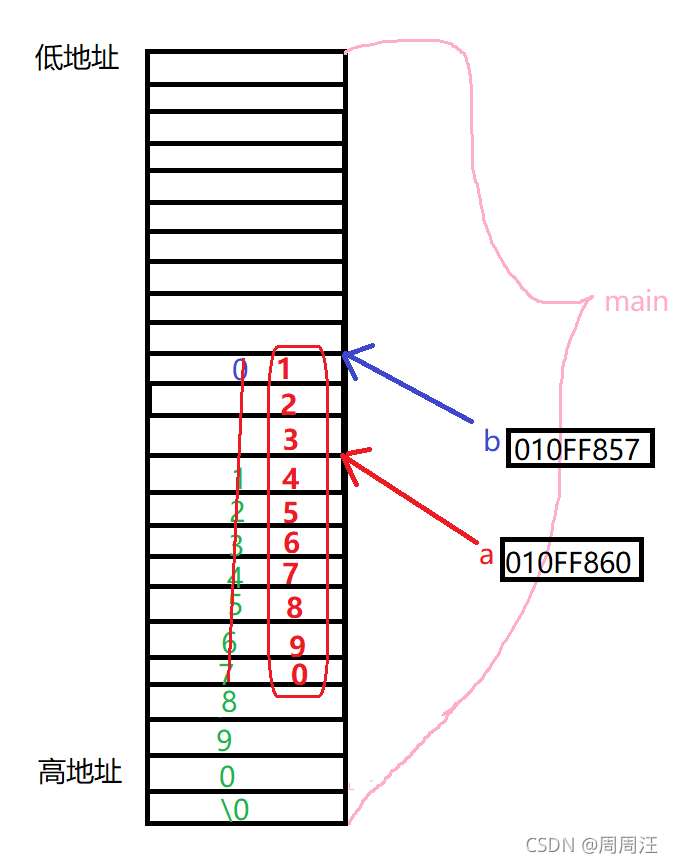
可以看到b变量如果开辟的空间不够大的话,当把字符串a拷贝到b中时,a的首元素内容被覆盖修改,这是不允许的。
strncpy
char * strncpy ( char * destination, const char * source, size_t num );
- 跟strcpy其实一样,就是多了个参数:从源字符串拷贝到目标空间的字符数量num
- 如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后边追加0,直到num个
- strncpy模拟实现
char* my_strncpy(char* dest, const char* src, size_t count)
{
assert(dest && src);
char* ret = dest;
int str = strlen(src);
for (size_t i = 0; i < count; i++)
{
//如果count大于src个数,要补为''
if (i >= str)
{
*dest = '';
dest++;
}
else
{
*dest = *src;
dest++;
src++;
}
}
return ret;
}
strncat
char * strncat ( char * destination, const char * source, size_t num );
- 同样跟strcat相同,也是增加了一个参数:追加源字符串的num个字符
- 记得不管追加几个,最后要以结尾
- 如果num大于source字符串的字符数量,相当于全部追加,没有影响
- strncat模拟实现
char* my_strncat(char* dest, const char* src, size_t num)
{
assert(dest && src);
char*ret= dest;
int str = strlen(src);
while (*dest!='')
{
dest++;
}
for (size_t i = 0; i < num; i++)
{
if (i >= str)
{
break;
}
*dest = *src;
dest++;
src++;
}
*dest = '';
return ret;
}
strncmp
int strncmp ( const char * str1, const char * str2, size_t num );
- 也是和strcmp一样,只是多个参数:比较两字符串的num个字符
- strncmp模拟实现
int my_strncmp(const char* str1, const char* str2, size_t num)
{
assert(str1 && str2);
int i = 0;
for (int i = 0; i < num; i++)
{
if (*str1 == *str2)
{
str1++;
str2++;
}
else
{
break;
}
}
if (i == num)
{
return 0;
}
return *str1 - *str2;
}
strstr
strstr字符串查找函数
char * strstr ( const char *str1, const char *str2 );
- 查找一个字符串是否是另一个字符串中的某段子字符串
- 如果找到,返回找到位置的地址
- 如果没找到,返回NULL;
- strstr模拟实现
int my_strstr(const char* str1, const char* str2)
{
assert(str1 && str2);
if (strlen(str1) < strlen(str2))
return NULL;
char* s1;
char* s2;
char* cp = str1;
if (*str2 == '')
return str1;
while (*cp)
{
s1 = cp;
s2 = str2;
while (*s1&&*s2&&*s1==*s2)
{
s1++;
s2++;
}
if (*s2 == '')
return cp;
cp++;
}
return NULL;
}
strtok
strtok切割字符串
char * strtok ( char * str, const char * sep );
- sep参数是个字符串,定义了用作分隔符的字符集合
- 第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标记
- strtok函数找到str中的下一个标记,并将其用 结尾,返回一个指向这个标记的指针。(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
- strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置
- strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
- 如果字符串中不存在更多的标记,则返回 NULL 指针
光说定义还是不太好理解,下面举个例子
#include <stdio.h>
int main()
{
char* p = "hello@world.hehe";
const char* sep = ".@";
char arr[30];
char* str = NULL;
strcpy(arr, p);//将数据拷贝一份,处理arr数组的内容,不想破坏原字符串
for (str = strtok(arr, sep); str != NULL; str = strtok(NULL, sep))
{
printf("%sn", str);
}
}
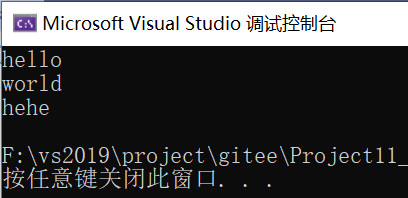
一般这个函数就是这么用的
for循环,str = strtok(arr, sep),第一个参数不是NULL,所以找到第一个标记处@,将其换成’’,保存记住这个位置,然后返回arr首元素地址,现在字符串是这样的h e l l o w o r l d . h e h e 。所以打印一下打印出hello。调整str = strtok(NULL, sep)传入NULL,是从刚才记忆的位置往后找到下一个标记 . 处换成’’,记住这个位置,然后返回上次记忆的位置也就是@这个位置,现在字符串是w o r l d h e h e ,所以打印出来world。最后再调整,传入NULL,找到下一个标记处,没有下一个标记了,返回上次记忆位置,现在字符串是h e h e ,所以打印hehe,因为没有下一个标记了,最后返回NULL,出for循环。
strerror
strerror返回错误代码所对应的错误信息(字符串)
char * strerror ( int errnum );
下面举例一个应用场景
#include <stdio.h>
#include <string.h>
#include <errno.h>//必须包含的头文件
int main()
{
FILE* pFile;
pFile = fopen("unexist.ent", "r");
if (pFile == NULL)
printf("Error opening file unexist.ent: %sn", strerror(errno));
//errno: Last error number
return 0;
}
//error当错误时,会生成一个错误码放在error中
还有一个更简便的函数:perror(s)
perror(s);
这个函数会直接打印你的错误,相当于你不用printf了,这个函数会先打印出s参数你给的字符串,然后打印出错误信息
比如:
perror(“错误信息:”);
错误信息:。。。。。
内存函数
memcpy
void * memcpy ( void * destination, const void * source, size_t num );
- 函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置
- 这个函数在遇到 ‘’ 的时候并不会停下来
- 如果source和destination有任何的重叠,复制的结果都是未定义的
- 前两个参数都是void类型,这样是因为void是万能指针,可以接受任何类型的指针
#include <stdio.h>
#include <string.h>
struct {
char name[40];
int age;
} person, person_copy;
int main()
{
char myname[] = "Pierre de Fermat";
// using memcpy to copy string:
memcpy(person.name, myname, strlen(myname) + 1);
person.age = 46;
// using memcpy to copy structure:
memcpy(&person_copy, &person, sizeof(person));
printf("person_copy: %s, %d n", person_copy.name, person_copy.age);
return 0;
}
//模拟实现memecpy
void* my_memcpy(void* dest, const void* src, size_t count)
{
void* ret = dest;
while (count--)
{
*(char*)dest = *(char*)src;//注意一下这里比较关键
dest = (char*)dest + 1;
src = (char*)src + 1;
}
return ret;
}
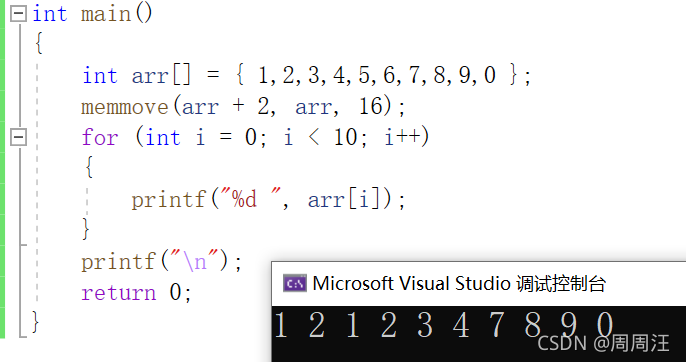
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,0 };
my_memcpy(arr + 2, arr, 16);
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
printf("n");
return 0;
}
这里有一个问题
我们的想法是让1,2,3,4 copy到3,4,5,6这里,
最后打印1,2,1,2,3,4,7,8,9,0
但我们看结果

为什么会出现这样的结果?
答:你想啊,我们是先把1拷贝到3,把2拷贝到4,当我们想把3拷贝到5,和4拷贝到6的时候,这时的3,4位置已经变成了1,2,所以这是问题的关键!
所以memcpy这个函数没法处理内存重叠的拷贝问题,我们应该用memmove函数,下面我们就说说这个函数
memmove
void * memmove ( void * destination, const void * source, size_t num );
- 和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的
- 如果源空间和目标空间出现重叠,就得使用memmove函数处理
我们看到memmove就没有刚才说的问题
//模拟实现memmove
void* my_memmove(void* dest, const void* src, size_t count)
{
assert(dest && src);
void* ret = dest;
if (dest < src)
{
//前->后,从前往后拷贝
while (count--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
}
else
{
//后->前,从后向前拷贝
while (count--)
{
*((char*)dest + count) = *((char*)src + count);
}
}
return ret;
}
memcmp
memcmp内存比较
int memcmp ( const void * ptr1, const void * ptr2, size_t num );
- 比较从ptr1和ptr2指针开始的num个字节
- 跟strcmp类似,只是这个是按字节比较,不一定是字符串
- 返回值和strcmp的类似
memset
memset内存设置
void * memset ( void * ptr, int value, size_t num );
- 把内存中按字节,全设置为value这个值
比如:
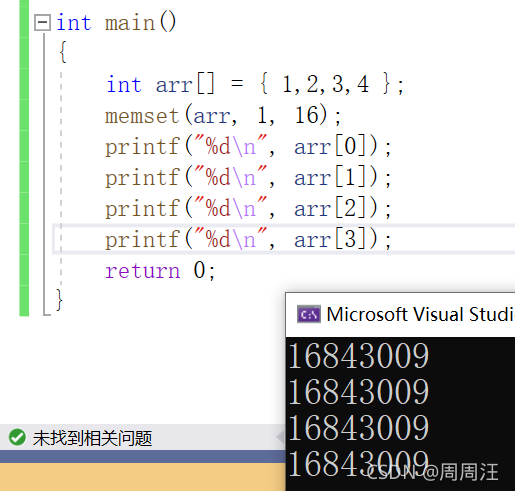
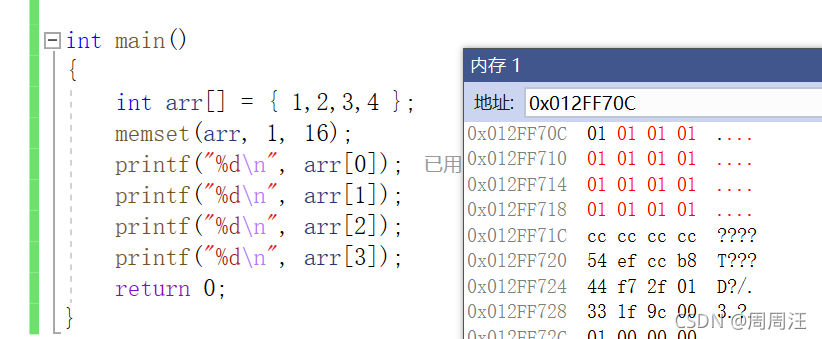
为什么打印的是这个数,因为它不是把这个整型设置成1,而是每个字节设置成01,看下面
这期就到这里啦,感谢阅读,我们下期再见
如有错 欢迎提出一起交流
关注周周汪哦
关注三连么么么哒