长安链大规模数据存储及数据膨胀分析
区块链可追溯、不可篡改的特性要求系统内每个节点保存一份数据,且数据量日益增长,这对于部分大数据量系统中的海量数据存储及导致的数据处理效率降低带来了挑战,这其中就需要考虑数据在实际存储中的膨胀问题。
区块存储流程
要理解数据膨胀问题,首先了解以下长安链的区块存储方式及流程。⻓安链在v2.2以后开始⽀持区块⽂件存储,适合区块数据库⼤于400GB以后的场景,采⽤与之前⽅案不同的区块存储⽅式以解决⽇益增⻓的区块数据导致节点速度变慢的问题:将区块数据直接顺序放到磁盘中,同时建⽴区块存放位置的索引,将索引信息放置到区块数据库中,在读取区块数据(区块/交易/读写集)时直接从⽂件中截取,然后反序列化返回,极大减轻了kv数据的存储压力。
当前区块写⼊架构图如下:
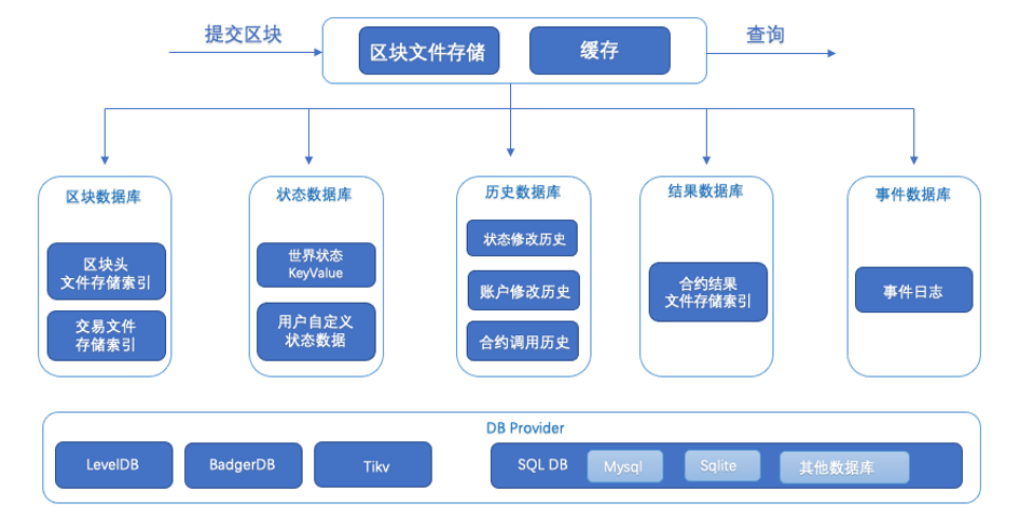
图1
数据膨胀的产生
这里我们理解的“数据膨胀”不同于链上的“数据增长”。在区块链的运行过程中,我们通常是以交易为操作单位,但是在存储过程中我们不能只是记录交易信息。就像旅客出门有行李,考虑汽车上载人的数量和耗油的时候还需要额外考虑乘客行李的尺寸和重量。为了更好的组织链上的交易,我们需要使用区块将交易组织起来,同时交易中也需要包含除了纯粹交易信息以外的内容。所以区块中就多了区块头,交易中就多了一些交易参数,如:chainId, TxType等。此时存储一个交易就附带的很多内容(就像旅客的行李),这就产生了数据膨胀。本篇文章对长安链在实际存储过程中数据膨胀的原因和实际膨胀大小做一次简单的探讨。
⽂件存储结构
在区块链中总是以区块为前进的单位。我们说区块链运行了多远,一般都会说区块链的高度是xxx了,比如某链高度到达15389182了,实际意思是说这条链当前已经处理和存储了15389182个区块链了。长安链也是如此,每一个区块运行之后都会通过长安的存储模块最后存储到磁盘上。长安链在区块实际存储过程中发现:以往的区块数据直接存储在KV数据库的方式会导致数据库(如:leveldb)压力过大,而且在一定存储量之后出现数据库无论是写入还是查询效率都急剧下降的问题。为了解决这个问题,长安链自主开发了基于文件存储的区块存储方式:将区块数据放入到自研的文件存储,然后将相关的索引放入KV数据库(如:leveldb)中。改良之后测试发现,数据库的压力急剧降低,在已经测试的16TB的存储量下(单节点单leveldb),存储模块性能也毫不下降。那么长安链的存储模块到底是如何存储的呢?
1.区块在到达存储模块后会进行序列化操作,为下一步区块数据落盘做准备,此时我们将区块对象中的子对象单独序列化,同时记录序列化产生字节流的长度,然后再拼接起来,就是一个序列化之后的完整区块的字节流。
2.在序列化和拼接的时候记录子对象在区块字节流的偏移量和长度,即: 某子对象在整个区块字节流的起始位置和长度,在反序列化字节流成对象的时候直接截取区块指定位置特定长度的片段,再反序列化,即可得到原始对象。
3.在读取区块/交易/读写集/事件日志时,从KV数据库中获取区块所在的fdb文件名和在该文件中的起始和长度,然后再反序列化即可。
4.长安链在文件存储中定义了区块存储的文件.fdb文件,用于存放每次产生的区块文件。
5.文件存储结构图如下:
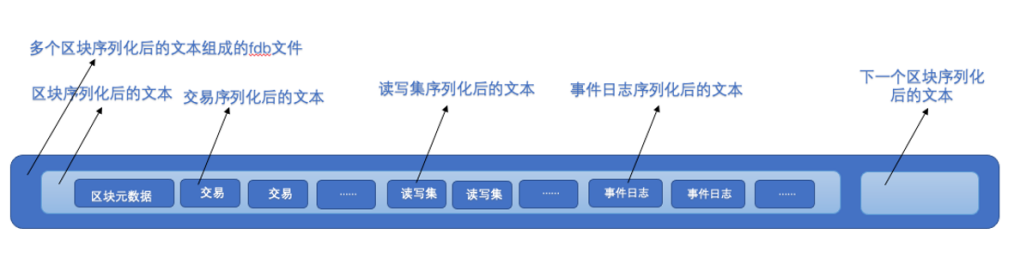
图2
KV存储schema及size
KV存储是前面区块写入架构图(图1)的下面半截的部分的数据的存储,从图中可以看到存储主要分为分为blockdb、statedb、historydb、resultdb四个数据库。在关系型数据库中,数据一般以表为单位进行组织管理,这种表的关系和属性就是schema,而长安链采用的是leveldb类型的非关系型数据库中,在数据的组织中也有一套自己的schema。下面列出每个数据库的schema结构,同时在后面的注释中标记出每对KV在本次测试统计中的实际存储大小。
blockdb
batch.Put([]byte(lastBlockNumKeyStr), lastBlockNumBytes) lastBlockNumKey block.Header.BlockHeight //len: key 15, value 1
batch.Put(blockIndexKey, blockIndexInfo) //len: key 3, value 29
batch.Put(metaIndexKey, metaIndexInfo) //len: key 3, value 29
batch.Put(hashKey, encodeBlockNum(block.Header.BlockHeight)) //len: key 33, value 1
for --
batch.Put(blockTxIdKey, txBlockInf) //len: key 65, value 39
--
batch.Put([]byte(lastConfigBlockNumKey), heightKey) //配置区块才会有 len: key 21, value 1
statedb
batch.Put([]byte(stateDBSavepointKey), lastBlockNumBytes) //len: key 19, value 8
for --
batch.Put(txWriteKey, txWrite.Value) //len: key 56, value 4 // contract_name_count_rust#count#B_0_0_1660100497149619000
--
historydb
batch.Put([]byte(historyDBSavepointKey), lastBlockNumBytes) //len: key 19, value 8
for --
batch.Put(constructKey(write.ContractName, write.Key, blockHeight, txId, txIndex), []byte{0}) //len: key:127 value: 1 kcontract_name_count_rust#count#B_0_0_1660100497149619000#21#0$1709dc9b4813eb48ca4c926abcc8de5f9fd7c4c863d547da9459dfab24c2b298
--
//本次测试未开启该模块存储
// for --
// batch.Put(constructAcctTxHistKey(accountId, blockHeight, txId), []byte{0}) //len: key: 14+64=78 value: 1
// batch.Put(constructContractTxHistKey(contractName, blockHeight, txId), []byte{0}) //len: key: 4+64=68 value: 1
// --
resultdb
batch.Put([]byte(resultDBSavepointKey), lastBlockNumBytes) //len: key 18, value 8
for --
batch.Put(rwSetIndexKey, rwIndexInfo) //len: key: 2+64=66 value: 29
--
区块对象空间占⽤详细分析
本次统计使⽤的是counter-rust.wasm合约,对应的交易⼤⼩为4KB 膨胀率(公众号对话框回复【数据膨胀】获取原图)。
以下图片可点击放大
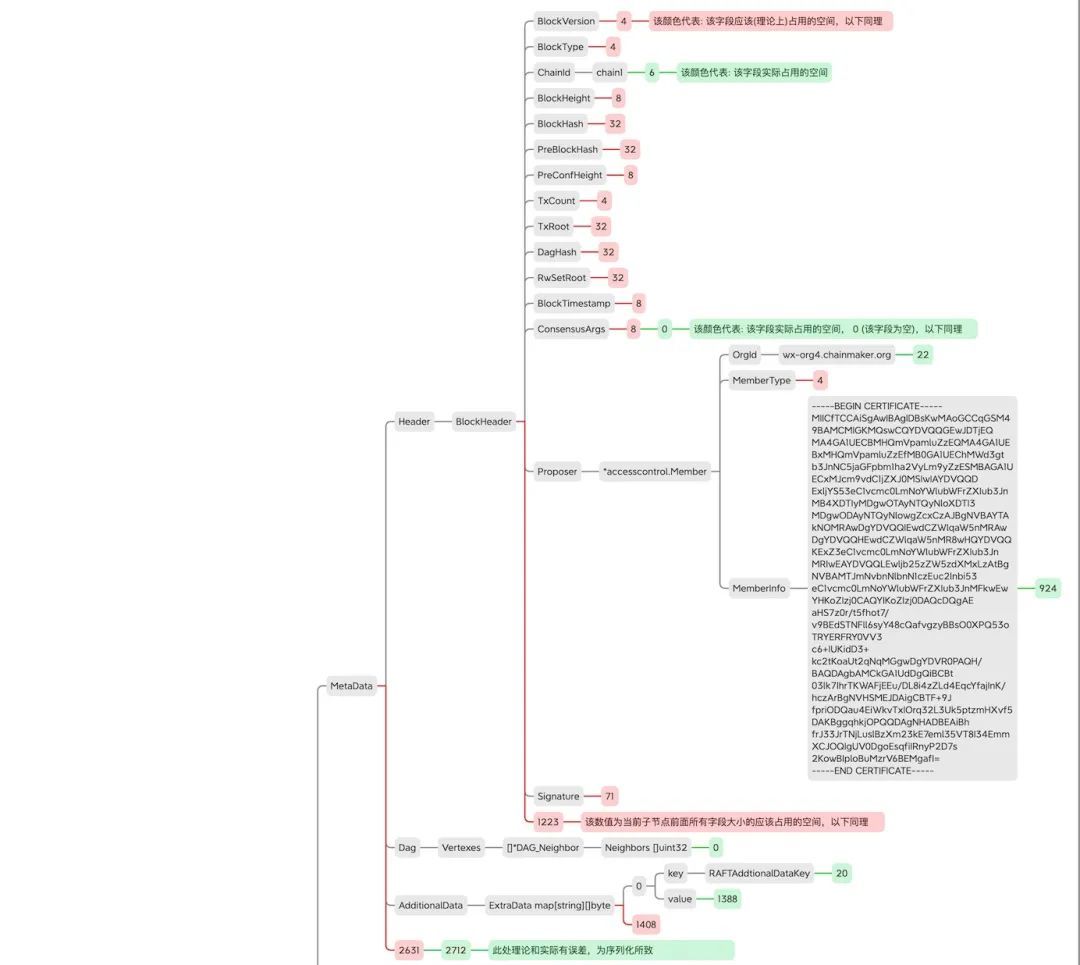
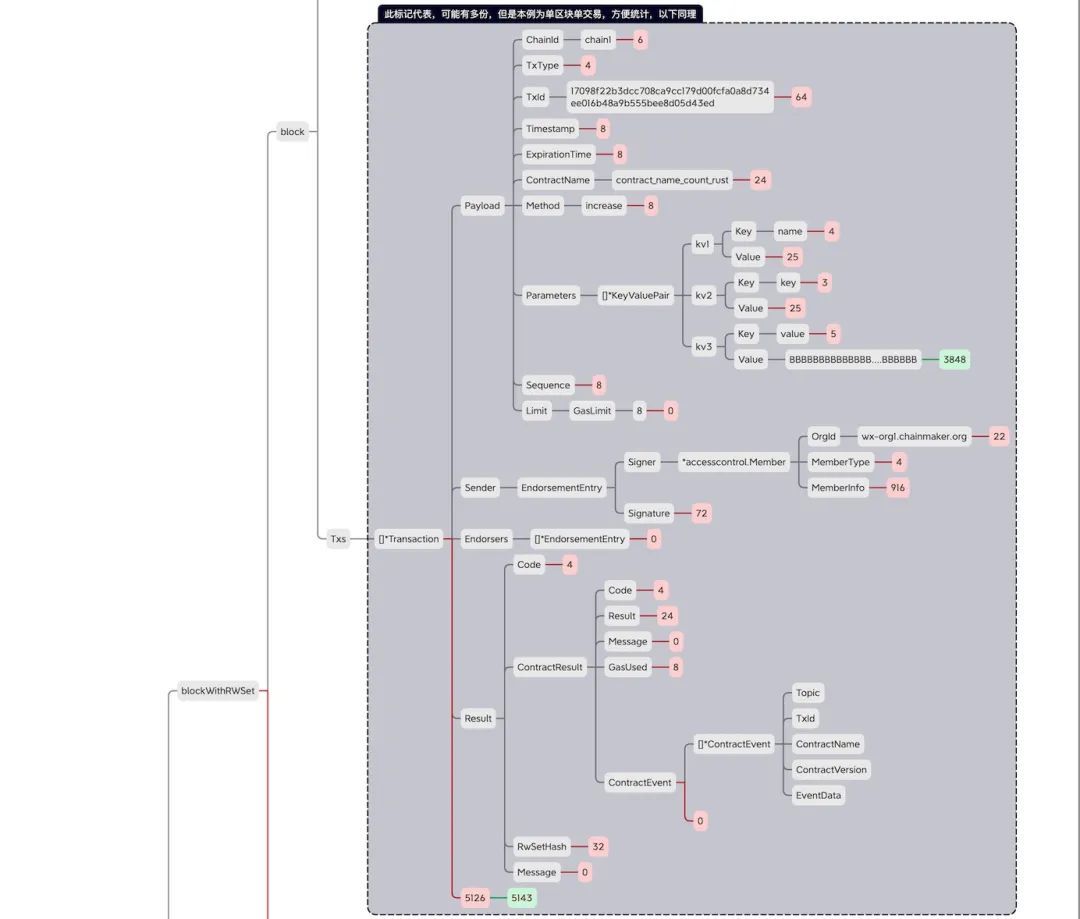
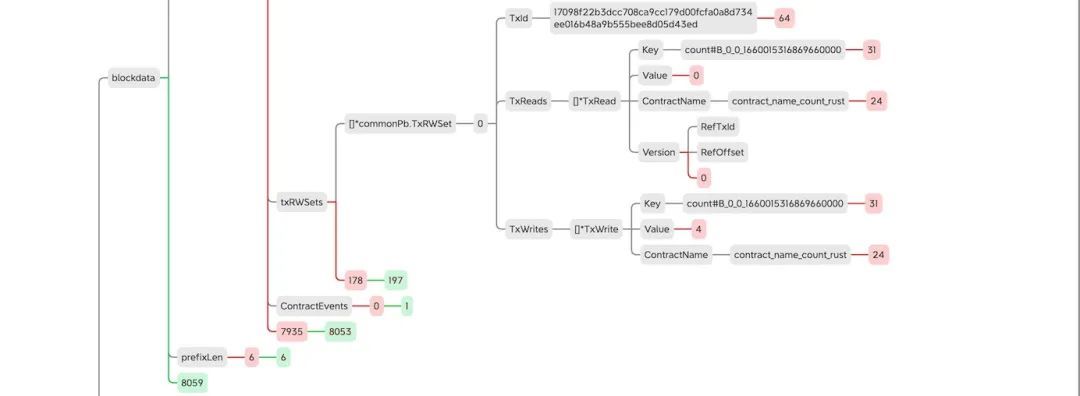
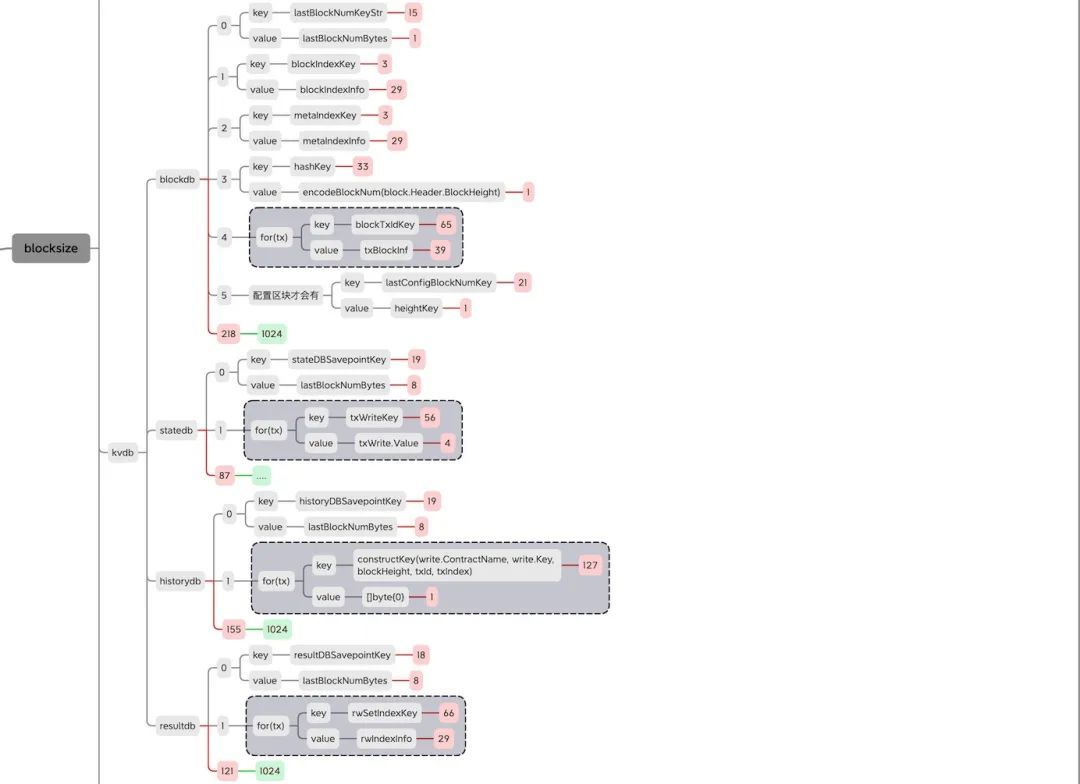

图4
膨胀率公式总结
本次测试中所采用的存证类型合约在交易全部并行运行时的数据膨胀公式:
1.Tbft:使用tbft共识
2.Raft:使用raft共识
3.Read:读集:指使用ctx.getStatexxxx
4.Write:写集:指使用ctx.putStatexxxx
5.Event:事件:指使用ctx.event(xxxxxx
blockFileDbSize = (Tbft(8,346) or Raft(2,603)) +
len(ChainId+orgId) + txCount * 2 +
(
1,196 + len(ChainId + orgId + ContractName + Method + key + val) +
Event(len(topicName + contractName + eventData) + 64) +
len(result) +
Read(len(key + field + 1 + value + contractName)) +
Write(len(key + field + 1 + value + contractName))
) * txCount
blockIndexDbSize = blockFileDbSize * 0.07
stateDbSize = Write(len(key + field + 1 + value + contractName) * txCount
结 语
本次总结的公式长,变量多,需要根据实际的合约以及调用参数做实际的膨胀率统计。同时长安链也在探索更多的方案来降低存储数据膨胀率,降低存储成本,欢迎业内朋友提出更加优秀的方案,提升长安链存储效率。