音视频通讯QoS技术及其演进

利用多种算法和策略进行网络传输控制,最大限度满足弱网场景下的音视频用户体验。
良逸|技术作者
01 什么是QoS?音视频通讯QoS是哪一类?
QoS(Quality of Service)是服务质量的缩写,指一个网络能够利用各种基础技术,为指定的网络通信提供更好的服务能力,是网络的一种安全机制,是用来解决网络延迟和阻塞等问题的一种技术,包括流分类、流量监管、流量整形、接口限速、拥塞管理、拥塞避免等。通常QoS提供以下三种服务模型:Best-Effort service(尽力而为服务模型),Integrated service(综合服务模型,简称Int-Serv),Differentiated service(区分服务模型,简称Diff-Serv)。
上面的这些描述,都指的是传统的、原始的QoS的定义和技术栈,其来源于早期互联网的网络传输设备间的质量保证体系。而本文要讨论的QoS,是在一个完全不同层次的质量保证体系,我们先看一下这两个层次QoS的关系。
视频会议公司Polycom的H323白皮书QoE and QoS-IP Video Conferencing里提到,QoS分为两类,一类是基于网络的服务质量(Network-Based QoS)NQoS,一类是基于应用的服务质量(Application-Based QoS)AQoS。下图展示了两种QoS不同的作用使用场景和不同的质量保障层次。
NQoS是网络传输设备间的基础通信质量保障能力,是这类通讯设备间特有的一组质量保障协议,这些设备有路由器、交换机、网关等。而AQoS则是应用程序内部,根据应用对应的终端设备类型、业务场景、数据流类型所实现的,在不同网络状态下尽力而为地保障用户体验的能力。
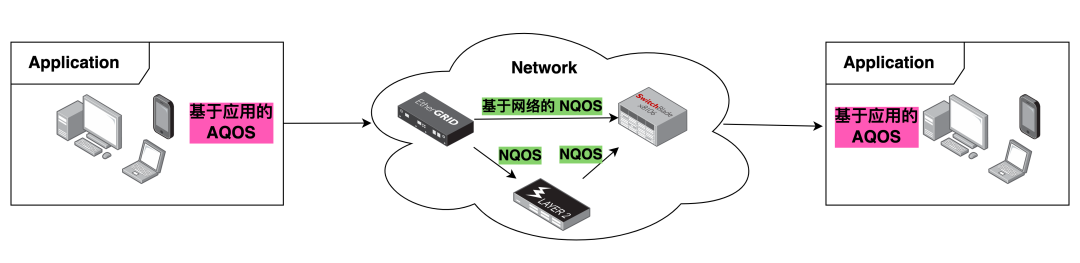
虽然NQoS和AQoS都会对最终用户的体验有决定性影响,但如果将应用场景限定在音视频通讯领域,则AQoS这种基于应用的QoS就极为重要了,因为NQoS作为互联网的基础设施的一部分,为兼顾各种使用场景,更多的是一种「普适」的传输质量保障技术,很难对特定领域做太多的针对性优化,所以本文重点讨论的音视频通讯QoS其实是一类基于应用的AQoS,是针对音视频通讯领域的相关应用程序的传输质量保障技术。
02 音视频通讯QOS背景
个人理解,音视频通讯QoS是「利用多种算法和策略进行网络传输控制,最大限度满足弱网场景下的音视频用户体验的能力」,如下图所示:
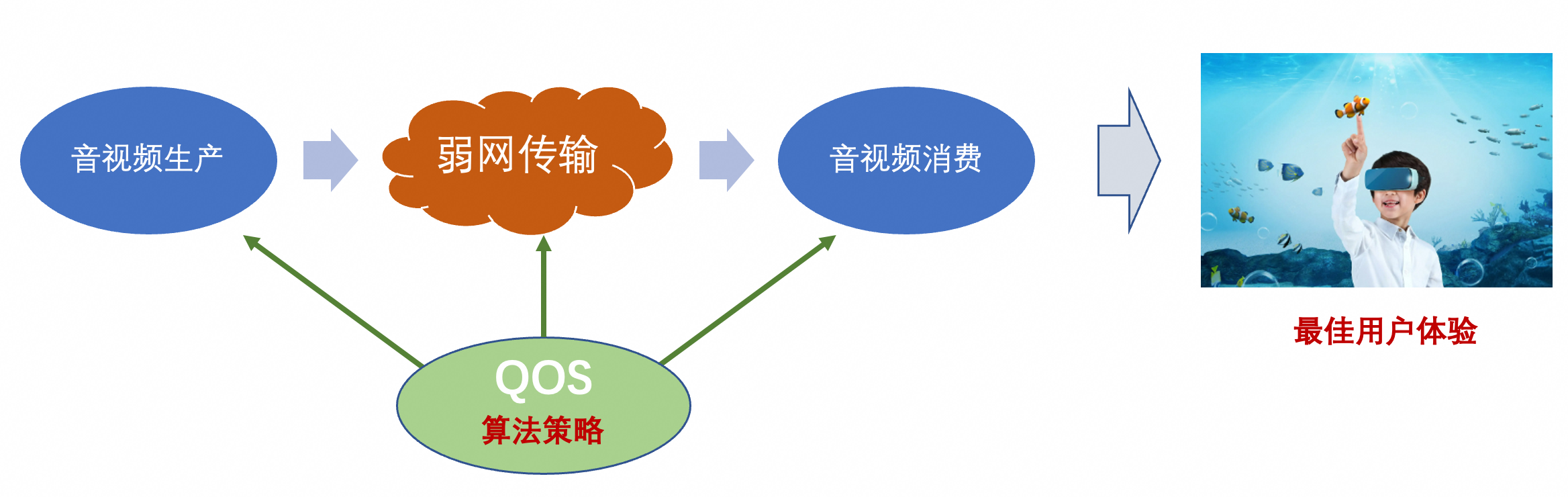
数据从音视频媒体生产环节,经过各种弱网网络条件的中间传输环节,到音视频媒体的消费环节,形成最终的用户体验。QoS通过各种策略和算法,对端到端全链路进行控制,最终让用户能够获得最佳体验。
03 音视频通讯QoS面临的挑战
网络场景
各种网络条件非常复杂:网络的种类和组合多样,特别是在最后一公里,有双绞线、同轴电缆、光纤、WIFI、4G、5G等;即使同样的网络链接,又会随着不同的场景产生变化,比如4G,5G,WIFI这种无线信号,会随着位置的变化信号强弱也飘忽不定,会出现4G、5G、WIFI信号的切换。即使是有线网络,也会因为链路上多种App共用、多个用户共用,出现竞争拥塞等问题。
业务场景
各种音视频通讯业务场景多样,例如,点播、直播(RTMP/RTS)、会议、互动娱乐、在线教育、IOT、云游戏、云渲染、云桌面、远程医疗等等。不同的业务场景,又有不同的体验需求,例如,直播场景注重流畅的体验,而对音视频互动时效性,要求并不是太高;会议场景则对沟通交流的实时性要求会比较高,而对音视频画质的要求没有那么高;但对云游戏等场景,则要求极低的延时,同时要保证极高的清晰度。
用户体验
如下图所示,音视频通讯场景,用户体验主要从清晰度、流畅性、实时性三个方面来衡量。
清晰度,是用户感受到的视频画面清晰还是模糊,一般情况下分辨率越高越清晰,越清晰的画面包含的信息量就越多,传输时占用的流量就多;
流畅性,是用户感受到的视频画面运动起来的时候是顺畅还是卡顿,一般情况每秒钟看到的画面数量越多越流畅,同样每秒画面数量越多,传输时占用的流量也越多;
实时性,是音视频信息从其发生到被远端用户感受到所需要的时间,时间越短实时性越好,实时性越好对传输速度的要求就越高。
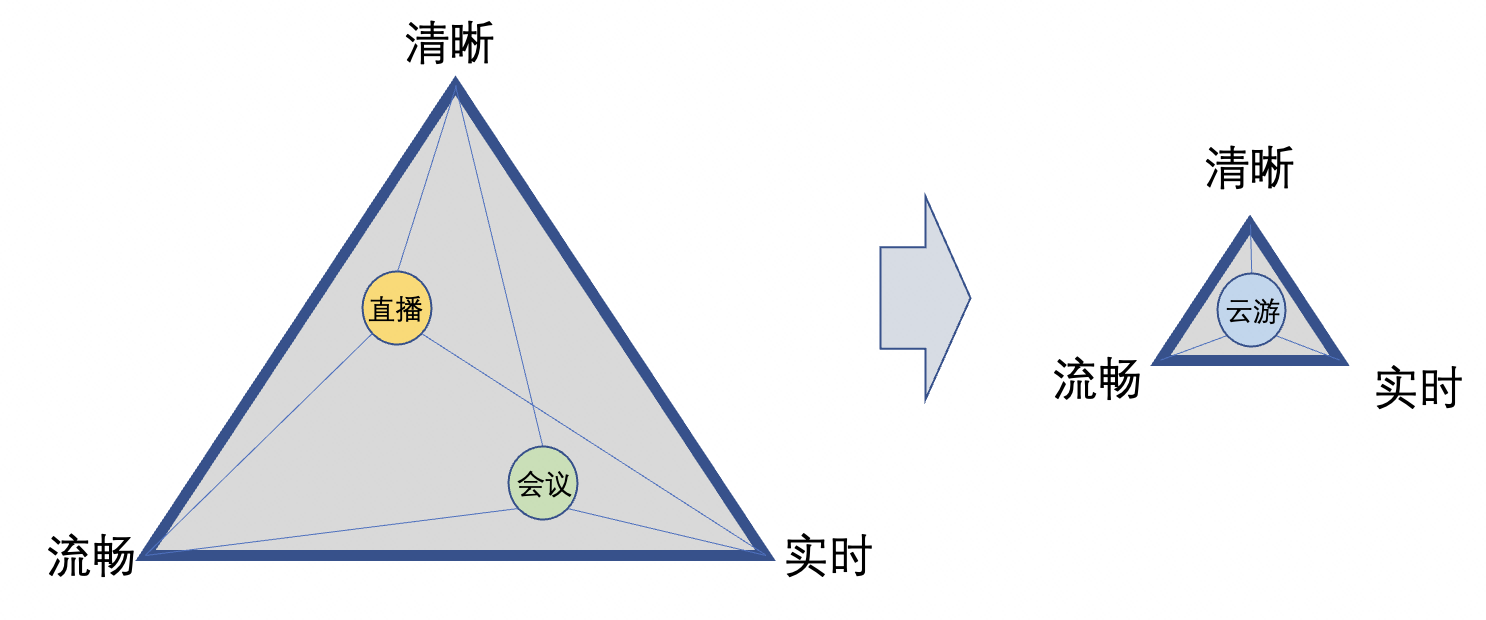
前面说过,不同的业务场景对清晰度、流畅性、实时性三者的要求有着不同的侧重,然而随着音视频通讯业务场景的不断发展,越来越多极低延时和可沉浸的场景不断涌现,用户对音视频体验,可以说是既要又要还要,而且要求越来越高,留给技术人辗转腾挪的空间越来越小。在这种趋势下,对音视频传输QOS的技术要求也变得越来越高。
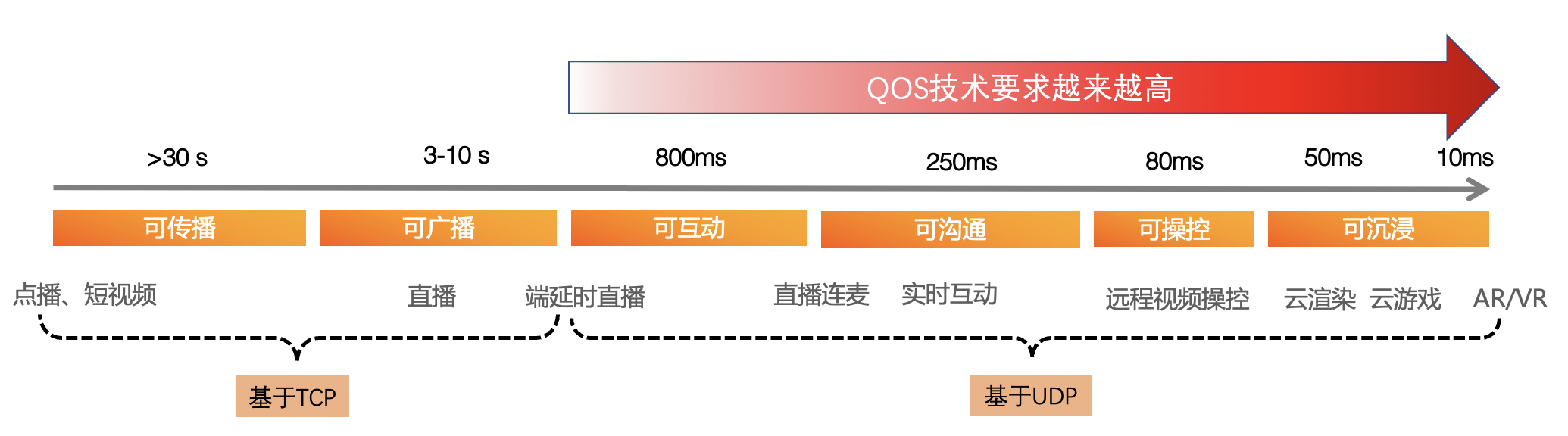
从底层协议来看,基于TCP传输的音视频通讯,例如直播、点播等,一般都延时比较大,而且因为数据都封装在TCP协议内部,依靠TCP本身的抗弱网机制来保证可靠性,应用层很难有机会参与其中的控制和优化,只适用于延时容忍度较大的场景。对于延时容忍度较小的场景,基本都是基于UDP的,大家都知道UDP传输的特征就是可靠性差,需要应用层通过各种抗弱网技术手段来保证数据传输的可靠性,QoS技术就有了大显身手的机会。
本文主要讨论基于UDP传输的,最具挑战性、技术最复杂的音视频短延时通讯QoS技术,包括实时音视频通讯RTC场景和低延时直播RTS场景。
04 弱网的分类
假如我们的传输网络非常的完美,有足够大的带宽、有足够低的延时、有足够高的保障,那我们就能很容易地实现像真人一样的面对面交流,我们也不需要QoS技术,不需要编解码,只要把音视频采集下来,再瞬间传送到对端播放出来就可以了,人与人的远程互动将变得十分美好。
然而,现实离这种美好相去甚远,现代的音视频通讯是建立在互联网的基础设施之上的一类应用,这让互联网的传输质量,变成了音视频通讯传输质量不可能突破的天花板。众所周知,互联网的传输是复杂的、昂贵的、不可靠的、不稳定的,没有办法搞清楚所有的传输环节的状况,我们需要对这些问题进行抽象分类,以便于更好地针对不同的场景进行有效应对,竭尽所能的保证用户的音视频体验不受太大的影响。
我们一般把网络传输质量不符合预期的场景叫弱网场景,弱网分成拥塞、丢包、延时、抖动、乱序、误码等。拥塞,是可用带宽不足的表现,如同高速堵车;丢包,是数据在传输过程中丢了,不知去向,如同快递丢失包裹;延时,一般是中转太多或者拥塞排队导致时效性变差,如同转机或堵车;抖动,是数据传输间隔忽大忽小,如果不做处理,可能会导致音视频忽快忽慢;乱序,是后发先至,先发出去的数据比后发出去的数据到的还晚,如果不处理,可能会导致音视频的回放;误码,是传输过程中数据错误,由于传输层会有校验、修正、重传,所以应用层一般都无感知、无需特别处理。
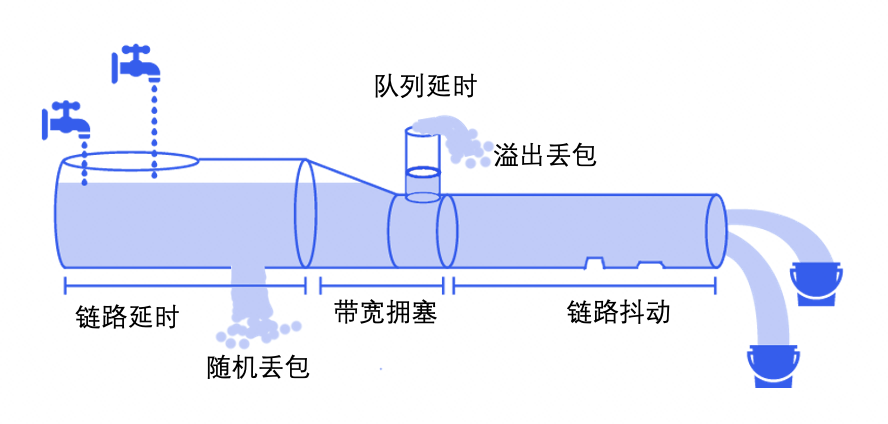
上图用管道灌水比较形象的把几种弱网场景做了说明:左边是流量生产侧,右边是流量消费侧,管道的长度是链路的基本延时;管道传输过程中会产生一些错误和丢包;当管道由宽变窄而且流量超过管道的宽度,就会产生带宽拥塞;当拥塞产生时会出现流量排队的情况,部分流量会被放到缓存队列,相应地产生队列延时;当缓存队列满了之后,会产生队列溢出,溢出的流量就对应了溢出丢包;链路数据传输过程中会有一些波动和信号干扰,导致数据的传输速率不是恒定的,最后收到的数据变得忽快忽慢,我们将其归类为链路抖动。现实中,这些不同的弱网类型往往是混合在一起同时出现,对其做不同的分类,可以方便我们从技术上对其各个击破。
05 音视频通讯QoS技术体系
QoS技术分类
音视频通讯QoS技术和策略就是为了对抗上述弱网场景而诞生的,其目的就是尽最大可能消除因为网络变差给用户带来的体验衰退,所以对应上面讲的不同弱网场景的分类,用到的QoS技术也被分成了几大类:拥塞控制、信源控制、抗丢包、抗抖动,每一类技术都包含很多的不同的技术点和技术细节,后面再来展开。

拥塞控制,是网络状况探测和数据发送方式的决策中心,是整个发送侧QoS技术的核心,是传输控制的大脑;
信源控制,是在拥塞控制的决策下,控制音视频信源产生的方式,控制信源的码率,来适应探测出来的网络状况,实现抗拥塞的目的;
抗丢包,是在网络有丢包的场景下,对信源数据增加冗余信息,达到部分信息被丢失的场景,也能够完整地恢复出原有数据;
抗抖动,是在网络延时有波动、数据时快时慢、时有时无的情况下,增加一部分延时,对数据进行缓冲,让用户体验更流畅,不至于卡顿;
上面也说明了不同类的QoS技术对应可以解决不同的用户体验问题,可以看出都是围绕流畅性、清晰度、实时性这三点来改善的。拥塞控制是总指挥,很多时候对整个链路的体验起决定性作用,信源控制可以提升流畅性和清晰度方面的体验,抗丢包和抗抖动可以提升流畅性和实时性方面的体验。
QoS在音视频通讯流程中的位置
我们知道音视频通讯是端到端的全链路通讯,其涉及的技术领域非常广泛,跨度非常大、非常复杂。比如,客户端侧就包含了市面上能见到的Windows、MacOS、iOS、Andorid四个平台的所有终端的适配、兼容、互通,甚至要跟浏览器进行互联互通,同一个平台每款不同的设备也存在较大的差异,很多时候需要单独的适配。还有音频3A(AEC、AGC、ANS)、音频编解码(Opus、AAC)、视频编解码(H264、H265、AV1)等任何一个领域展开都是非常复杂的技术栈。而云端的各种服务器也是实现互联互通不可缺少的环节,包括信令服务器、媒体服务器、混流、转码、录制、节点部署、调度选路、负载均衡等等,每个节点、每种服务都是复杂的存在。
在如此复杂的音视频通讯技术链路中,QoS技术也只是其中的一个比较窄的领域,但也是不可或缺的,对线上的音视频通讯的可用性有着决定性意义。QoS技术看起来也是音视频通讯领域为数不多的全链路的技术,它端到端、全链路控制着媒体传输、媒体编解码的各个环节,以至于从事QoS技术的相关工程师需要对客户端和服务器的全链路的技术都要有一定的了解,需要从全局的视角来看整个音视频通讯。
下图是对音视频实时通讯链路功能的一个抽象,用媒体发送和媒体接收的P2P模式,省略了复杂的服务器传输部分,方便大家的理解。
音视频通讯的基本流程:首先是推流客户端,从终端设备的音视频采集模块采集的音视频数据是未经过压缩的原始数据,按帧(frame)存储的、尺寸较大的媒体数据,是没有办法直接在网络上传输的,需要先进行压缩,就到了编码部分,用到了音视频的编码器,编码完成之后,数据依然很大,需要进行切片,然后经过RTP对切片后的数据做封装,封装完之后,从发送队列发送到网络上,经过服务器的一系列透传或处理,到达拉流客户端,拉流端收到网络发送过来的RTP数据包之后,要先进行RTP包的完整性判断,判断编码后的数据帧切片数据是否都已经被收到,之后再解RTP封装,恢复编码后的端数据帧,并送给解码器进行解码,解码完的数据送到渲染模块,用户就看到和听到了推流端的画面和声音。
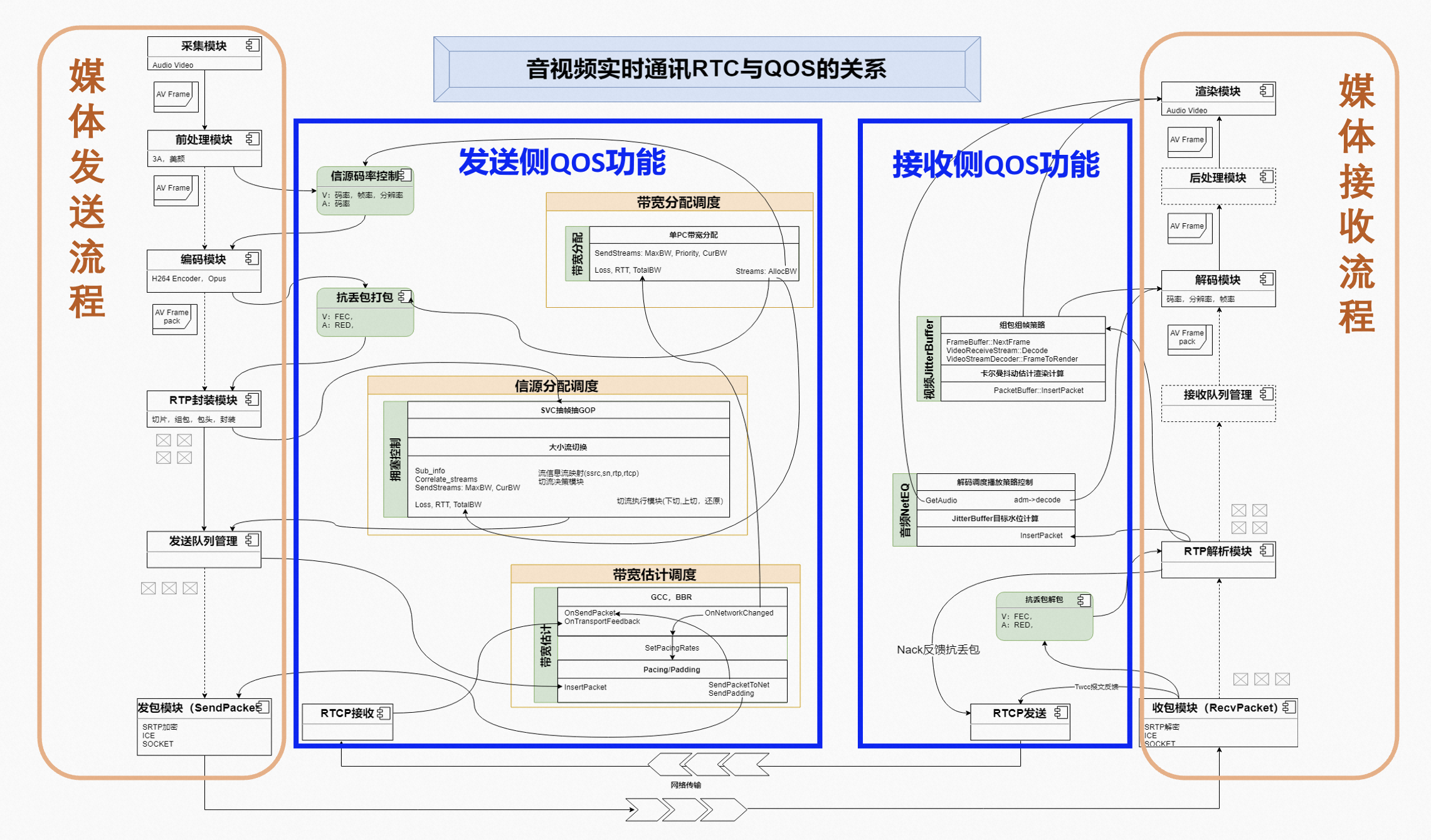
上图左边是媒体发送侧的处理流程:音视频采集模块、前处理模块、编码模块、RTP封装模块、发送队列、网络数据发送。右边是媒体接收侧的处理流程:网络数据接收、RTP包解析模块、接收队列管理、解码模块、后处理模块、渲染模块。中间的左边蓝色的框内功能是发送侧QoS相关的功能,右边的蓝色框内的功能是接收侧QoS相关的功能。另外,从RTCP协议本身的定位看,它就是对基于UDP的媒体RTP数据进行控制的协议,所以也可以看成QoS控制的一部分。
从上图还可以看出两个特点,第一,QoS功能跟很多其它模块都相关,这是因为QoS技术是全链路控制的技术,需要触达的模块比较多;第二,发送侧的QoS功能明显比接收侧的QoS功能多,这是因为目前很多都是发送侧带宽估计和拥塞控制,因为这样会更接近信息产生的源头,从源头解决问题的效率更高,防患于未然。接收侧的技术往往是比较被动的,是出了问题之后的最后补救,亡羊补牢。
QoS技术体系
讲完QoS技术的分类和QoS技术在音视频通讯技术中的位置,接下来我们聚焦在QoS技术领域内部,从客户端和服务器媒体链路来看QoS技术体系和其中比较大的技术点,如下图所示。左下角的推流客户端侧,用到了信源控制、拥塞控制、抗丢包技术;中上部的媒体转发服务器SFU,用到了信源控制、拥塞控制、抗丢包技术;右下角的拉流客户端侧,用到了抗丢包、抗抖动技术。下面简要串一下相关的技术点的大概流程和意义。
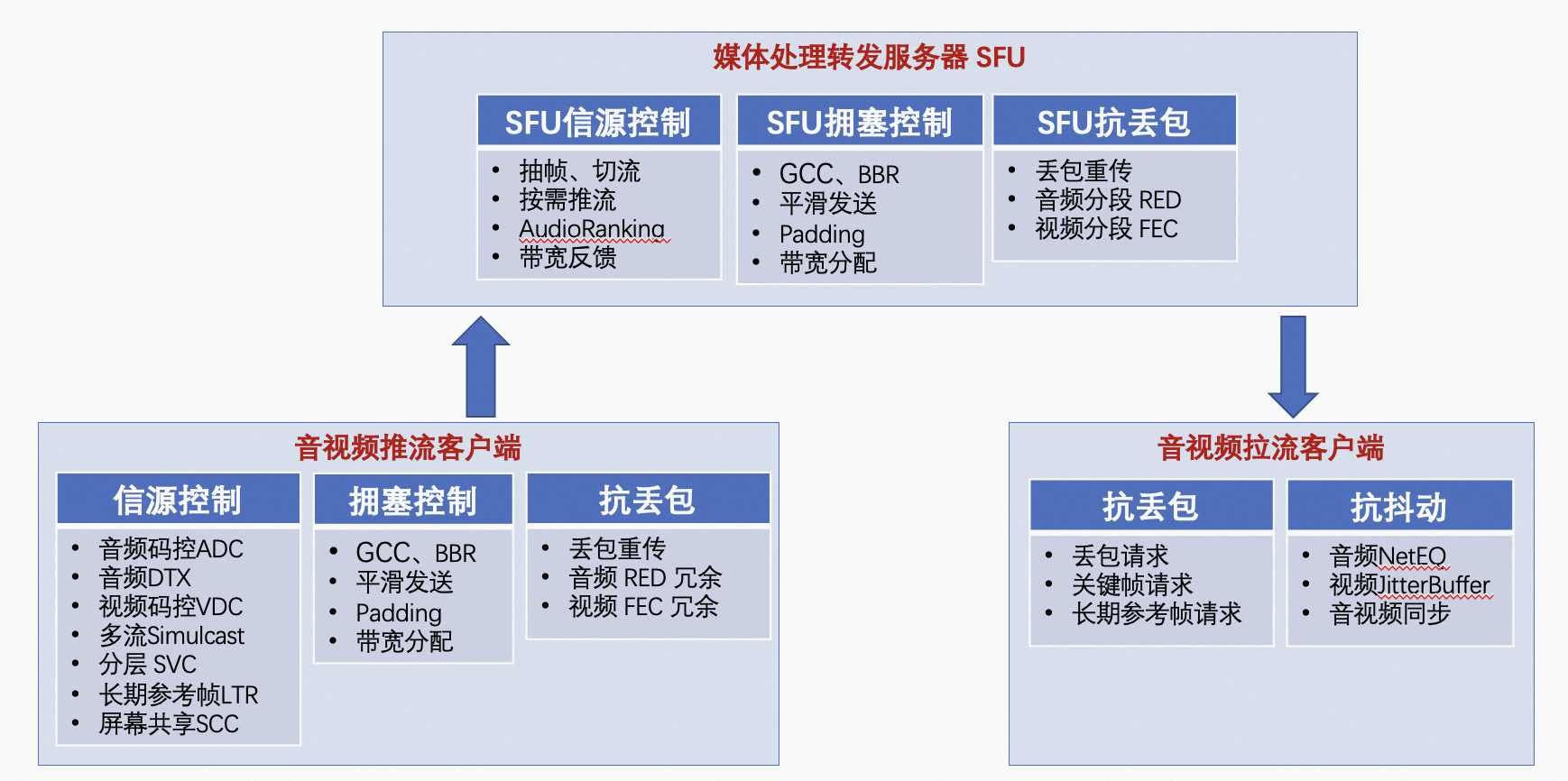
l 音视频推流客户端
所有媒体RTP数据包发送的时候,会在RTP的扩展头中增加一个统一的序列号,可以认为每个数据包有一个唯一的编号,这样所有发出去的数据都有了对应的序列号、发送时刻、包大小三个信息。在接收端收到这些RTP数据包之后,会把每个收到的序列号以及收到的此序列号的接收时刻信息,按照TransportFeedback(twcc)报文定义的格式封装到RTCP包中,反馈到推流端。参考:《WebRTC研究:Transport-cc之RTP及RTCP》,推流端根据这些反馈信息,就能估算出当前网络传输的状况,包括丢包、延时、带宽三个方面的信息。这些估算的算法,就是带宽估计算法(也叫拥塞控制算法),上图提到了比较常用的两种,一个是GCC(google congestion control),一个是BBR(Bottleneck Bandwidth and Round-trip Time),两个都是谷歌推出的拥塞控制算法。
为什么不单纯叫带宽估计算法呢?这些估计算法一般都会跟平滑发送PacedSender配对使用,很少出现只估计不控制的情况,平滑发送控制策略也是估计算法架构设计中的一部分,为了让发送的码流尽量是比较平顺的,防止忽高忽低的波动,以免对链路造成冲击,带来不必要的拥塞。
基于这些拥塞控制算法的设计,很多时候为了相对准确的探测到足够大的可用带宽,在原始的音视频数据不足以填满期望的带宽到时候,比如视频画面静止不动、音频静音的场景,就需要发送一些Padding数据来临时填充带宽,这些Padding数据有时是用重复发送原始包的方式,有时就干脆发一堆垃圾数据,目的只是用来填充带宽,收到之后也会将其丢掉。
经过估计算法的估算,得到网络的可用带宽、传输延时、丢包率信息之后,就可以将这几个信息广播到各个需要的模块,例如带宽分配模块。在带宽分配模块中,会按照一定的优先级和分配策略,将可用的带宽,分给每一条音视频流,而且在有丢包的场景,需要同时为每条音视频流分配对应的冗余信息带宽。
分配完带宽资源之后,就到了信源控制部分,音视频流的码控模块会根据各自的码流特征、编解码能力、技术手段进行各自的控制,例如基础的音频码率、帧长、视频的码率、帧率、分辨率、QP等基本控制,同时也有一些编码相关的特定技术点的控制,例如音频DTX(Opus编码器不连续传输-->降低带宽占用)、视频simulcast(同时推送多流-->满足不同订阅场景降低带宽)、视频SVC(可分层视频编码-->实现动态抽帧能力降低拥塞)、视频LTR(长期参考帧-->降低重传带宽)、视频屏幕共享SCC(屏幕内容编码-->降低屏幕共享场景带宽)等等。
在网络有丢包的场景下,我们要储备抗丢包的技术手段。抗丢包手段一般有两种:
一种是丢包重传,收流端发现数据丢包了,不再连续的时候,主动通过NACK报文(RTCP报文的一种)发送重传请求到推流端,而推流端则需要随时缓存之前发过的数据,以满足丢包之后的重传需求,对丢失的数据进行补发。这是一种滞后性的补救措施,所以相对比较节省带宽,但是会增加延时;
另一种是发送数据的时候,同时发送一部分冗余信息,一旦传输过程中出现丢包,则可以靠这部分冗余信息,恢复部分或全部的原有数据。这是一种预防性的技术手段,因为冗余和原始数据同时发送,所以可以即刻进行丢包恢复,不存在延时问题,但因为有冗余信息存在,所以会占用更多的带宽。这里增加冗余信息的方式有2种,一种是RED封装,用在数据包比较小的音频传输场景;另一种是FEC编码封装,用在数据包比较大的视频或音频场景,目前有很多种FEC编码方式可用,这方面算法的研究也比较多。
l 媒体转发处理服务器SFU
到了媒体转发服务器,其一方面作为收流侧对应推流侧客户端,另一方面媒体服务器会作为发送侧对应拉流客户端。收流侧基本只提供抗丢包能力,和拉流侧的抗丢包能力配合使用就形成了全链路的分段抗丢包能力,分段意味着上行和下行分开来做抗丢包,互不影响,好处是可以简化设计,同时对不同的下行弱网和非弱网用户,可以提供按需服务,有比较强的自适应能力。收流侧和拉流侧的抗丢包跟上面说的客户端的抗丢包一样,也包含丢包请求、重传,对应RED编解封装,对应FEC编解码、编解封装的功能,这部分功能相对比较固定,在跟客户端推流侧进行SDP媒体能力协商之后,就确定了哪些功能可以开或者是关。
服务器的发送侧功能,跟客户端推流侧一样也比较复杂,包含拥塞控制GCC、BBR、平滑发送、Padding等拥塞控制算法以及带宽分配,服务器上的这些算法跟客户端推流侧的算法基本的框架结构和基本功能都是一样的,只是算法的参数配置、使用的策略,都跟客户端是不一样的,因为服务器侧的信源控制力跟客户端推流侧的信源控制力,是完全没法比的,不可同日耳语。同时,服务器需要顾及很多的推流端和很多的拉流端,更需要平衡各种关系,众口难调是服务器面临的主要矛盾。
服务器的这种地位也衍生出了一些特定的技术手段,比如视频的抽帧(抽掉一些不影响解码的帧数据来降带宽)、视频切流(主动切换到带宽和清晰度较低的流上来降低带宽)、视频按需推流(根据实际的订阅关系准许推流端直推需要的流来降低带宽)、音视频带宽反馈(特定场景可以将拉流测信息反馈给推流侧让其提供更准确的码控服务)、音频AudioRanking(多人会议场景将不说话人的声音过滤掉来降低带宽)等等。服务器相关的更详细的技术点描述,可以参考《阿里云 GRTN QoS 体系 — 构建实时音视频产品最佳体验》。
l 音视频拉流客户端
最后到了音视频拉流客户端,这里的抗丢包功能除了上面说的丢包重传、RED、FEC,又多出了两个,一个是关键帧请求,一个是长期参考帧LTR请求,这两个视频帧请求目的都是为了恢复视频帧的参考链,以便能够重新开始视频解码。
关键帧请求是需要视频重新开始编码,让收到关键帧的任意客户端都可以解码,使视频帧的参考链重新开始。长期参考帧则是在确认已经收到一个长期参考帧的情况下,不必再从关键帧开始编码,只要发送一个长期参考帧就可以恢复参考链,即用发送长期参考帧的方式替代发送关键帧。这样做的好处主要是降低重传带宽,但同时增加了复杂性,因为服务器需要确认每个拉流客户端,都收到了某个特定的长期参考帧,在拉流客户端数量较多的场景,这个条件比较难以满足。可以参考《阿里云 RTC QoS 弱网对抗之 LTR 及其硬件解码支持》。
另外拉流客户端比其它部分多了抗抖动的功能,主要思想是增加一个数据缓冲的buffer,增加了一部分延时。就像一个水库一样,雨季的时候蓄水,将快速流入的水储存起来,旱季的时候放水,将之前存储起来的水慢慢放出来,确保自始至终有水流出。
音频和视频的数据流有各自不同的特征,对应音频的抖动缓存机制和视频的抖动缓冲机制也是不一样的,目前用的较多的都是WebRTC里面的音视频抖动控制机制,视频是基于卡尔曼滤波器的JitterBuffer,音频是NetEQ,具体的算法都非常复杂,这里就不展开了,有兴趣的同学可以参考《WebRTC视频JitterBuffer详解》和我之前的一篇白话文《白话解读 WebRTC 音频 NetEQ 及优化实践》。
音视频的拉流侧或播放侧一般都会有音视频同步(又叫唇音同步lip sync)的需求,否则会出现只闻其声不见其人,或只看到闪电听不见雷声的情况。WebRTC原有的音视频同步机制非常的复杂,我之前也有过介绍《WebRTC 音视频同步原理与实现》,而且在NetEQ及优化实践中也提到了一种简单的替代方案,这里也不展开。
06 音视频通讯QoS技术的演进
上面粗略地讲述了音视频通讯QoS用到的技术体系,任何技术都是需要一定的软件架构来承载和实现的,音视频通讯领域的QoS技术也是随着音视频通讯的软件架构演进而不断升级的。对于实时音视频通讯RTC的演进历史,可以参考《历经5代跨越25年的RTC架构演化史》。这里面提到「谷歌在2011年开源了WebRTC,作为RTC技术领域的里程碑事件,大大降低了RTC开发的门槛,催生了后来移动互联网RTC应用的大时代」。
WebRTC以前
在WebRTC面世以前,因为门槛较高,音视频通讯基本都是几大头部玩家的之间的游戏,例如Polycom、华为、思科、微软、BT、Vidyo等,各家都有自己的私有架构,都在闭关修炼。他们用到的QoS技术也都是各自的武功秘籍,只能从一些公开的文章或者协议标准的提交中窥探一二。2012年当我在Polycom看到WebRTC开源的消息时,还完全没有觉得是什么了不起的事情,Polycom当时有着一众音视频技术的科学家,支持各种编解码技术,是行业里的绝对头部,没想到几年光景下来就泯然于众了。
WebRTC以后
在WebRTC面世以后,音视频通讯领域第一次将其技术栈较全面的暴露在了阳光下,人人都可以基于上面做自己的实验、优化、演进,吸引了大量开发者、初创企业、互联网巨头的参与,不管是技术小白,还是行业专家,都不自觉的、主动或被动地卷入了WebRTC重新定义的音视频通讯行业。因为WebRTC本身也是一个比较优秀的架构,其QoS技术和带来的通讯效果都是不错的,所以很多企业也都放弃了原有的私有架构,转而在WebRTC的基础之上适配自己的业务逻辑,增加自己业务场景特有的QoS算法优化。
然而,WebRTC本身定位源于P2P的互联网浏览器间的通讯,其重点在客户端侧的架构与实现,而伴随云上音视频通讯业务场景的发展,媒体转发服务器变成了两个客户端之间不可缺少的一环。支持WebRTC协议的媒体服务器也有多种,例如janus、mediasoup、srs、licode、kurento、jitsi等,可以参考《十大必知开源WebRTC服务器》。但很多媒体转发服务器SFU都只是实现了转发功能,对链路控制的QoS技术支持非常的薄弱,有的甚至聊胜于无,而且由于服务器代码架构跟WebRTC的端侧代码架构差异巨大,导致迁移原有WebRTC的QoS算法,也变得非常困难。
QoS技术算法优化阶段
大概在2021年疫情前半段以前,互联网逐渐走到巅峰,大家都是业务高涨、快速迭代,各家都是拿来主义,直接把WebRTC编译通过之后,就集成到自己的SDK里面去了,先把业务做起来,再慢慢调优QoS算法,只要能满足高涨的业务需求,不会考虑架构是否复杂、实现是否优雅。这个阶段都是基于WebRTC的QoS算法优化,各类技术文章层出不穷,基本上覆盖了上面QoS技术体系中提到的各个技术点,网上90%以上关于QoS优化的文章都是这一类单点算法的优化和算法的深度解析。大家的技术水平很快被拉到了同一个起跑线上,对新入坑的音视频技术同学非常友好,只要愿意学很快就能上手。
这种QoS单点技术的优化升级,是提升QoS性能的核心手段,是最终提升用户体验的立足点,将会一直持续下去。但是这些单点算法优化也有瓶颈,一旦到达现有基础科学研究的天花板,想再提高就很难了,因为需要基础理论研究的突破为前提,这个投入产出不是一般商业公司愿意承担的,也不是一般的算法技术人员能够突破的,所以大部分的国内的公司和技术人员都选择了知难而退,也是大环境使然。
当然,大家也不用担心算法技术人员就无用武之地了,毕竟很多技术还没有到达基础科学的天花板,我们还有一些时间;毕竟我们最擅长的就是拿来主义,搞不了脑力,就搞体力,短期提高不了技术的高度,那我们可以从技术的广度入手,只要能挖掘足够多的用户场景,我们就可以针对特定的场景,进行量体裁衣,通过缝缝补补,就可以让各种场景都有一个比较好的体验,这也是一种价值体现罢。不止是QoS技术,我们的很多科学技术领域,每每说到这个层面总是让人心酸,也是没有办法的事情,希望有一天这种局面能有改观。
QoS技术架构升级阶段
随着疫情进入后半段,互联网热潮不再,IOT、云渲染、云游戏等新场景的出现,大家逐渐慢了下来,重新开始思考WebRTC这套框架是否是适合自己业务的,有没有更好的解法。对WebRTC源代码有一些了解或者参与过相关编译的同学都应该知道,WebRTC是非常庞大的一个实现,包含引用的第三方库的话,源文件数量接近20万个,这种数量级的代码给环境部署、编译配置、工程引用都带来了很大的麻烦,以至于网上有人把编译WebRTC做成了一门生意,按次收费。很少有公司能拿WebRTC直接使用,都是需要找专门的同学,做环境的配置、代码的裁剪等一系列对业务没啥价值的事情,费力不讨好。
QoS技术作为WebRTC中最有价值的技术之一,则被深度捆绑在整个代码框架里面,如果不做伤筋动骨的改造,很难直接被用在非WebRTC的代码框架中。下图是简单梳理的WebRTC中跟QoS相关的媒体处理部分流程,熟悉WebRTC代码的同学应该可以比较清楚地知道图里面每个模块的意义和作用,这里就不展开介绍了。其中红色的部分是QoS相关的模块,我们可以看出,整个流程相互耦合在一起,没有办法单独将QoS功能抽取出来。
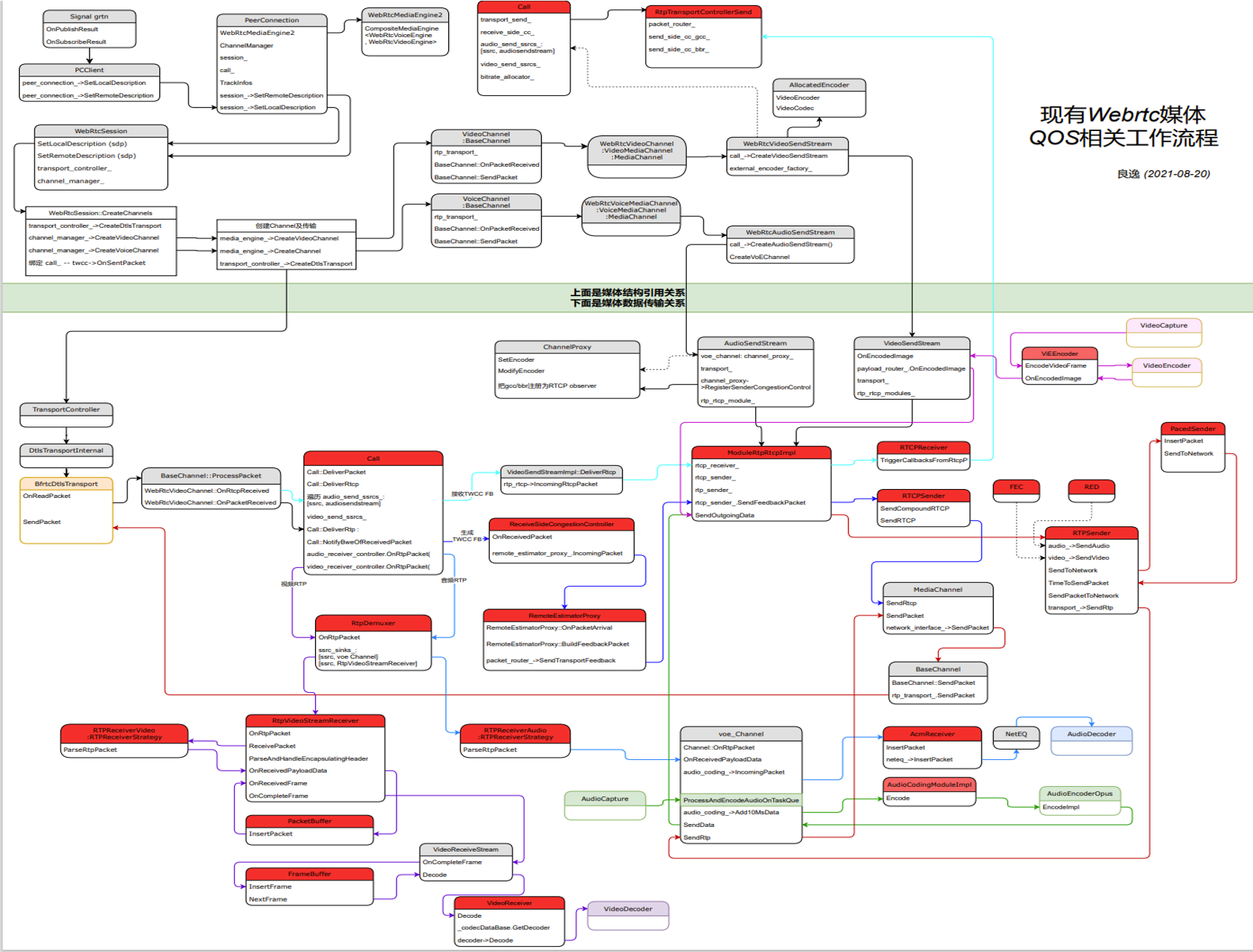
同时,对于IOT、云游戏、云渲染等场景,由于有自己特有的采集渲染、编解码功能,不能使用WebRTC的整个框架,而只需要媒体传输、QoS控制能力,所以不得不对WebRTC做裁剪,对QoS算法进行剥离。这种业务需求推动了,对原有WebRTC架构的思考和升级,推动了QoS技术的架构演进。
这种架构的升级演进具体如何来做?我认为,首先要从音视频通讯技术链路和功能模块的抽象来入手,抽象到一定高度,就看清了事物的本质,看清了本质,就能比较容易看清各个模块之间的关系,然后才能物以类聚进行解耦。下图是对QoS推拉流功能和处理流程的抽象。
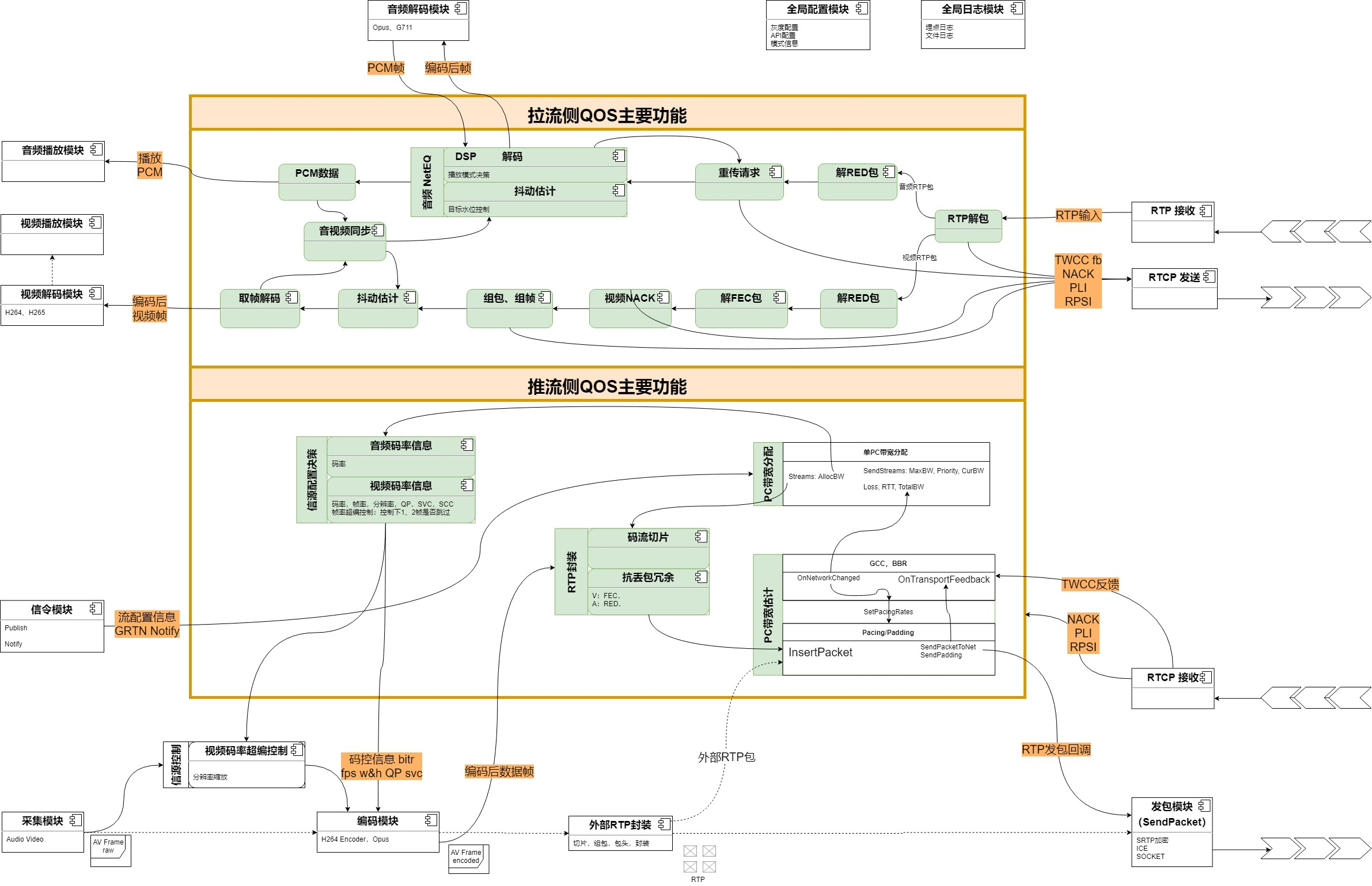
经过上面的抽象之后,我们就能比较清楚地定义出QoS功能的边界,能够进一步将QoS内部的各个功能进行重新设计实现,最终可能会变成下图分层解耦、功能模块化的样子。有了这种架构的QoS模块,就可以非常方便地迁移到各种不同的场景,甚至可以迁移到媒体转发服务器SFU上面去,实现QoS能力的快速复用,一次优化多点受益,加速新场景的商业化速度。例如,央视三星堆奇幻之旅的项目中的QoS部分,就是使用了演进后的QoS模块功能,《三星堆大型沉浸式数字交互空间最佳实践》。

从音视频通讯软件演进的形态来看,最终的结果可能是又回到了WebRTC开源之前的状态,各家有各自的私有软件架构,各家又回到了自己的QoS技术优化的小圈子,看起来绕了一圈又回到了起点,只是每家都吸收了WebRTC的精华。
本文从更宏观、更宽泛的角度介绍了QoS的概念和分类,从音视频通讯QoS领域的常用技术到架构的演进过程做了简单汇总。随着音视频通讯新场景的不断涌现,更实时,更高清变得越来越重要,相关技术也会往这个方向倾斜,同时基于大数据分析的QoS相关技术应用将会逐渐渗透。