langchain callback学习
一.quickstart
-
发现自己之前用langchain都是纯纯只是跑通,要能灵活使用还是得深入研究一下框架的,还有仔细看文档的…
-
callback其实就是当时刚开始用langchain感觉神奇的地方,就是各种行为都能看到输出
-
跑一下官方的demo
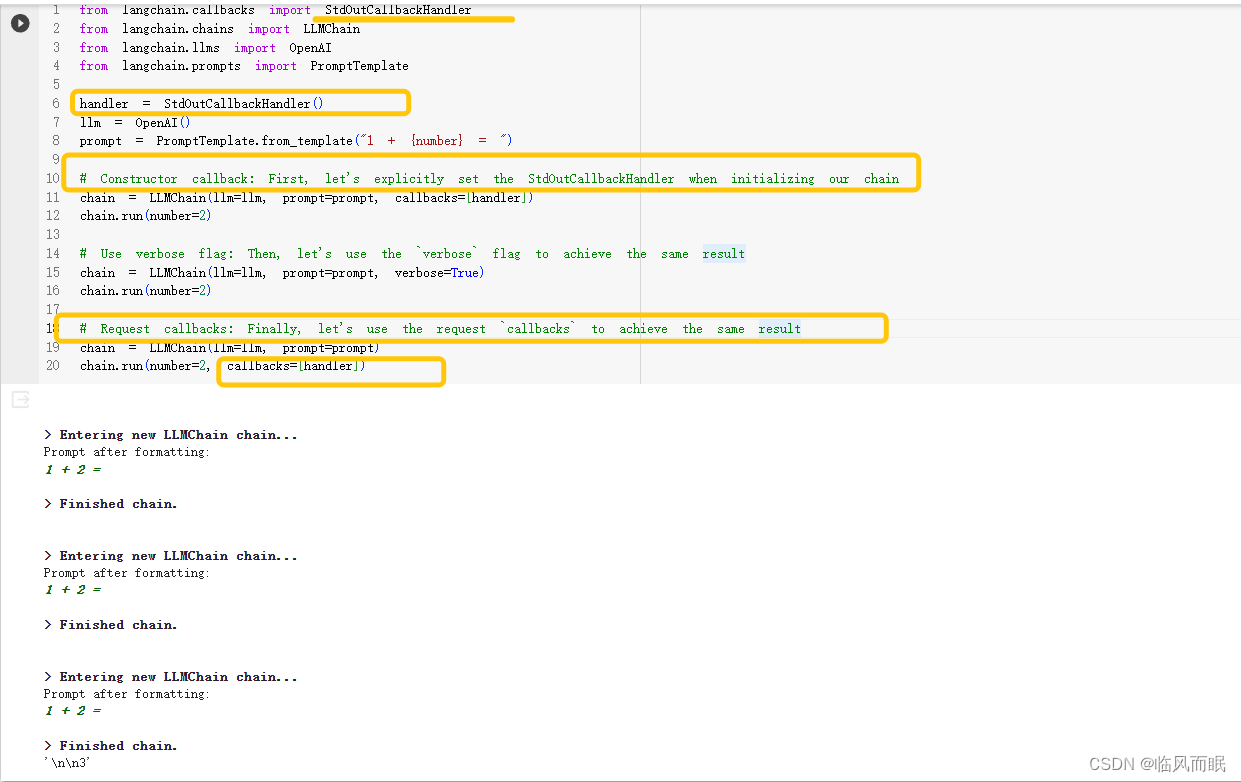
-
LangChain 的回调系统允许开发者在 LLM 应用程序的各个阶段设置hook。这意味着,无论是日志记录、监控、数据流处理还是其他任何任务,开发者都可以精确地控制和管理。
开发者可以通过使用 API 中的回调参数来订阅不同的事件。这些事件对应于处理器对象的列表,它们是预定义的并期望按照特定方式实现。
-
回调处理程序
在 LangChain 中,
CallbackHandlers是实现CallbackHandler接口的对象。这个接口为开发者提供了一系列方法,每个方法对应于可以被订阅的事件。LangChain 中定义了一个
BaseCallbackHandler类,这是一个基本的回调处理程序,它提供了处理来自 LangChain 的回调的功能。
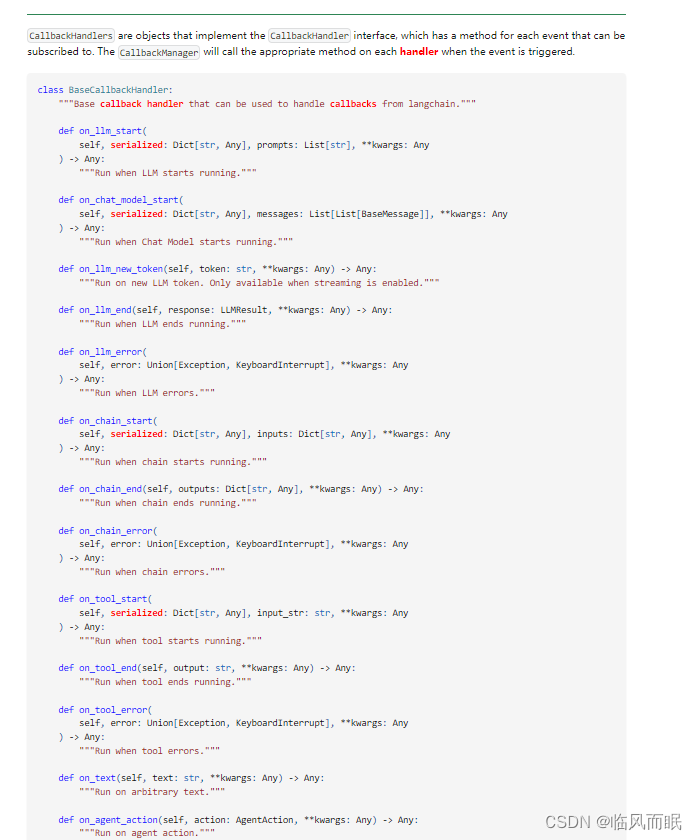
-
在 LangChain 的 API 中,几乎所有的对象(例如 Chains、Models、Tools、Agents 等)都支持回调参数。可以在两个主要位置使用它:
-
构造函数回调:这些是在对象创建时定义的,并且对于该对象上的所有调用都是通用的。
-
请求回调:这些是在执行方法(如 run() 或 apply())时定义的,并且仅适用于特定的请求。
此外,API 的大多数对象都支持
verbose参数。这是一个非常有用的工具,特别是在调试过程中,因为它会将所有事件记录到控制台。
二.Async callbacks
import asyncio
from typing import Any, Dict, List
from langchain.chat_models import ChatOpenAI
from langchain.schema import LLMResult, HumanMessage
from langchain.callbacks.base import AsyncCallbackHandler, BaseCallbackHandler
class MyCustomSyncHandler(BaseCallbackHandler):
def on_llm_new_token(self, token: str, **kwargs) -> None:
print(f"Sync handler being called in a `thread_pool_executor`: token: {token}")
class MyCustomAsyncHandler(AsyncCallbackHandler):
"""Async callback handler that can be used to handle callbacks from langchain."""
async def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> None:
"""Run when chain starts running."""
print("zzzz....")
await asyncio.sleep(0.3)
class_name = serialized["name"]
print("Hi! I just woke up. Your llm is starting")
async def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
"""Run when chain ends running."""
print("zzzz....")
await asyncio.sleep(0.3)
print("Hi! I just woke up. Your llm is ending")
# To enable streaming, we pass in `streaming=True` to the ChatModel constructor
# Additionally, we pass in a list with our custom handler
chat = ChatOpenAI(
max_tokens=25,
streaming=True,
callbacks=[MyCustomSyncHandler(), MyCustomAsyncHandler()],
)
await chat.agenerate([[HumanMessage(content="Tell me a joke")]])
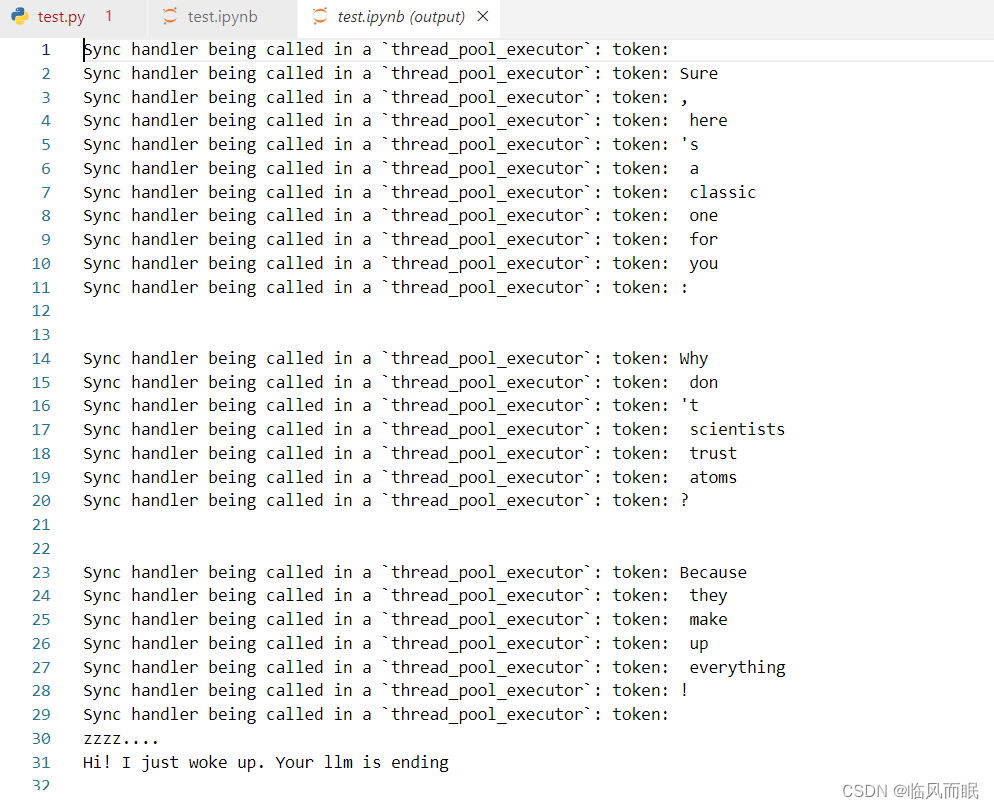
注意 await chat.agenerate([[HumanMessage(content="Tell me a joke")]]) 这个写法在jupyternotebook中可以,.py文件不行
.py文件中可以像下面这样
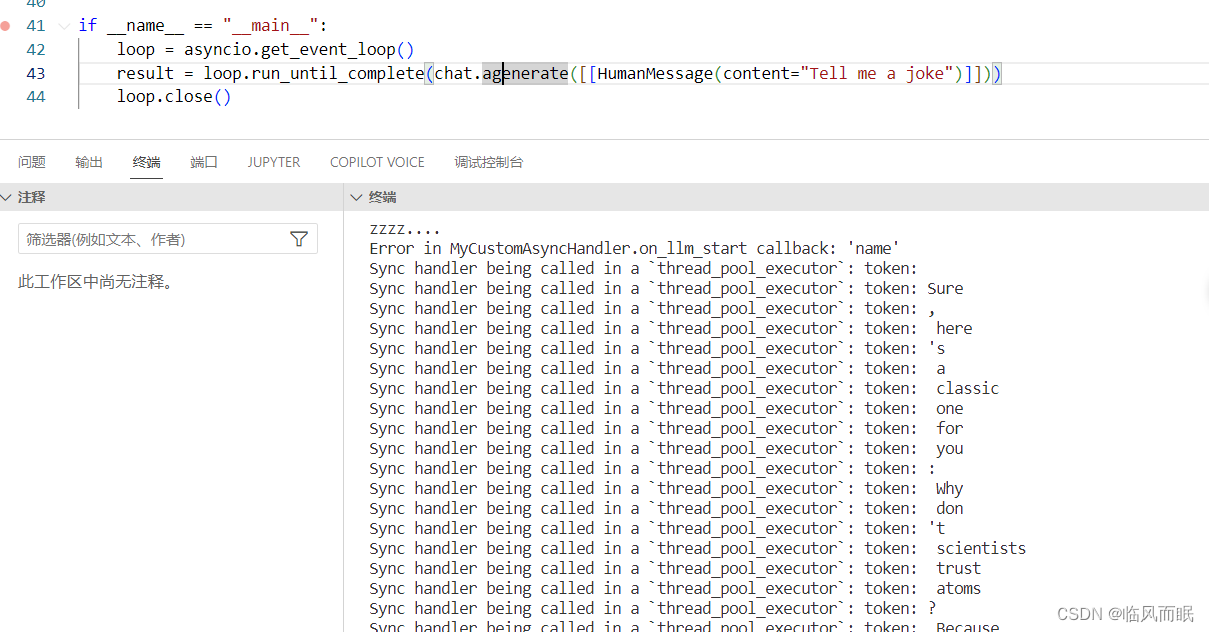
if __name__ == "__main__":
loop = asyncio.get_event_loop()
result = loop.run_until_complete(chat.agenerate([[HumanMessage(content="Tell me a joke")]]))
loop.close()
三.把回调消息写入文件
-
https://python.langchain.com/docs/modules/callbacks/filecallbackhandler
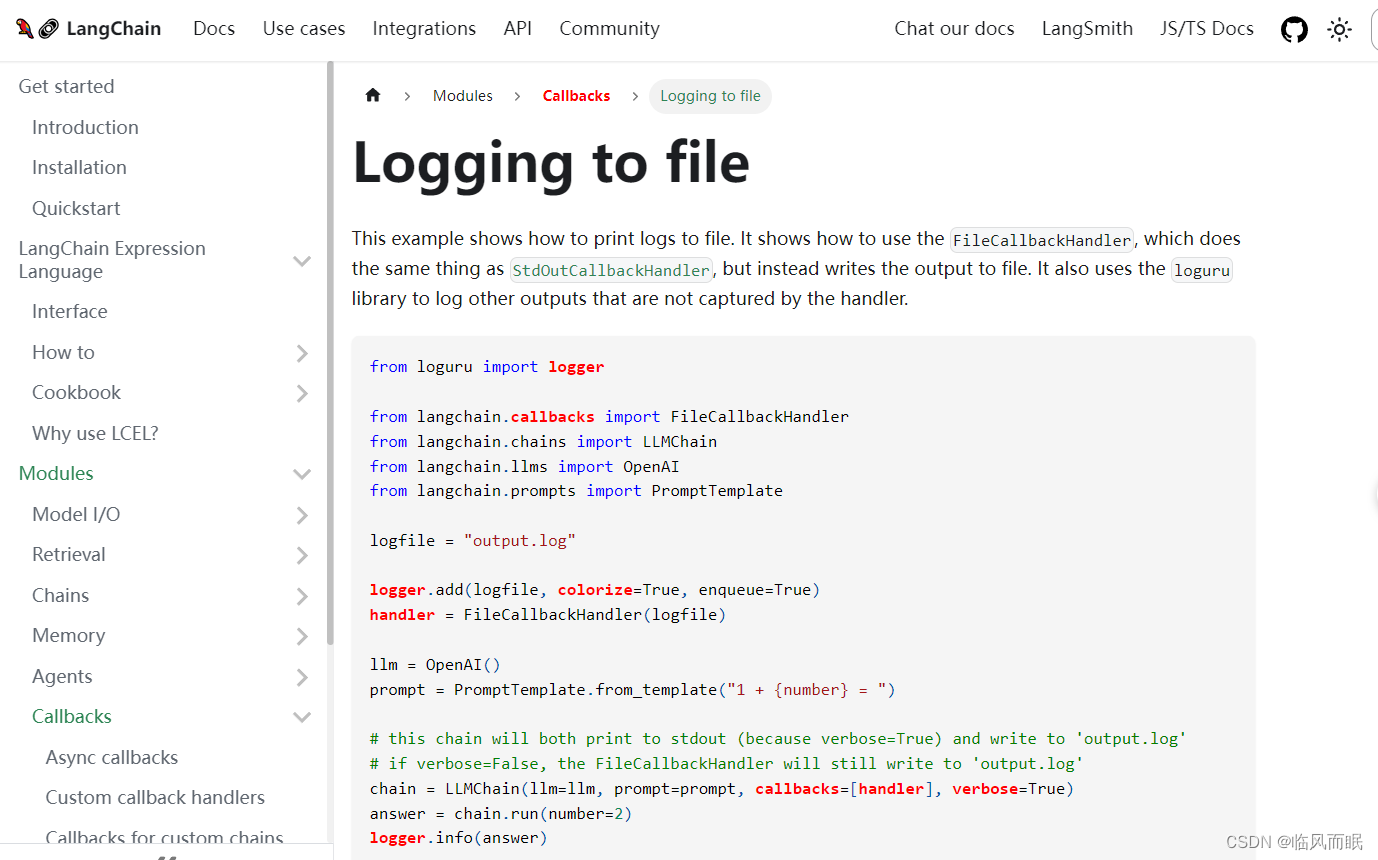
-
跑一下它的demo
from loguru import logger from langchain.callbacks import FileCallbackHandler from langchain.chains import LLMChain from langchain.llms import OpenAI from langchain.prompts import PromptTemplate logfile = "output.log" logger.add(logfile, colorize=True, enqueue=True) handler = FileCallbackHandler(logfile) llm = OpenAI() prompt = PromptTemplate.from_template("1 + {number} = ") # this chain will both print to stdout (because verbose=True) and write to 'output.log' # if verbose=False, the FileCallbackHandler will still write to 'output.log' chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler], verbose=True) answer = chain.run(number=2) logger.info(answer)
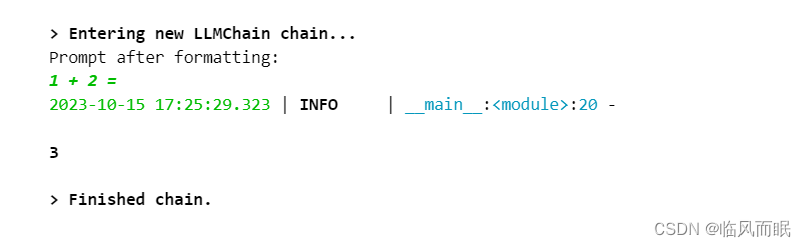
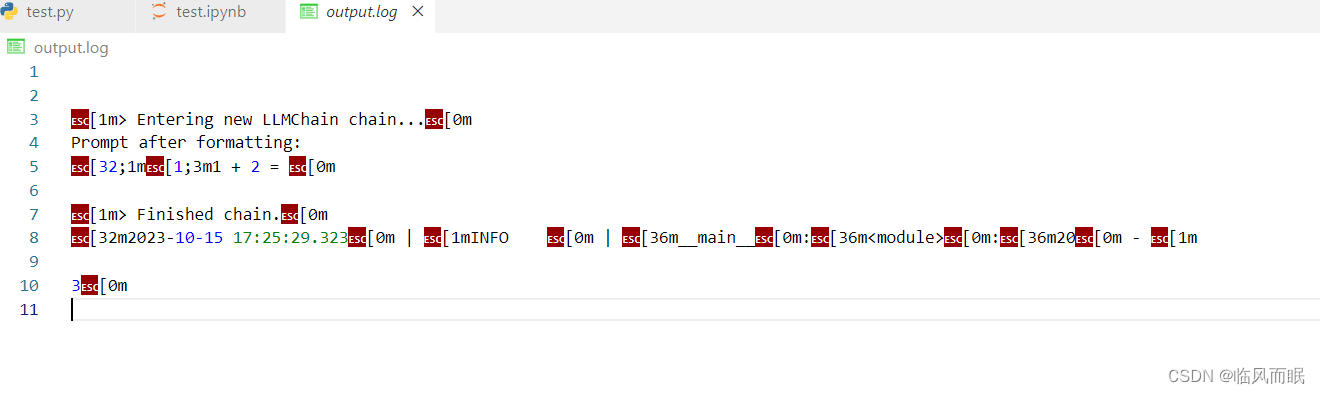
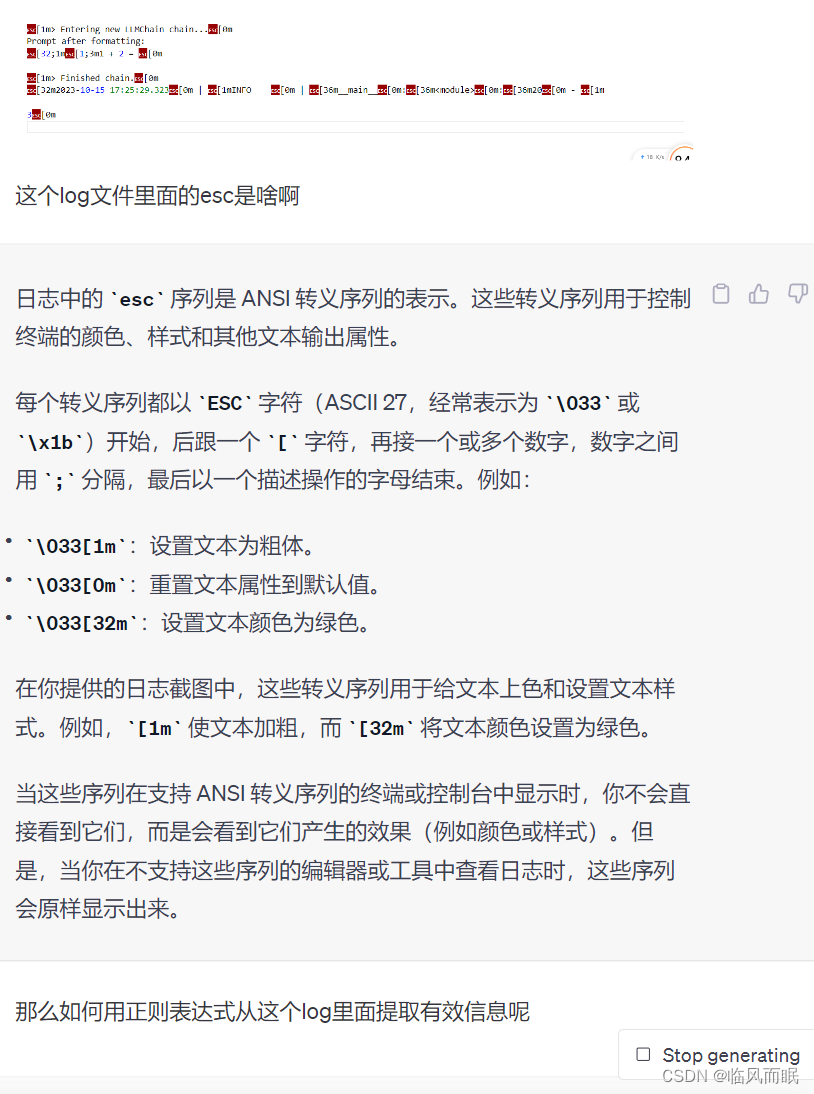
如何提取出来
正则表达式
- chatgpt教我的
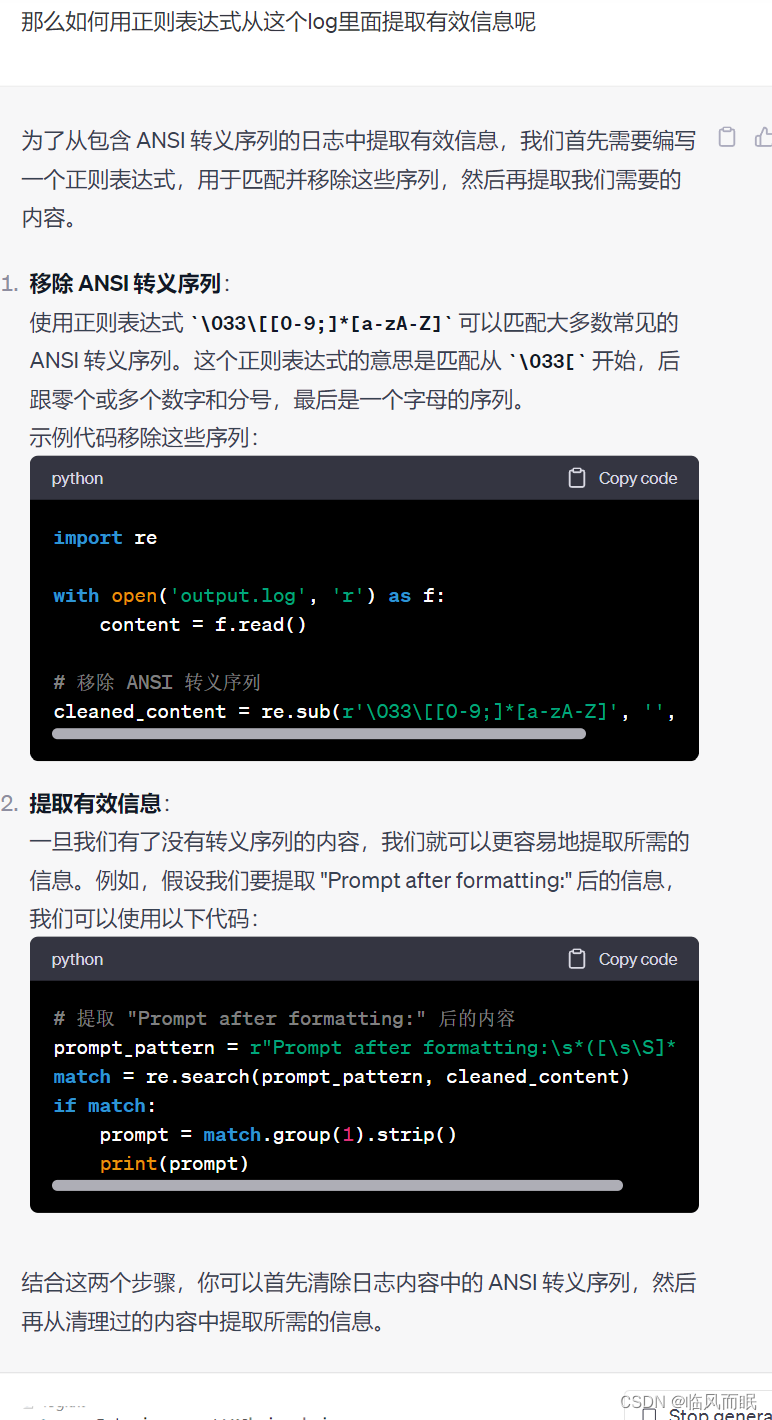
- 试了下有点问题
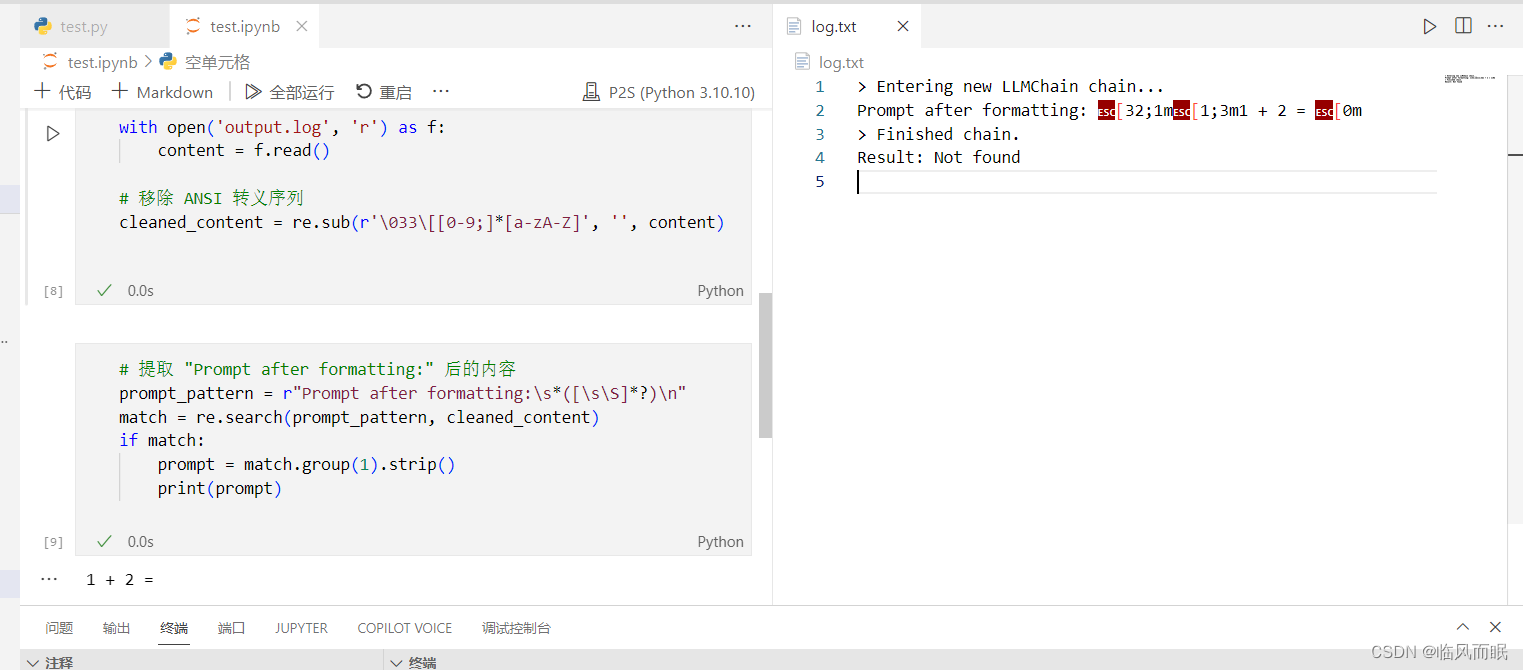
第一步没提取干净,然后最后1+2=3的3也没写出来
官方的方法
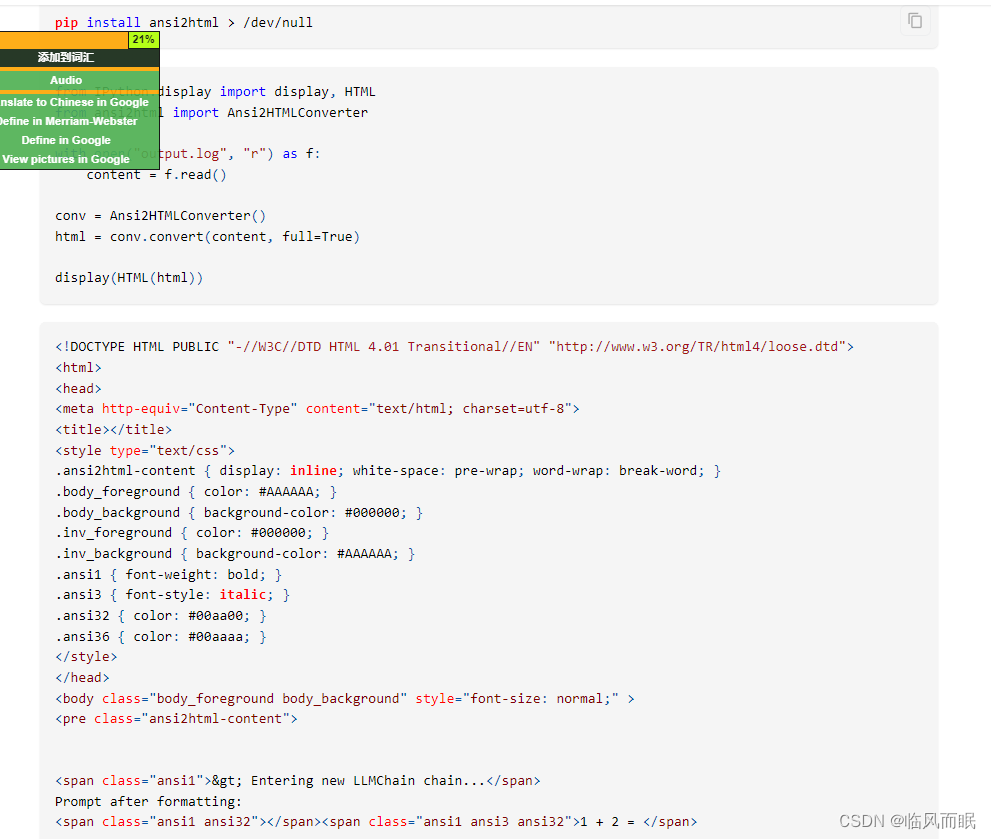
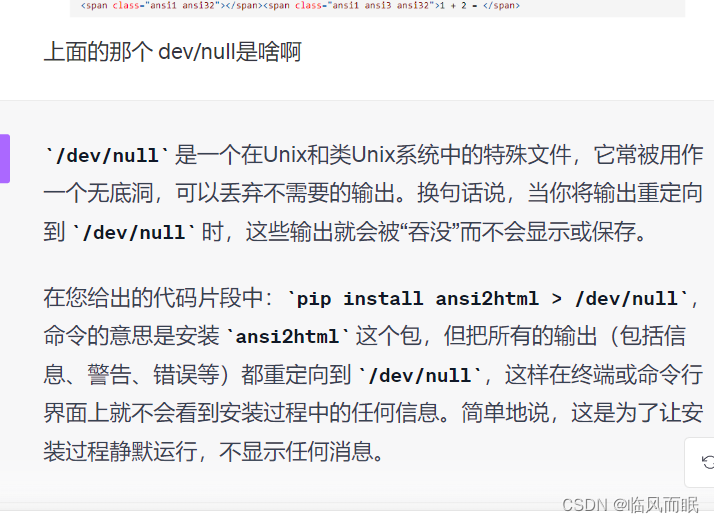
跑一下试试
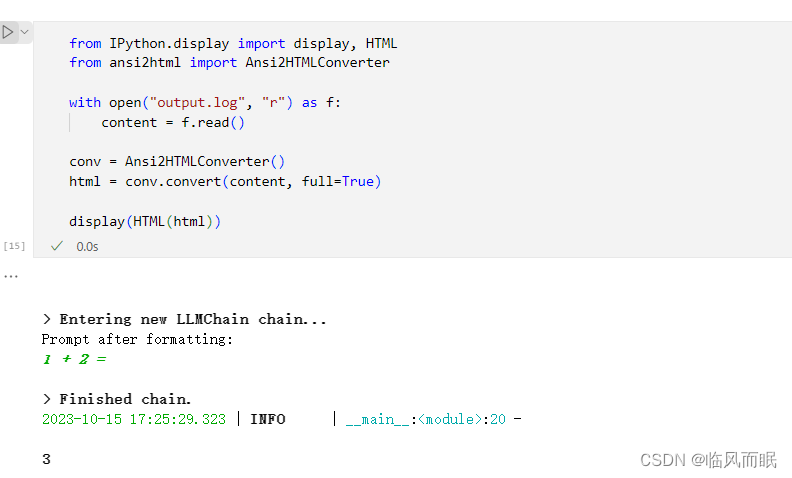
-
不过注意到这个html,那就简单了,用爬虫库就行
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') # 提取<pre>标签中的内容 pre_content = soup.find('pre', class_='ansi2html-content') # 获取所有的文本内容 texts = pre_content.get_text().split('n') # 过滤掉空行 filtered_texts = [text.strip() for text in texts if text.strip()] print('n'.join(filtered_texts))
之后可以把这个转换和提取流程加入到LLM chain运行过程中,就可以把东西提取出来了 ~