【Redis】redis基本数据类型详解(String、List、Hash、Set、ZSet)
Redis
Redis有5种基本的数据结构,分别为:string(字符串)、list(列表)、set(集合)、hash(哈希)和 zset(有序集合)。下面我们依次理解这五种基本数据类型。
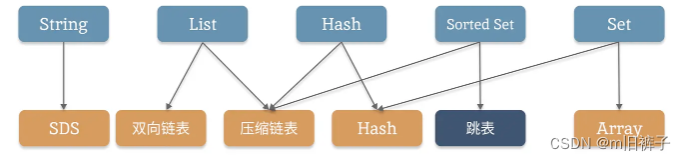
除了String的底层是简单字符串SDS结构,其他类型底层都有两种数据结构支持。
String(字符串)
字符串是Redis最简单的数据结构。Redis所有的数据结构都是以唯一的key字符串作为名称,然后通过这个唯一key值来获取相应的value数据。不同类型的数据结构差异就在于value的结构不一样。

字符串结构使用非常广泛,一个常见的用途就是缓存用户信息。我们将用户信息结构体使用JSON序列化成字符串,然后将序列化后的字符串塞进Redis来缓存。同样,取用户信息会经过一次反序列化的过程。
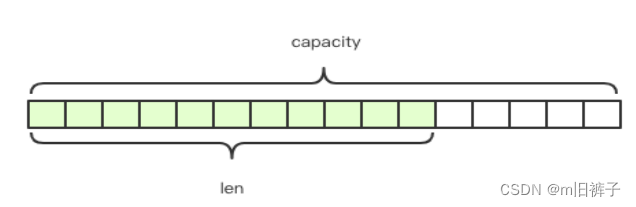
Redis的字符串是动态字符串,是可以修改的字符串,在内存中它是以字节数组的形式存在的,内部实现上采用预分配冗余空间的方式来减少内存的频繁分配,如上图所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串的长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。注意:字符串最大长度为512M
List(列表)
List的插入和删除操作特别快,时间复杂度为O(1),但是索引定位很慢,时间复杂度为O(n)。当列表弹出了最后一个元素之后,该数据结构自动被删除,内存被回收。
Redis的列表结构常常被用来做异步队列使用。将需要延后处理的任务结构体序列化成字符串塞进Redis的列表,另一个线程从这个列表中轮询数据进行处理。
快速列表
如果再深入一点,你会发现Redis底层存储的是一个叫做quicklist的一个结构。

首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成quicklist。因为普通的链表需要的的附加指针空间太大,会比较浪费空间,而且会加重内存的碎片化。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。所以Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能。又不会出现太大的空间冗余。
quicklist内部默认单个ziplist长度为8k字节,超过了这个字节数,就会新起有一个ziplist。
Hash(字典)
字典(dict)是 Redis 服务器中出现最为频繁的复合型数据结构,除了 hash 结构的数据会用到字典外,整个 Redis 数据库的所有 key 和 value也组成了一个全局字典,还有带过期时间的 key 集合也是一个字典。zset 集合中存储 value 和 score 值的映射关系也是通过 dict 结构实现的。
Redis的字典是个无序字典(golang、java中字典也是无序字典),内部实现为数组+链表二维结构。第一维hash的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。
Redis为了高性能,不能堵塞服务,rehash采用的是渐进式策略。
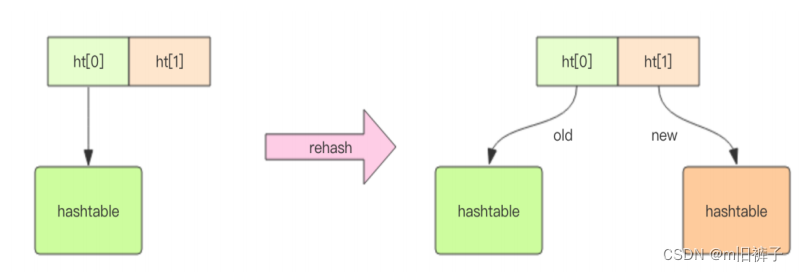
渐进式rehash会在rehash的同时,保留新旧两个hash结构,查询时会同时查询两个hash结构,然后在后续的定时任务中以及hash的子指令中,循序渐进的将旧hash的内容一点点迁移到新的hash结构中。
当 hash 移除了最后一个元素之后,该数据结构自动被删除,内存被回收。hash 结构也可以用来存储用户信息,不同于字符串一次性需要全部序列化整个对象,hash 可以对用户结构中的每个字段单独存储。这样当我们需要获取用户信息时可以进行部分获取。而以整个字符串的形式去保存用户信息的话就只能一次性全部读取,这样就会比较浪费网络流量。
hash 也有缺点,hash 结构的存储消耗要高于单个字符串,到底该使用 hash 还是字符串,需要根据实际情况再三权衡。
扩容条件
正常条件下,当hash表中元素的个数等于第一维数组的长度时,就会开始扩容,扩容的新数组是原数组大小的2倍。不过如果Redis这个在做bgsave,为了减少内存页的过多分离(Copy On Write),Redis尽量不去扩容(dict_can_resize),但是如果hash表已经非常满了,元素的个数已经达到了第一维数组长度的5倍(dict_force_resize_ratio),说明hash表已经过于拥挤了,这个时候就会强制扩容。
缩容条件
当 hash 表因为元素的逐渐删除而变得越来越稀疏时,Redis会对 hash 表进行缩容来减少hash表的第一维数组空间占用。缩容的条件是元素个数低于数组长度的10%。缩容不会考虑Redis是否正在做bgsave。
Set(集合)
Redis的集合内部实现相当于一个特殊的字典,字典中所有的value都是一个值NULL,它内部的键值对是无序的唯一(自动排重)的。
当集合中最后一个元素移除之后,数据结构自动删除,内存被回收。set结构可以用来存储活动中奖的用户ID,因为有去重功能,可以保证同一个用户不会中奖两次。
ZSet(有序集合)
zset可能是Redis提供的最为特色的数据结构,它也是在面试中面试官最爱问的数据结构。一方面它是一个set(字典结构),保证了内部value的唯一性,另一方面它可以给每个value赋予一个score,代表这个value的排序权重。它的内部实现用的是一种叫做【跳跃列表】的数据结构。
zset中最后一个value被移除后,数据结构自动删除,内存被回收。zset可以用来存粉丝列表,value值是粉丝的用户ID,score是关注时间。我们可以对粉丝列表按关注时间进行排序。
zset还可以用来存储学生的成绩,value值是学生的ID,score是他的考试成绩。我们可以对成绩按分数进行排序就可以得到他的名次。
跳跃列表
zset内部的排序功能是通过【跳跃列表】数据结构来实现的,它的结构非常特殊,也比较复杂。
因为 zset 要支持随机的插入和删除,所以它不好使用数组来表示。
先来看一个普通的链表结构:

我们需要这个链表按照 score 值进行排序。这意味着当有新元素需要插入时,要定位到特定位置的插入点,这样才可以继续保证链表是有序的。通常我们会通过二分查找来找到插入点,但是二分查找的对象必须是数组,只有数组才可以支持快速位置定位,链表做不到,那该怎么办呢?
想想一个创业公司,刚开始只有几个人,团队成员之间人人平等,都是联合创始人。随着公司的成长,人数渐渐变多,团队沟通成本随之增加。这时候就会引入组长制,对团队进行划分。每个团队会有一个组长。开会的时候分团队进行,多个组长之间还会有自己的会议安排。公司规模进一步扩展,需要再增加一个层级 — 部门,每个部门会从组长列表中推选出一个代表来作为部长。部长们之间还会有自己的高层会议安排。
跳跃列表就是类似于这种层级制,最下面一层所有的元素都会串起来。然后每隔几个元素挑选出一个代表来,再将这几个代表使用另外一级指针串起来。然后在这些代表里再挑出来二级代表 ,再串起来。最终就形成了金字塔结构。
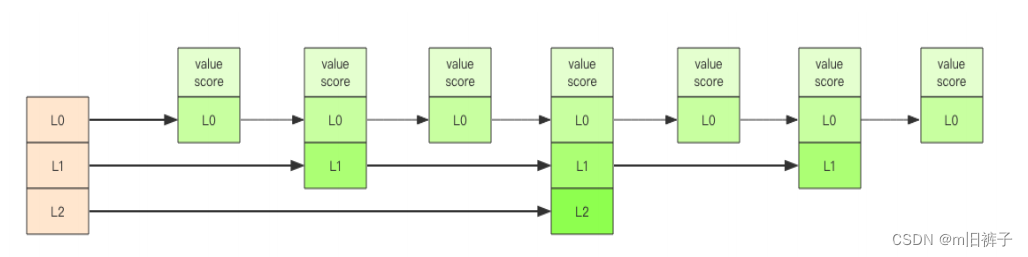
【跳跃列表】之所以【跳跃】,是因为内部的元素可能【身兼数职】,比如上图中间的这个元素,同时处于 L0、L1和L2层,可以快速再不同层次之间进行【跳跃】。
定位插入点时,先在顶层进行定位,然后下潜到下一级定位,一直下潜到最底层找到合适的位置,将新元素插进去。那新插入的元素如何才有机会【身兼数职】呢?
跳跃列表采取一个随机策略来决定新元素可以兼职到第几层。
首先 L0 层肯定是100%了,L1层只有50%的概率,L2层只有25%的概率,L3层只有12.5%的概率,一直随机到最顶层L31层。绝大多数元素都过不了几层,只有极少数元素可以深入到顶层。列表中的元素越多,能够深入的层次就越深,能进入到顶层的概率就会越大。
查找过程
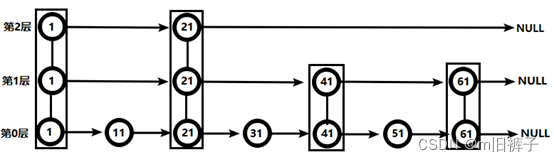
-
从第2层开始,因为 1 节点比 51 节点小,向后比较。
-
21 节点比 51 节点小,继续向后比较,后面就是NULL了,所以从 21 节点向下到第 1 层
-
到第 1 层,41 节点比 51 节点小,继续向后, 61 节点比 51 节点大,所以从 41 向下
-
到第 0 层,51 节点为要查找的节点,节点被找到,共查找 4 次。
问题:为什么不采用树或者红黑树,或者像MySQL一样采用B树?(跳表和其他数据类型的区别)
两个核心问题:
- Redis的定位,也即问题的背景。Redis是一个内存数据库,在时间复杂度差不多的情况下,优先选择内存占用较小(也就是空间复杂度较低)的数据结构,而且相对而言跳表的实现起来更简单(它们更容易实现、调试等等)。
- 跳表和树的区别,尤其是数据结构上的区别。树需要大量的指针来记录节点信息,树越高,开销越大。跳表在这方面要好得多。在插入数据时,跳表可能会调整索引,树需要再平衡,各有特点。