机器学习:决策树
决策树
决策树是一种基于树形结构的模型,决策树从根节点开始,一步步走到叶子节点(决策),所有的数据最终都会落到叶子节点,既可以做分类也可以做回归。
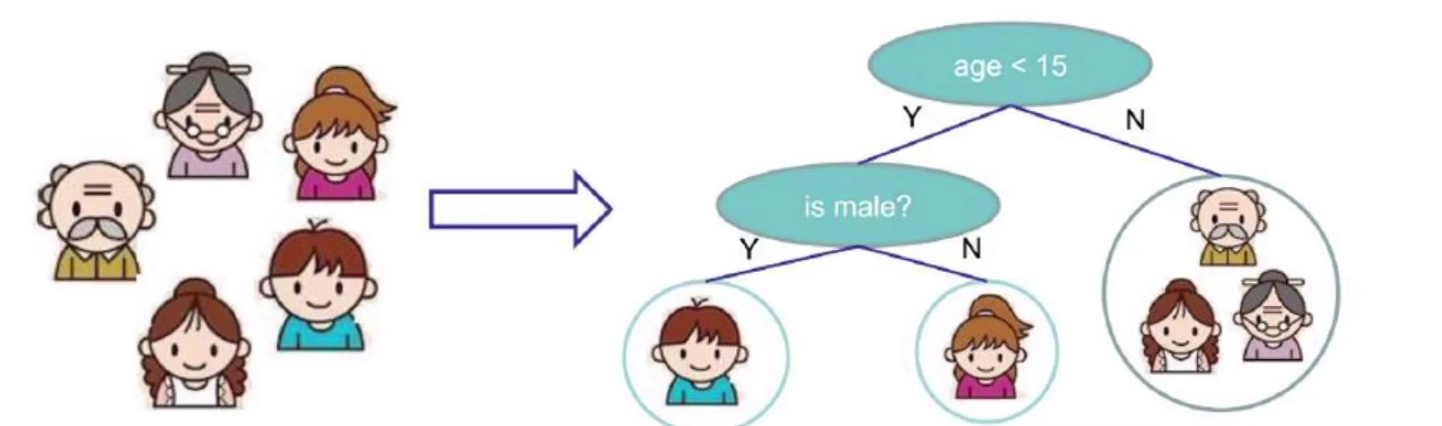
特征选择
根节点的选择该用哪一个特征呢?接下来的节点呢?我们的目标是根节点就像大当家一样可以更好的决策数据,根节点下面的节点自然是二当家,以此类推下去。所以需要找到一种衡量标准,来计算通过不同特征进行分支选择后的分类情况,找出最好的个当成根节点,以此类推。
1.信息增益
首先介绍一下熵的概念:熵是表示随机变量不确定性的度量。其实就是集合的混乱程度。举个例子,A集合[1,1,1,1,1,1,1,2,2],B集合[1,2,3,4,5,6,7,8,9],显然A集合的熵值要低,因为A里面只有两种类别,相对稳定稳定一些,B中种类很多,熵值就会大很多。计算公式如下:其中 D 表示样本集, K 表示样本集分类数,pk表示第 k 类样本在样本集所占比例。Ent(D) 的值越小,样本集的纯度越高。
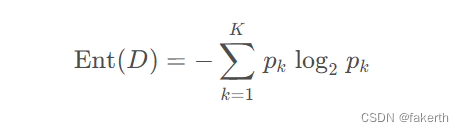
下式表示用一个离散属性划分后对样本集的影响,被称为信息增益(Information Gain),其中 D 表示样本集,a 表示离散属性,V 表示离散属性 a 所有可能取值的数量,Dv表示样本集中第v种取值的子样本集。
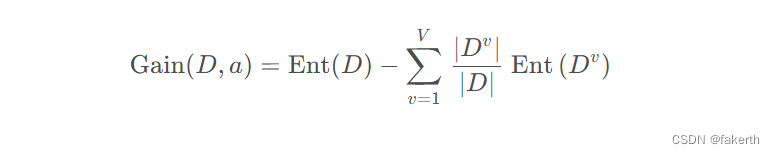
当属性是连续属性时,其可取值不像离散属性那样是有限的,这时可以将连续属性在样本集中的值排序后俩俩取平均值作为划分点,如下式所示,其中 Ta表示平均值集合,Dtv表示子集合,当 v = - 时表示样本中小于均值 t 的样本子集,当 v = + 时表示样本中大于均值t的样本子集,取划分点中最大的信息增益作为该属性的信息增益值。
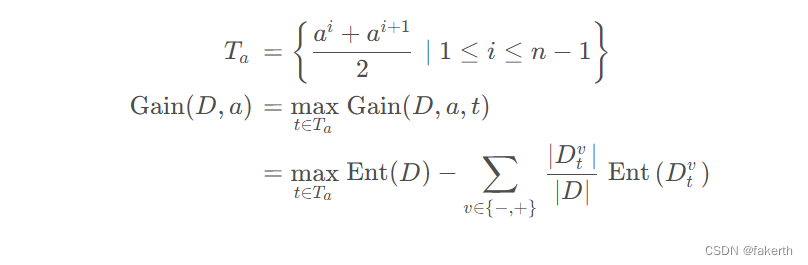
Gain(D, a) 的值越大,样本集按该属性划分后纯度的提升越高。由此可找到最合适的划分属性。
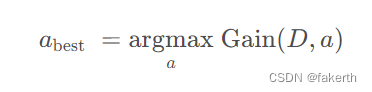
2.基尼系数
介绍一下基尼值,如下式所示,其中 D 表示样本集, K 表示样本集分类数,pk表示第 k 类样本在样本集所占比例。Gini(D) 的值越小,样本集的纯度越高。
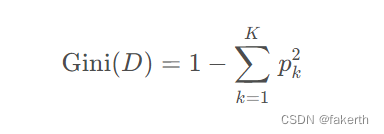
下式表示用一个离散属性划分后对样本集的影响,被称为基尼指数(Gini Index),其中 D 表示样本集,a 表示离散属性,V 表示离散属性 a 所有可能取值的数量,Dv表示样本集中第 v 种取值的子样本集。
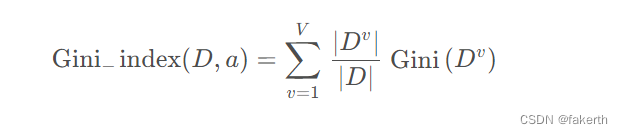
对于连续属性,将连续属性排序后俩俩取平均值作为划分点,如下式,其中 Ta表示平均值集合,Dtv表示子集合,当 v = - 时表示样本中小于均值 t 的样本子集,当 v = + 时表示样本中大于均值 t 的样本子集,取划分点中最小的基尼指数作为该属性的基尼指数值。
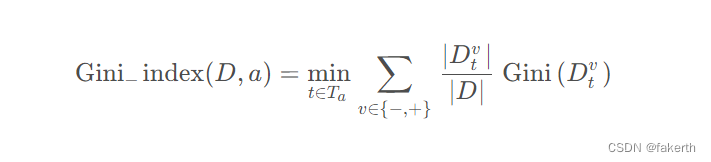
Gini_index(D, a) 的值越小,样本集按该离散属性划分后纯度的提升越高。由此可找到最合适的划分属性。
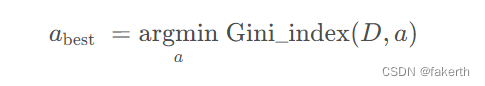
3.均方误差
前面两种指标使得决策树可以用来做分类问题,那么决策树如果用来做回归问题时,就需要不同的指标来决定划分的特征,这个指标就是如下式所示的均方误差(MSE),其中 Ta表示平均值集合,ytv表示子集合标签,当 v = - 时表示样本中小于均值 t 的样本子集标签,当 v = + 时表示样本中大于均值 t 的样本子集标签,后一项为对应子集合标签的均值。
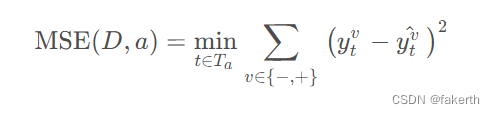
MSE(D, a) 的值越小,决策树对样本集的拟合程度越高。由此可找到最合适的划分属性。
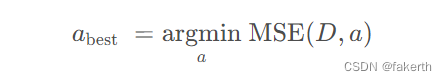
决策树剪枝策略
决策树剪枝的效果可以在以下几个方面体现:
防止过拟合,提高模型的泛化能力:剪枝可以减少决策树的复杂性,避免过度拟合训练数据。剪枝可以降低决策树的复杂度,使其更具有泛化能力。剪枝后的树更加简单,去除了过多的冗余信息和噪声,更能捕捉数据中的一般规律,而不是过多关注个别训练样本的特异性。
减少决策树的复杂度:剪枝可以通过减少决策树的叶子节点数量和分支数量来简化模型。简化后的决策树更易于理解和解释,并且可以减少计算和存储的需求。
提高模型的可解释性:剪枝后的决策树更为简洁,更容易理解和解释。剪枝可以去除决策树中的一些不必要的细节和分支,使决策过程更加清晰明了。
1.预剪枝
边建立决策树边剪枝,限制深度,叶子节点个数,叶子节点样本数,信息增益量等。
2.后剪枝
建立决策树后再进行剪枝,通过一定的衡量标准进行剪枝。叶子节点越多,损失越大。
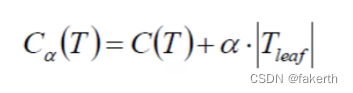
决策树实现
from sklearn import tree
import os
import pandas as pd
import numpy as np
import sklearn
import xgboost as xgb
from utils.features import *
import warnings
warnings.filterwarnings("ignore")
def load_datasets():
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
df = pd.read_pickle('****.pickle')
features = darshan_features
print(df.head(10))
df_train, df_test = sklearn.model_selection.train_test_split(df, test_size=0.2)
X_train, X_test = df_train[features], df_test[features]
print(X_test)
y_train, y_test = df_train["value"], df_test["value"]
print(y_test)
return X_train, X_test, y_train, y_test
def model_train(X_train, X_test, y_train, y_test):
# 决策树回归
clf = tree.DecisionTreeRegressor()
# 拟合数据
clf = clf.fit(X_train, y_train)
y_pred_test = clf.predict(X_test)
print(y_test)
print(y_pred_test)
error = np.median(10 ** np.abs(y_test - y_pred_test))
print(error)
def main():
X_train, X_test, y_train, y_test = load_datasets()
model_train(X_train, X_test, y_train, y_test)
if __name__ == "__main__":
main()