通过案例实战详解elasticsearch自定义打分function_score的使用
前言
elasticsearch给我们提供了很强大的搜索功能,但是有时候仅仅只用相关度打分是不够的,所以elasticsearch给我们提供了自定义打分函数function_score,本文结合简单案例详解function_score的使用方法,关于function-score-query的文档最权威的莫过于官方文档:
function_score官方文档
基本数据准备
我们创建一张新闻表,包含如下字段:
| 字段 | 类型 | 说明 |
|---|---|---|
| id | Long | 新闻ID |
| title | string | 标题 |
| tags | string | 标签 |
| read_count | long | 阅读数 |
| like_count | long | 点赞数 |
| comment_count | long | 评论数 |
| rank | double | 自定义权重 |
| location | arrays | 文章发布经纬度 |
| pub_time | date | 发布时间 |
创建elasticsearch的 Mapping:
PUT /news
{
"mappings": {
"properties": {
"id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "standard"
},
"tags": {
"type": "keyword"
},
"read_count": {
"type": "long"
},
"like_count": {
"type": "long"
},
"comment_count": {
"type": "long"
},
"rank": {
"type": "double"
},
"location": {
"type": "geo_point"
},
"pub_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm||yyyy-MM-dd||epoch_millis"
}
}
}
}
准备测试数据:
| id | title | tags | read_count | comment_count | like_count | rank | location | pub_time |
|---|---|---|---|---|---|---|---|---|
| 1 | 台风“杜苏芮”登陆福建晋江 多部门多地全力应对 | 台风;杜苏芮;福建 | 10000 | 2000 | 600 | 0 | 118.55199,24.78144 | 2023-07-29 09:47 |
| 2 | 受台风“杜苏芮”影响 北京7月29日至8月1日将有强降雨 | 台风;杜苏芮;北京 | 1000 | 200 | 60 | 0 | 116.23128,40.22077 | 2023-06-29 14:49:38 |
| 3 | 杭州解除台风蓝色预警信号 | 台风;杭州 | 10 | 2 | 6 | 0.9 | 120.21201,30.2084 | 2020-07-29 14:49:38 |
批量添加数据到elasticsearch中:
POST _bulk
{"create": {"_index": "news", "_id": 1}}
{"comment_count":600,"id":1,"like_count":2000,"location":[118.55199,24.78144],"pub_time":"2023-07-29 09:47","rank":0.0,"read_count":10000,"tags":["台风","杜苏芮","福建"],"title":"台风“杜苏芮”登陆福建晋江 多部门多地全力应对"}
{"create": {"_index": "news", "_id": 2}}
{"comment_count":60,"id":2,"like_count":200,"location":[116.23128,40.22077],"pub_time":"2023-06-29 14:49:38","rank":0.0,"read_count":1000,"tags":["台风","杜苏芮","北京"],"title":"受台风“杜苏芮”影响 北京7月29日至8月1日将有强降雨"}
{"create": {"_index": "news", "_id": 3}}
{"comment_count":6,"id":3,"like_count":20,"location":[120.21201,30.208],"pub_time":"2020-07-29 14:49:38","rank":0.99,"read_count":100,"tags":["台风","杭州"],"title":"杭州解除台风蓝色预警信号"}
random_score的使用
我们通过random_score理解一下weight、score_mode,boost_mode的作用分别是什么,先直接看Demo
GET /news/_search
{
"query": {
"function_score": {
"query": {"match": {
"title": "台风"
}},
"functions": [
{
"random_score": {},
"weight": 1
},
{
"filter": { "match": { "title": "杭州" } },
"weight":42
}
],
"score_mode": "sum",
"boost_mode": "replace"
}
}
}
对应JAVA查询代码:
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
queryBuilder.should(QueryBuilders.matchQuery("title","杭州"));
FunctionScoreQueryBuilder.FilterFunctionBuilder[] filterFunctionBuilders = new FunctionScoreQueryBuilder.FilterFunctionBuilder[1];
ScoreFunctionBuilder<RandomScoreFunctionBuilder> randomScoreFilter = new RandomScoreFunctionBuilder();
((RandomScoreFunctionBuilder) randomScoreFilter).seed(2);
filterFunctionBuilders[0] = new FunctionScoreQueryBuilder.FilterFunctionBuilder(randomScoreFilter);
FunctionScoreQueryBuilder query = QueryBuilders.functionScoreQuery(queryBuilder, filterFunctionBuilders).scoreMode(FunctionScoreQuery.ScoreMode.SUM).boostMode(CombineFunction.SUM);
SearchSourceBuilder searchSourceBuilder= new SearchSourceBuilder().query(query);
SearchRequest searchRequest= new SearchRequest().searchType(SearchType.DFS_QUERY_THEN_FETCH).indices("news").source(searchSourceBuilder);
SearchResponse response = restClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
String searchSource;
for (SearchHit hit : hits)
{
searchSource = hit.getSourceAsString();
System.out.println(searchSource);
}
查询结果:
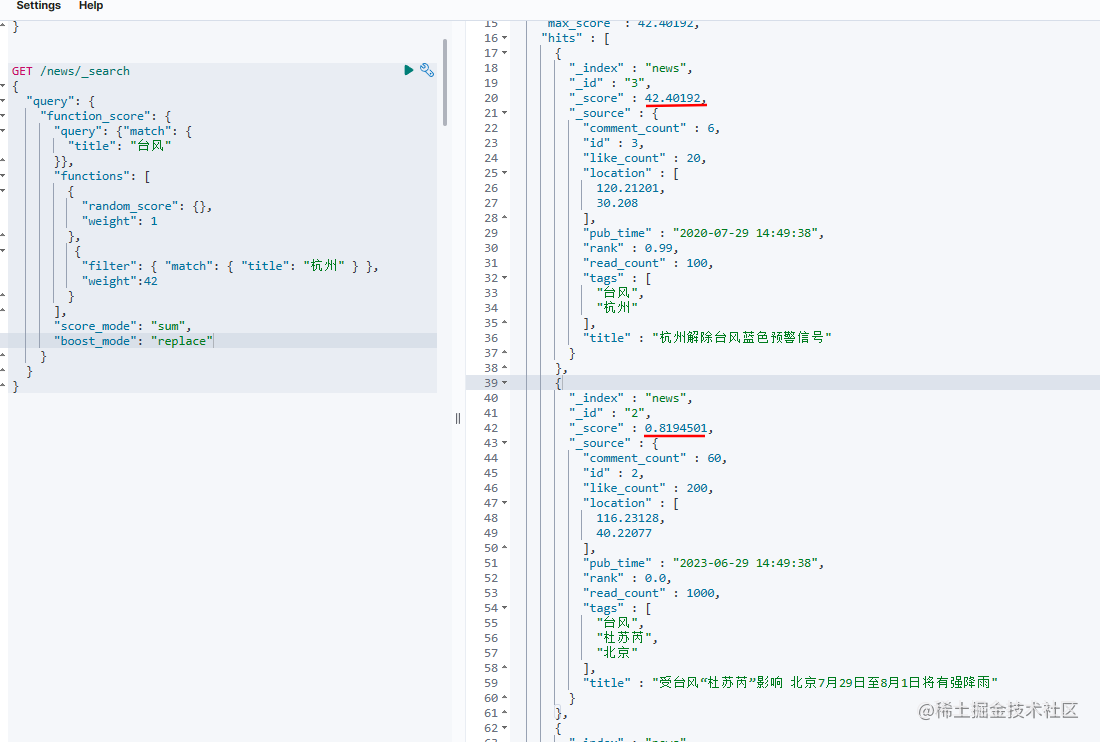
这个查询使用的function_score,query中通过title搜索“台风”,在functions我们增加了两个打分,一个是random_score,随机生成一个得分,得分的weight权重是1,第二个是如果标题中有“杭州”,得分权重为42,
-
random_score
顾名思义就是生成一个(0,1)之间的随机得分,我能想到的一个应用场景是,有一天产品要求:每个人看到新闻都不一样,要做到“千人千面”,而且只给你一天的时间,这样我们就可以使用random_score,每次拉取的数据都是随机的,每个人看到的新闻都是不一样的,这个随机查询比Mysql实现简单多了,0成本实现了“千人千面”。 -
weight
这个就是给生成的得分增加一个权重,在上面的Demo中,我们第一个weight=1,第二个weight=42,从搜索结果得分可以看出“杭州解除台风蓝色预警信号”这条得分是42.40192,而下面的只有0.8194501,因为增加了42倍的权重。 -
score_mode
score_mode的作用是对functions中计算出来的多个得分做汇总计算,比如我用了是sum,就是指将上面random_score得到的打分和filter中得到的42分相加,也就是说第一条42.40192得分是random_score生成了0.40192再加上filter中得到了42分。score_mode默认是采用multiply,总共有6种计算方式:
random_score函数 |
计算方式 |
|---|---|
multiply |
scores are multiplied (default) |
sum |
scores are summed |
avg |
scores are averaged |
first |
the first function that has a matching filter is applied |
max |
maximum score is used |
min |
minimum score is used |
boost_mode
boost_mode作用是将functions得到的总分数和我们query查询的得到的分数做计算,比如我们使用的是replace就是完全使用functions中的得分替代query中的得分,boost_mode总共有6种计算方式:
boost_mode函数 |
得分计算方式 |
|---|---|
multiply |
query score and function score is multiplied (default) |
replace |
only function score is used, the query score is ignored |
sum |
query score and function score are added |
avg |
average |
max |
max of query score and function score |
min |
min of query score and function score |
script_score的使用
script_score就是用记可以通过各种函数计算你文档中出现的字段,算出一个自己想要的得分,我们直接看Demo
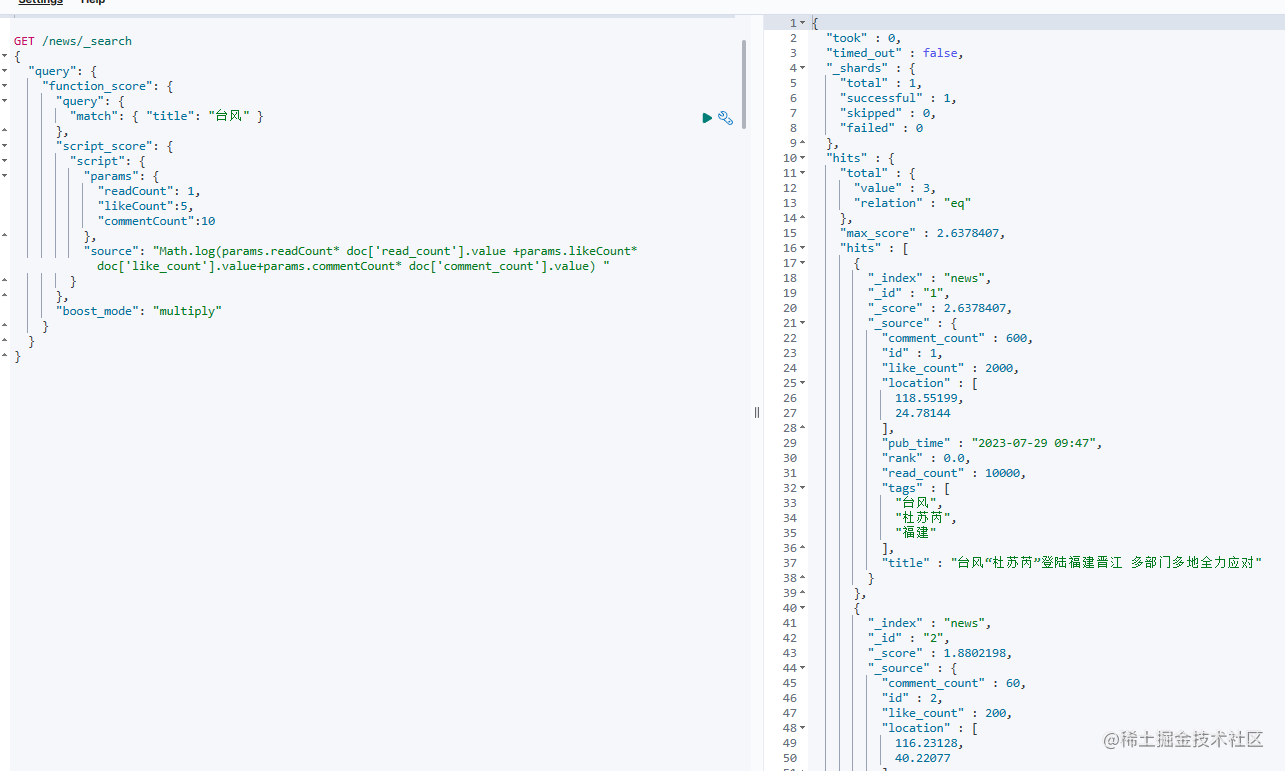
GET /news/_search
{
"query": {
"function_score": {
"query": {
"match": { "title": "台风" }
},
"script_score": {
"script": {
"params": {
"readCount": 1,
"likeCount":5,
"commentCount":10
},
"source": "Math.log(params.readCount* doc['read_count'].value +params.likeCount* doc['like_count'].value+params.commentCount* doc['comment_count'].value) "
}
},
"boost_mode": "multiply"
}
}
}
每篇新闻有阅读数、点赞数据、评论数,我们可以通过这三个指标算出一个分值来评价一篇文章的热度,然后将这个热度和query中的得分相乘,这样热度很高的文章可以排到更前面。在这个Demo中我使用了一个简单的加权来计算文章热度,一般来说阅读数是最大的,点赞数次之,评论数是最小的。
文章热度 = L o g ( 评论数 × 10 + 点赞数 × 5 + 阅读数 ) 文章热度=Log(评论数times 10+点赞数times5+阅读数) 文章热度=Log(评论数×10+点赞数×5+阅读数)
这里为了演示,简单算一下文章热度,真实的要比这个复杂的多,可能不同种类的文章重要性也是不一样的。
field_value_factor的使用
field_value_factor可以理解成elasticsearch给你一些内置的script_score,每次写script_score必定不是太方便,如果有一些内置的函数,开箱即用就方便多了,我们直接看Demo
GET /news/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "台风"
}
},
"field_value_factor": {
"field": "rank",
"factor": 10,
"modifier": "sqrt",
"missing": 1
},
"boost_mode": "multiply"
}
}
}
这里的field_value_factor就对相当script_score的 sqrt(10 * doc['rank'].value),这里的factor是乘以多少倍,默认是1倍,missing是如果没有这个字段默认值为1,modifier是计算函数,field是要计算的字段。
modifier计算函数有以下类型可以选择
modifier函数 |
得分计算方式 |
|---|---|
none |
Do not apply any multiplier to the field value |
log |
Take the common logarithm of the field value. Because this function will return a negative value and cause an error if used on values between 0 and 1, it is recommended to use log1p instead. |
log1p |
Add 1 to the field value and take the common logarithm |
log2p |
Add 2 to the field value and take the common logarithm |
ln |
Take the natural logarithm of the field value. Because this function will return a negative value and cause an error if used on values between 0 and 1, it is recommended to use ln1p instead. |
ln1p |
Add 1 to the field value and take the natural logarithm |
ln2p |
Add 2 to the field value and take the natural logarithm |
square |
Square the field value (multiply it by itself) |
sqrt |
Take the square root of the field value |
reciprocal |
Reciprocate the field value, same as 1/x where x is the field’s value |
衰减函数Decay functions的使用
衰减函数可以理解成计算文档中某一个字段与给定值的距离,如果距离越近得分就越高,距离越远得分就越低,这个就比较适用于新闻发布时间的衰减了,越久前发布的新闻,得分应该越小,排序越往后。我们直接看Demo
GET /news/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "台风"
}
},
"functions": [
{
"gauss": {
"pub_time": {
"origin": "now",
"offset": "7d",
"scale": "60d",
"decay": 0.9
}
}
},
{
"exp": {
"location": {
"origin": {
"lat": 120.21551,
"lon": 30.25308
},
"offset": "50km",
"scale": "50km",
"decay": 0.1
}
}
}
],
"score_mode": "sum",
"boost_mode": "sum"
}
}
}
搜索结果:

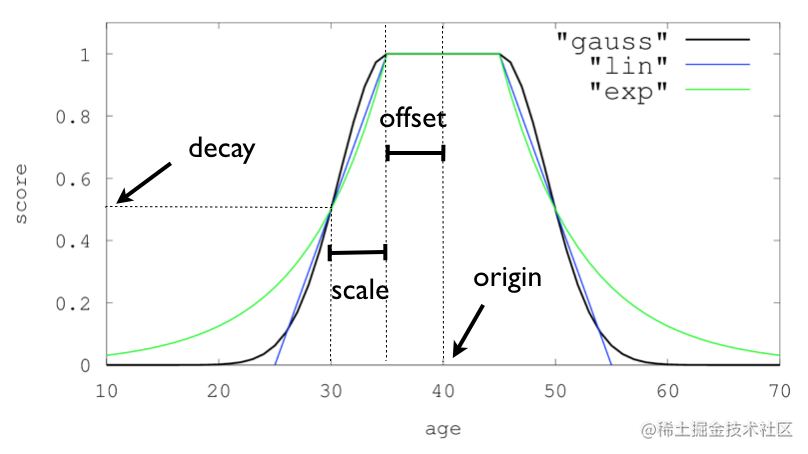
衰减函数有3种,分别为gauss高斯函数、lin线程函数、exp对数函数,具体的计算公式可以参考官方文档,这里我们主要理解衰减函数的4个参数作用是什么。
-
origin
可以理解成计算距离的原点,比如上面计算新闻发布时间的原点是当前时间,计算经纬度的原点是用户搜索位置,比如我在杭州,那么origin就是杭州的经纬度 -
offset
这个偏移量可以理解成不需要衰减的距离,比如在上面的Demo中,距离pub_time的offset为7d,意思是说近7天内发布的新闻都不需要衰减,得分直接为1。计算经纬度中的offset为50km意思是说距离用户50km里的新闻不需要衰减,50km内的基本都是杭州本地的新闻,就没必要衰减了。 -
scale和decay
这两个参数可以参考官方给的三种函数衰减图,scale和decay表示距离为scale后得分衰减到原来的scale倍。比如上面时间衰减offset=7d, scale=60d,decay= 0.9加起来的意思就是7天内的新闻不衰减,67天(7d+60d)前的新闻得分为0.9,在经纬度衰减中offset=50km, scale=50km,decay= 0.1的意思是50km内的距离不衰减,100km(50km+50km)外的数据得分为0.1。
总结
elasticsearch的function_score给我提供了好几种很灵活的自定义打分策略,在实际项目中需要根据自己的需求合理的组合这些打分策略并调整对应参数才能满足自己的搜索需求,本文主要介绍function_score的使用,接下来我会根据一个实际的搜索应用介绍一下如何组合、设置这些函数以达到比较理解的搜索效果。