Mysql 查询分组数据中每组某一数值最大的数据
方法一、将时间进行排序后再分组
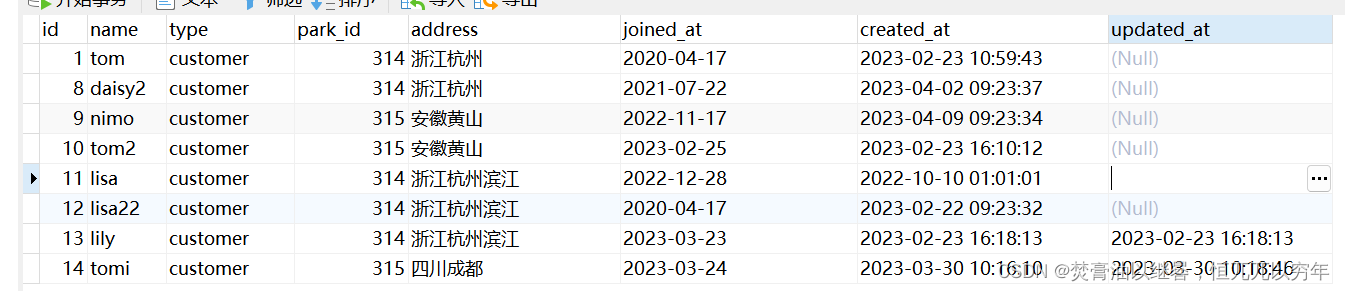
该表表名为customer, park_id表示园区id,joined_at表示用户的加入时间,created_at表示用户的创建时间。
需求:查出每个园区中,最早加入园区的第一位用户
select * from (select * from customer order by joined_at,created_at asc limit 1000) as tem group by park_id;查出id为 1和9的两条数据
解题思路:
【提示】 此处使用 limit 是为了确保,group by分组的时候会按照子查询中输出的排列顺序进行分组。
group by 之后拿取的数据,是每个分组中的第一条数据。
所以我们只需要保证将joined_at时间最早的数据排在最前面,当以park_id进行分组操作时,拿到的第一条数据必然是joined_at时间最早的一条。
(数据重复时的处理)观察表我们可以看到id为1和12的数据都是2020-04-17加入的,但是两者之间他们的创建时间又有先后顺序的区分,id为12的要早一天,所以我们需要的是id为12的。 此刻我们就在排序的时候将created_at的排序加在joined_at后面。
这样就实现了在主要字段joined_at有重复数据的时候,我们按照第二个排序规则created_at字段进行追加排序,并拿取joined_at和created_at时间为最新的

方法二、拿取到每组最小时间并进行关联查询
需求:查询出每个园区最早加入的客户信息
select * from customer as c right join (select park_id,min(joined_at) as min_joined_at from customer group by park_id) as tem
on c.park_id=tem.park_id and c.joined_at=tem.min_joined_at;查询结果:

根据查询可以看出,314园区的两条加入时间最早的数据都被查询了出来。
解题思路:
1. 子查询是按照park_id进行分组,并使用sql函数min 拿取到每组中加入时间最小的时间min_joined_at。并行程临时表tem
2. 根据拿取到的每个园区最小的加入时间关联查询,将其和customer表进行关联,按照park_id相等,且用户的加入时间于最小的加入时间min_joined_at相等来拿取对应的数据。
总结:由以上两个操作观察可知,
第一个方法更适合拿取按照条件进行分组后数据有重复,但我们仅取一条的需求。或者是有多个排序规则,我们按照多个排序规则进行处理后,拿取其中最匹配的一条。需要注意的一点是oracle并不支持该种方法
方法二更适合按条件分组后没有重复数据,或者有重复数据,且我们是要拿取所有符合条件的重复数据。