GCP学习笔记(三)——存储和安全
文章目录
在GCP中,我们需要序列化数据使数据能够进行存储和转换。Avro时一种数据序列化方法,可以将数据转换为二进制。
非结构化数据通常存储在Cloud Storage中,结构化数据的存储方式可以由下图决定。
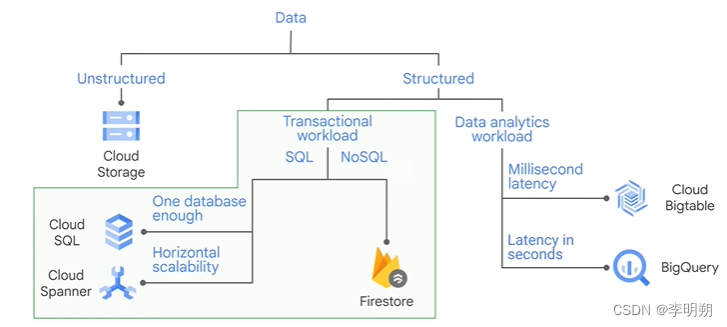
Transactional workload:需要快速插入或更新。80%写入,20%读
Analytics workload:偏向于读取整个数据集,用于决策或计划。20%写入,80%读
下面是一些存储方法的对比
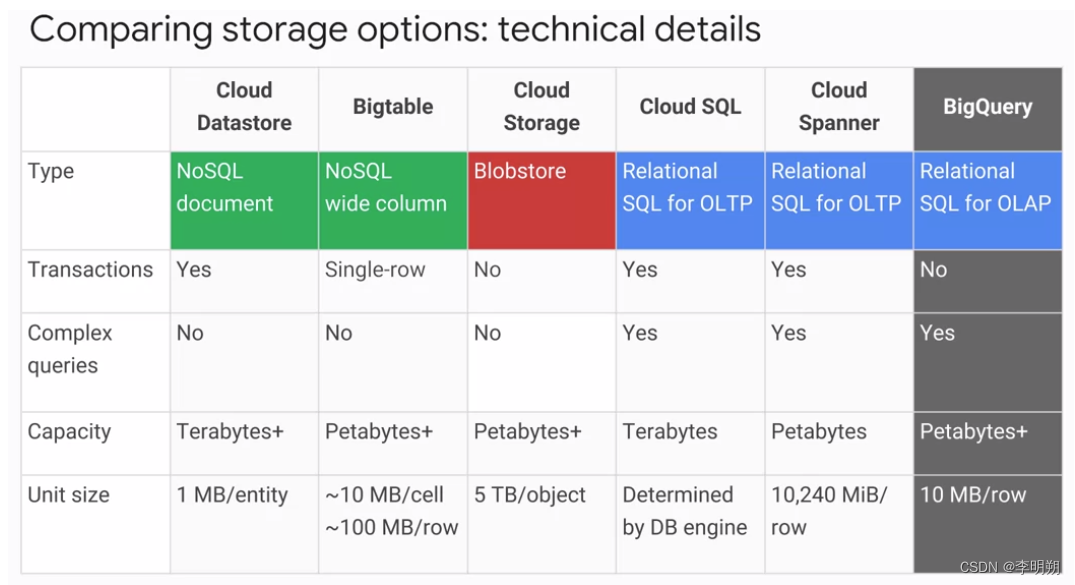
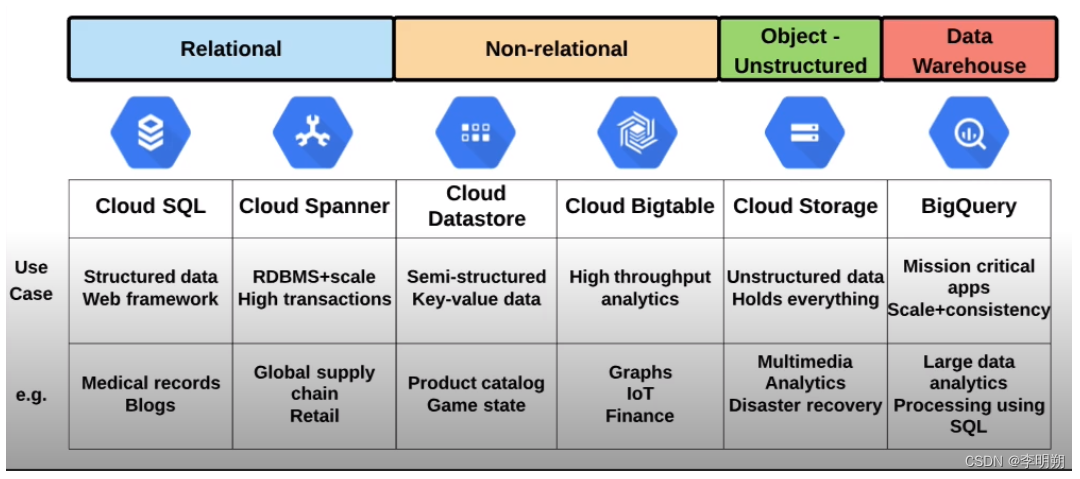
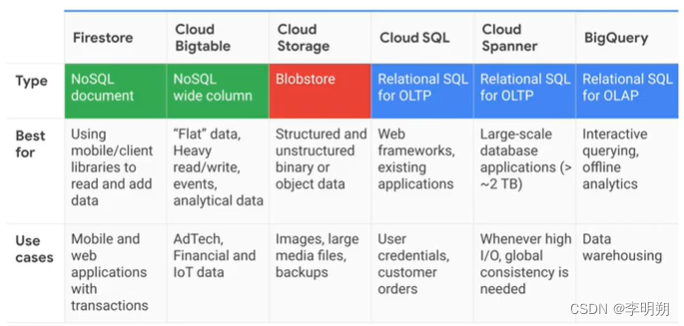
数据仓库和数据湖的区别:
- 数据湖是指原始未经组织的数据
- 数据仓库是指结构化的、组织化的数据
一、Cloud Storage
Cloud Storage是用来存储非结构化数据的可管理服务。在创建项目后,可以创建buckets并向bucket上传数据或者从bucket下载数据。
Cloud Storage有四种存储类型,分别是
- 标准存储(standard storage):用来存放经常存取的数据
- Nearline Storage:存储不经常访问的数据,例如每个月存取一次、数据备份
- Coldline Storage:存储不经常访问的数据,例如每三个月存取一次
- Archive Storage:存储不经常访问的数据,例如每年存取一次、灾难恢复
Cloud Storage的特点:Persistance、Durable、Consistency、Avaliablity、High throughput。
Cloud Storage的核心是桶(bucket)和对象:
- 桶是对象容器,桶具有全局命名空间,意味着不允许使用同名的桶。选择最接近的区域存放会减少延迟。Cloud Storage会存储桶的复制品防止数据丢失。
- 对象存在于桶中。使用元数据来记录信息。
Cloud Storage的权限管理方法:
- IAM :bucket level,对桶内所有对象提供相同的权限访问规则
- ACL (access control list):bucket level或者object level
- CMEK:使用KMS生成并管理密钥
- CSEK:用户自己定义和管理密钥
二、Cloud Bigtable
Bigtable是一种高度可扩展的 NoSQL 数据库服务。Bigtable 是一种分布式数据库,适用于存储和处理大量结构化数据,例如时间序列数据、用户分析和财务数据。常见用例包括Gmail和Google maps.
Bigtable的整体架构如下图所示
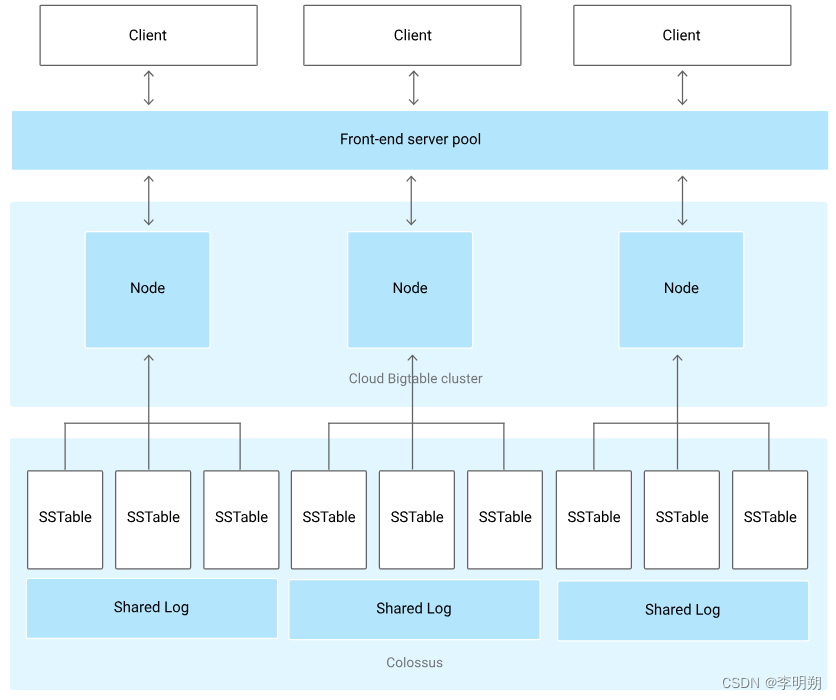
客户端请求都是先经过前端服务器,然后再发送到 Bigtable 节点。集群中的每个节点会处理对该集群的一部分请求。通过向集群添加节点,不但可以增加集群能够同时处理的并发请求数量,而且还会提高集群的吞吐量上限。Bigtable 表被分成多个连续的片,这些片以 SSTable 格式存储在 Google 的文件系统 Colossus 上。
数据永远不会存储到 Bigtable 节点本身,存储到节点上的是数据的元数据,方便进行备份和故障恢复。
Bigtable的权限管理方法:
- IAM :实例级别权限管理
- 用户管理加密密钥(CMEK):在Cloud KMS中控制和管理的密钥来保护您的 Bigtable 实例。
- 防火墙规则:限制对Bigtable实例的访问
Bigtable通过构建Row key(索引)来扫描、查找、排序数据。构建Row Key的方法可以是选择某一列,也可以是将多个列拼接起来。
Bigtable特点:
- 可扩展性:Bigtable 可横向扩展以处理海量数据和高吞吐量工作负载。
- 低延迟:为读写操作提供个位数毫秒延迟,适合实时应用。
- 高可用性:Bigtable 自动跨多个数据中心复制数据,以实现容错和持久性。
Bigtable工具:
- cbt:CBT是专门为Cloud Bigtable设计的命令行工具,为常见操作提供简化的界面
- Hbase Shell:HBase shell 提供了更强大、更灵活的脚本环境,可以通过其兼容层与 Cloud Bigtable 一起使用。
Bigtable性能优化:
- 通过CPU利用率优化节点数目
- 将具有相似模式的数据集存储在同一个表中
- 将相关的列放在同一个列族中。
- 使用序列化结构存储列值
- 使用HDD代替SSD
- 设计合适的schema将读写操作均匀分布到个节点
- 批处理和缓存请求以最小化往返并减少延迟。
- 时序数据使用高/窄的表
- Key Visualizer 会为表生成可视化报告,根据访问的行键详细说明使用情况并解决性能问题。
hotspotting问题:
- field promotion(prefer):从列数据移到row key上
- salting:row key额外添加一个元素
Bigtable的常见使用场景:
- 大量(>1TB)结构化或半结构化数据
- 高吞吐量或者变化迅速的例子,例如欺诈检测或推荐系统。
- 时间序列数据分析,例如 IoT 传感器数据或日志数据。
- 需要进行异步批处理或实时数据处理和分析的金融服务应用程序。
- 以分布式方式处理大规模数据摄取和处理的应用程序。
三、Cloud SQL
Cloud SQL是一种关系型数据湖,支持MySQL, SQL Server和 PostgreSQL。 Cloud SQL实例对应一个虚拟机实例,该虚拟机包含数据库实例和软件容器来保证数据库运行。App Engine 创建使用 Cloud SQL 数据库的应用程序。
Cloud SQL权限管理:通过IAM来控制权限,通过VPC来访问私有IP
Cloud SQL性能优化:
- 根据负载选择恰当的机器类型和存储大小
- 启用自动存储增加
- 通过只读副本处理查询、读取请求和分析流量,从而减少主实例的负载。
Cloud SQL的特点:
- 高可用性:自动故障和转移
- 高扩展性:垂直扩展您的实例以处理增加的工作负载,并通过添加只读副本来水平扩展以提高读取性能。
- 安全性:它提供内置的安全功能,例如静态加密、传输中加密以及与 IAM 集成以实现访问控制。
- 兼容性:Cloud SQL 支持 MySQL、 PostgreSQL 和 SQL Server 等流行的关系数据库引擎,可以轻松迁移现有应用程序。
Cloud SQL的常见使用场景:
- 本地数据库例如MySQL 和PostgreSQL迁移到云端
- 自动复制托管备份
- 需要托管和可扩展的关系数据库后端的 Web 应用程序。
Cloud SQL监控指标:存储利用率、CPU利用率、读写操作等
四、Cloud Spanner
Cloud Spanner 是可水平扩展、全球分布且高度一致的关系数据库服务。 Cloud Spanner 旨在处理跨多个区域的大容量事务性工作负载。
Spanner 的结构
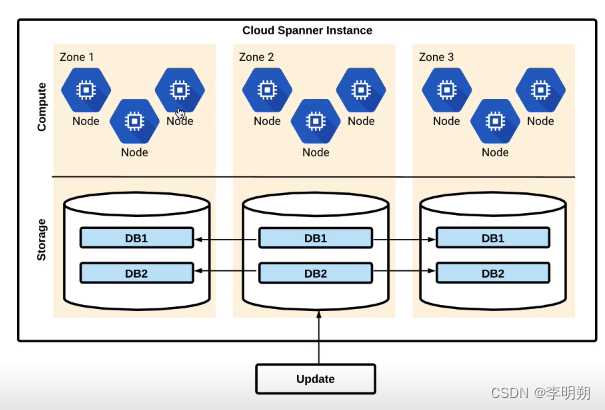
Cloud Spanner的权限控制:
- IAM:项目、实例级别权限
- 细粒度访问控制(fine-grained access control):结合了IAM的优势与传统的基于 SQL 角色的访问控制。 通过细粒度的访问控制,可以控制访问表、列和视图。
- 用户加密密钥(CMEK):在云密钥管理服务 (KMS) 中控制和管理的密钥来保护 Spanner 数据库。
Cloud Spanner的性能优化
- 利用 Cloud Spanner 的自动扩展功能来处理不同的工作负载。
- 使用分布式事务和分区数据来实现高可扩展性和吞吐量。
- 利用读写优化,例如使用索引选择和批处理写入。
- 二级索引:添加二级索引可以更有效地查找该列中的数据,还可以帮助 Spanner 更高效地执行扫描,实现索引扫描而不是全表扫描。
Cloud Spanner的特点:
- 全球可扩展性和一致性:Cloud Spanner 将数据分布在多个区域,在全球范围内提供低延迟访问和强一致性保证。
- 关系模型:它支持 SQL 查询和模式,可以很容易地与现有的应用程序和工具集成。
- 自动扩展:Cloud Spanner 可以根据工作负载需求动态调整其资源,无需人工干预即可实现无缝扩展。
- 自动备份和复制:提供连续备份和复制,确保数据持久性和灾难恢复。
- 强大的安全性:Cloud Spanner 与 IAM 集成以实现访问控制,并提供静态和传输中的加密。
- interleaved tables:交错表是一种用于组织和关联数据的特殊表设计模式。在交错表模式下,父表和子表之间可以形成嵌套关系,子表的行可以"交错"存储在父表的行内。交错表可以减少查询开销,紧密关联数据,分布式事务支持。
Cloud Spanner的使用场景:
- 具有低延迟要求和跨多个区域强一致性需求的全球应用程序。
- 需要高可扩展性和性能的大规模事务性工作负载。
- 数据隔离和安全性至关重要的应用程序。
五、Firestore
Firestore是灵活、可扩展且无服务器的 NoSQL 文档数据库。 它旨在实时跨多个客户端和平台存储和同步数据。 Firestore 提供灵活的数据模型、自动扩展和内置离线功能,使其非常适合构建响应迅速且可扩展的应用程序。
Firestore的权限控制:
- IAM:实例级别权限控制
- Firebase Authentication:对用户进行身份验证和授权。
Firestore的特点:
- 实时数据同步:Firestore 提供跨客户端和平台的无缝实时更新,支持协作和响应式应用程序。
- 可扩展性和自动扩展:它可以自动扩展以处理高读写负载,无需人工干预。
- 离线支持:Firestore 提供内置的离线功能,即使在与网络断开连接的情况下,应用程序也能继续运行。
- 与 Firebase 生态系统集成:Firestore 与身份验证、云功能和云存储等其他 Firebase 服务很好地集成,提供了一个全面的开发平台。
Firestore的性能优化:
- 根据访问模式和查询设计数据结构和文档层次结构。
- 对经常查询的属性使用索引属性以提高查询性能。
- 利用子集合来组织相关数据并避免大型文档。
- 使用批量写入在单个原子事务中执行多个操作。
- 实施高效的数据获取策略,例如使用文档引用或分页。
Firestore的使用场景:
- 离线优先的应用程序需要在连接恢复时离线运行并同步数据。
- 需要跨多个设备进行实时数据同步的移动和 Web 应用程序。
- 涉及多个用户同时更新共享数据的协作应用程序。
- 具有复杂数据模型和层次关系的应用程序。
六、Cloud Datastore
Cloud Datastore是NoSQL文档数据库,它是一种高度可扩展且完全托管的数据库服务,允许以schema-less方式存储和查询结构化数据。 Datastore 提供 ACID 事务、自动可伸缩性和内置复制以实现高可用性。。每个project里只能有一个Datastore。
Datastore的一些使用场景:产品目录、移动APP用户信息、游戏保存状态、ACID。
Datastore和关系型数据库对比:
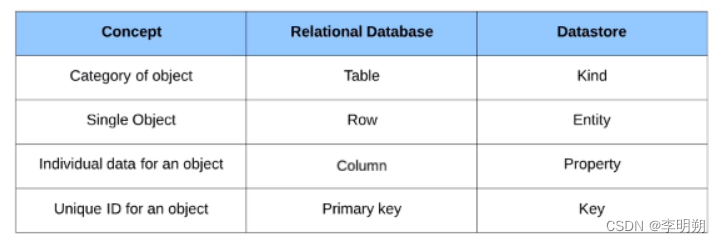
Cloud Datastore的权限控制:
- IAM:实例级别权限控制
- 细粒度控制:使用命名空间来隔离不同的组
Cloud Datastore的特点:
- 可扩展性:Datastore 可自动扩展以处理大量数据和高吞吐量工作负载。
- ACID 事务:它支持具有强一致性保证的多实体组事务。
- 自动复制:Datastore 跨多个数据中心自动复制数据以实现高可用性和持久性。
- 强大的查询功能:Datastore 提供强大的查询语言,支持筛选、排序和投影。
Cloud Datastore的性能优化:
- 根据访问模式仔细设计实体层次结构和实体属性
- 对经常查询的属性使用索引属性以提高查询性能。
- 利用批处理操作减少往返次数并提高写入性能。
- 利用查询游标有效地对大型结果集进行分页。
- 考虑跨多个 Datastore 命名空间对数据进行分片以分配负载。
Cloud Datastore的使用场景:
- 需要可扩展且灵活的数据存储解决方案的 Web 和移动应用程序。
- 实时分析和事件跟踪,其中快速写入和低延迟查询很重要。
- 需要高可用性和自动复制以确保数据持久性的应用程序。
Cloud Datastore的报错分析:
- UNAVALIABLE, DEADLINE_EXCEEDED:指数级别重连
- INTERNAL:尝试不超过一次
- 其他:不要尝试重连
七、安全
1. Data Loss Prevention
2. Stackdriver
Stackdriver用来存储、监控、分析和告警日志数据。
Stackdriver的子产品和其用途包括:
- Stackdriver Debugger:实时检测应用状态而无需停止应用
- Stackdriver Error reporting:收集和分析应用的报错
- Stackdriver Audit Logging:分析日志数据、查看数据权限
- Stackdriver Monitoring:实时监控资源的性能和健康状态
- Stackdriver Trace:分析应用的延迟和性能
3. IAM
IAM包含三种成员类型:
- service account:非人类用户,例如应用
- google account:对于单个用户
- google group:对于多个用户
八、网络概述
Google Cloud Platform (GCP) 提供强大且可扩展的网络基础设施来支持各种云服务和应用程序。 GCP 网络旨在提供高性能、安全性和可靠性。 以下是 GCP 网络的关键组件和功能的概述:
- 虚拟私有云 (VPC):VPC 是 GCP 内逻辑隔离的全球网络,允许您创建和管理虚拟机实例、容器和其他资源。 每个VPC都与一个IP地址范围相关联,并且可以进一步划分为子网。
- 子网:子网是 VPC 的细分,使您能够隔离网络资源。 您可以指定子网的 IP 地址范围并使用防火墙规则控制子网之间的流量。
- 防火墙规则:GCP 提供网络级防火墙规则,允许您控制进出资源的入站和出站流量。 防火墙规则可以在 VPC 级别或子网级别定义,并且可以基于 IP 地址、协议和端口。
- 负载均衡:GCP 提供多种负载均衡选项来跨资源分配流量。 其中包括 HTTP(S) 负载平衡、SSL 代理负载平衡、TCP 代理负载平衡和网络负载平衡。 负载均衡器自动扩展和分配流量,以确保高可用性和性能。
- Cloud Router:Cloud Router 是一项完全托管的服务,可在您的 VPC 网络内以及 VPC 网络与本地网络之间提供动态路由。 它同时支持 BGP(边界网关协议)和静态路由。
- Cloud VPN:Cloud VPN 使您能够在 VPC 网络与本地或其他外部网络之间建立加密的 IPsec 隧道。 它为远程办公室、数据中心和其他网络资源提供安全连接,更适用于低速传输。
- 云互连(Cloud Interconnect):云互连在本地网络和 GCP 之间提供专用且低延迟的连接。 与 VPN 相比,它提供更高的带宽和更可靠的连接。 云互连支持专用互连和合作伙伴互连等选项。
- 合作伙伴互连(Partner Interconnect):合作伙伴互连允许您使用受支持的服务提供商连接到 GCP。 它使您能够通过合作伙伴的网络在本地网络和 GCP 网络边缘之间建立直接物理连接。 与 VPN 连接相比,此连接提供更高的带宽和更低的延迟。
- 专用互连(Dedicated Interconnect):专用互连允许您在本地网络和 GCP 网络边缘之间建立直接物理连接。 通过专用互连,您可以拥有专用于您的组织的私人连接。 此选项适合大规模工作负载或当您需要对网络连接进行更多控制时。
- Cloud DNS:Cloud DNS 是 GCP 提供的可扩展且可靠的域名系统 (DNS) 服务。 它允许您管理域名并将其解析为相应的 IP 地址。
- 全局负载均衡:GCP 的全局负载均衡 (GLB) 跨多个区域分配传入流量,以确保高可用性并最大限度地减少延迟。 它会自动将用户定向到最近且资源状况良好的可用区域。
- Cloud CDN:Cloud CDN(内容分发网络)是一种分布式边缘缓存服务,可以缓存内容并将内容分发到更接近最终用户的位置。 它通过减少延迟和卸载源服务器的流量来帮助提高性能。