为Claude的分析内容做准备:提取PDF页面内容的简易应用程序
由于Claude虽然可以分析整个文件,但是对文件的大小以及字数是有限制的,为了将pdf文件分批传入Claude人工智能分析和总结文章内容,才有了这篇博客:
在本篇博客中,我们将介绍一个基于 wxPython 和 PyMuPDF 库编写的简易的 PDF 页面内容提取应用程序。该应用程序允许用户选择一个 PDF 文件,并指定起始页和结束页,然后提取这些页面之间的文本内容并显示在应用程序窗口中。
C:pythoncodenewpdfbeginendcontent.py
环境配置
在开始之前,请确保已经安装了以下两个库:
- wxPython:用于创建 GUI 窗口和交互界面。
- PyMuPDF:用于解析和提取 PDF 文件的内容。
你可以使用以下命令来安装这两个库:
pip install wxPython PyMuPDF
代码实现
下面是完整的 Python 代码实现:
import wx
import fitz
import wx.lib.masked as masked
class MyFrame(wx.Frame):
def __init__(self):
super().__init__(None, title="提取PDF页面内容", size=(400, 300))
panel = wx.Panel(self)
vbox = wx.BoxSizer(wx.VERTICAL)
select_button = wx.Button(panel, label="选择PDF文件")
select_button.Bind(wx.EVT_BUTTON, self.on_select_pdf)
vbox.Add(select_button, proportion=0, flag=wx.ALIGN_CENTER | wx.ALL, border=10)
page_label = wx.StaticText(panel, label="开始页码:")
vbox.Add(page_label, proportion=0, flag=wx.LEFT, border=10)
self.start_page_input = wx.TextCtrl(panel)
vbox.Add(self.start_page_input, proportion=0, flag=wx.EXPAND | wx.ALL, border=10)
page_label2 = wx.StaticText(panel, label="结束页码:")
vbox.Add(page_label2, proportion=0, flag=wx.LEFT, border=10)
self.end_page_input = wx.TextCtrl(panel)
vbox.Add(self.end_page_input, proportion=0, flag=wx.EXPAND | wx.ALL, border=10)
extract_button = wx.Button(panel, label="提取内容")
extract_button.Bind(wx.EVT_BUTTON, self.on_extract_content)
vbox.Add(extract_button, proportion=0, flag=wx.ALIGN_CENTER | wx.ALL, border=10)
content_label = wx.StaticText(panel, label="内容:")
vbox.Add(content_label, proportion=0, flag=wx.LEFT, border=10)
self.content_text = wx.TextCtrl(panel, style=wx.TE_MULTILINE | wx.TE_READONLY)
vbox.Add(self.content_text, proportion=1, flag=wx.EXPAND | wx.ALL, border=10)
panel.SetSizer(vbox)
def on_select_pdf(self, event):
dialog = wx.FileDialog(self, message="选择PDF文件", wildcard="PDF files (*.pdf)|*.pdf", style=wx.FD_OPEN)
if dialog.ShowModal() == wx.ID_OK:
self.pdf_path = dialog.GetPath()
dialog.Destroy()
def on_extract_content(self, event):
doc = fitz.open(self.pdf_path)
start_page = int(self.start_page_input.GetValue())
end_page = int(self.end_page_input.GetValue())
if start_page < 1 or end_page > doc.page_count:
wx.MessageBox("无效的页码!", "错误", wx.OK | wx.ICON_ERROR)
return
# for page_num in range(start_page - 1, end_page):
# page = doc.load_page(page_num)
# text = page.get_text()
# self.content_text.SetValue(text)
content = "" # 定义一个空字符串用于存储拼接的内容
for page_num in range(start_page - 1, end_page):
page = doc.load_page(page_num)
text = page.get_text()
content += text # 将获取的文本添加到content中
self.content_text.SetValue(content) # 设置content_text的值为拼接后的字符串
doc.close()
if __name__ == '__main__':
app = wx.App()
frame = MyFrame()
frame.Show()
app.MainLoop()
运行应用程序
保存以上代码为 pdf_extractor.py 文件,然后在终端中运行以下命令启动应用程序:
python pdf_extractor.py
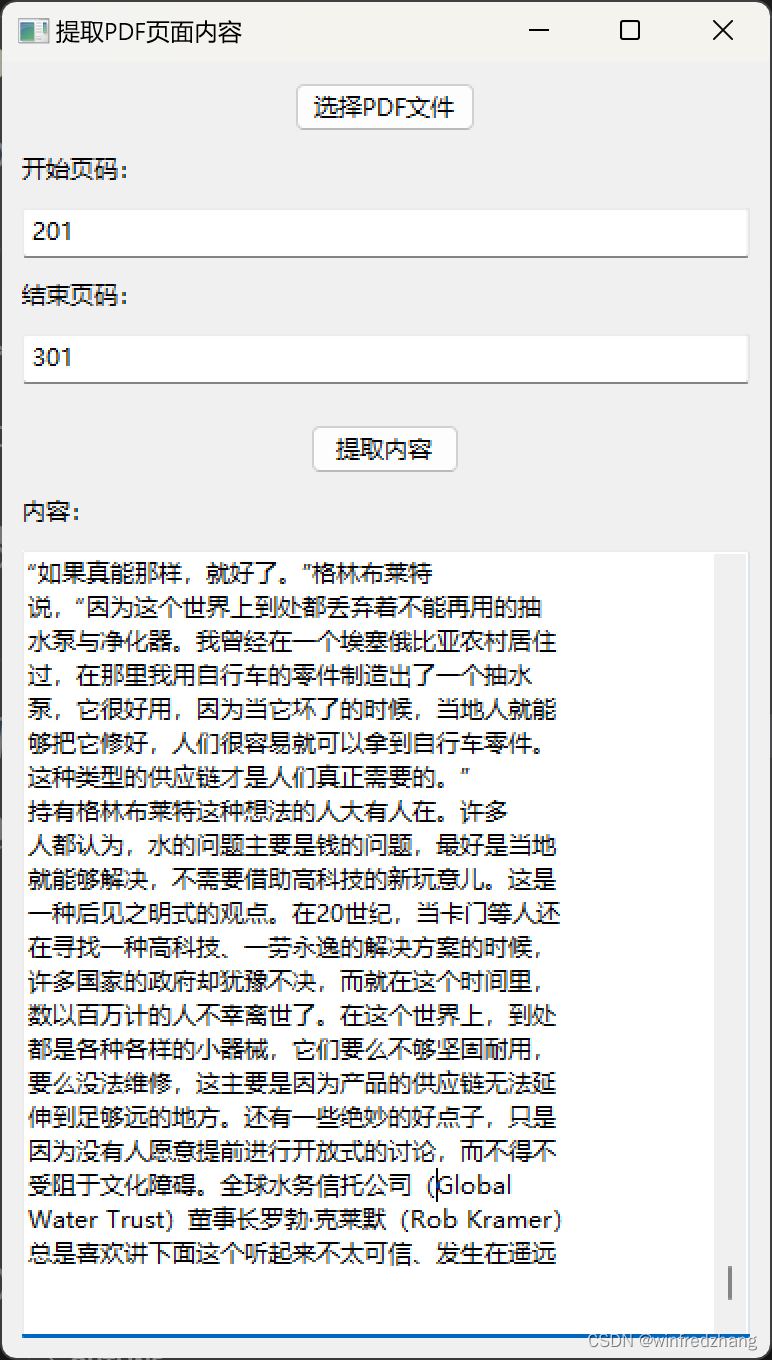
应用程序窗口将显示出来,你可以点击 “选择PDF文件” 按钮选择一个 PDF 文件,然后在起始页码和结束页码输入框中输入相应的页码,最后点击 “提取内容” 按钮,应用程序将提取选定页面范围内的文本内容,并将其显示在文本框中。
总结
本篇博客介绍了一个使用 wxPython 和 PyMuPDF 库编写的简易的 PDF 页面内容提取应用程序。通过该应用程序,用户可以方便地选择一个 PDF 文件,并指定起始页和结束页,提取这些页面之间的文本内容,并在应用程序窗口中显示。