【Python自然语言处理+tkinter图形化界面】实现智能医疗客服问答机器人实战(附源码、数据集、演示 超详细)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~
一、问答智能客服简介
QA问答是Question-and-Answer的缩写,根据用户提出的问题检索答案,并用用户可以理解的自然语言回答用户,问答型客服注重一问一答处理,侧重知识的推理。
从应用领域视角,可将问答系统分为限定域问答系统和开放域问答系统。
根据支持问答系统产生答案的文档库、知识库,以及实现的技术分类,可分为自然语言的数据库问答系统、对话式问答系统、阅读理解系统、基于常用问题集的问答系统、基于知识库的问答系统等。
智能问答客服功能架构
典型的问答系统包含问题输入 问题理解 信息检索 信息抽取 答案排序 答案生成和结果输出等,首先由用户提出问题,检索操作通过在知识库中查询得到相关信息,并依据特定规则从提取到的信息中抽取相应的候选答案特征向量,最后筛选候选答案结果输出给用户
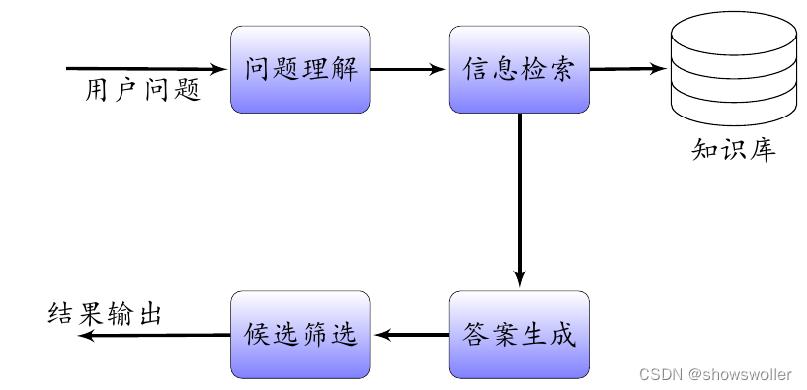
智能问答客服框架
1: 问题处理 问题处理流程识别问题中包含的信息,判断问题的主题信息和主题范畴归属,比如是属于一般类问题还是属于特定主题类问题,然后提取与主题相关的关键信息,比如人物信息、地点信息和时间信息等。
2 :问题映射 根据用户咨询的问题,进行问题映射消除歧义。通过字符串相似度匹配和同义词表等解决映射问题,根据需要执行拆分和合并操作。
3 :查询构建 通过对输入问题进行处理,将问题转化为计算机可以理解的查询语言,然后查询知识图谱或者数据库,通过检索获得相应备选答案。
4 :知识推理 根据问题属性进行推理,问题基本属性如果属于知识图谱或者数据库中的已知定义信息,则可以从知识图谱或者数据库中查找,直接返回答案。如果问题属性是未定义类问题,则需要通过机器算法推理生成答案。
5: 消岐排序 根据知识图谱中查询返回的一个或者多个备选答案,结合问题属性进行消歧处理和优先级排序,输出最佳答案。
二、智能医疗客服问答实战
定制性智能客服程序一般需要实现选择语料库,去除噪声信息后 根据算法对预料进行训练,最后提供人机接口问答对话,基于互联网获得的医学语料库,并通过余弦相似度基本原理,设计并开发以下问答型智能医疗客服应用程序
项目结构如下
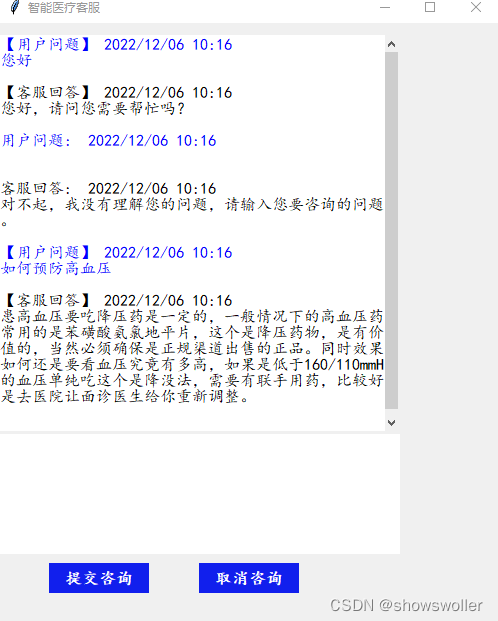
效果展示
下面是csv文件中定义的一些病例

预先定义好的欢迎语句


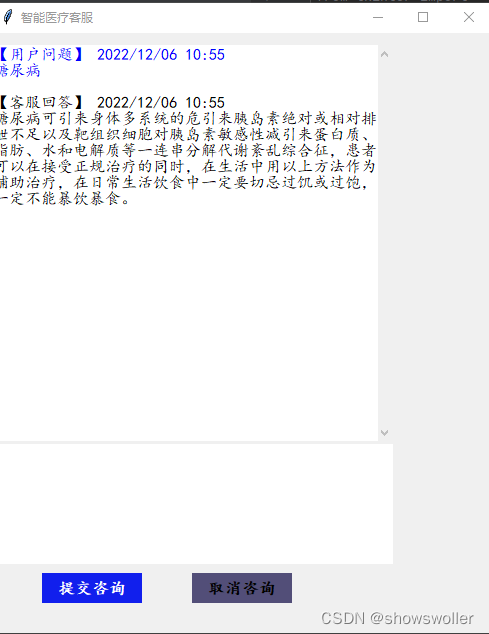
运行chatrobot文件 弹出以下窗口 输出问题后点击提交咨询即可
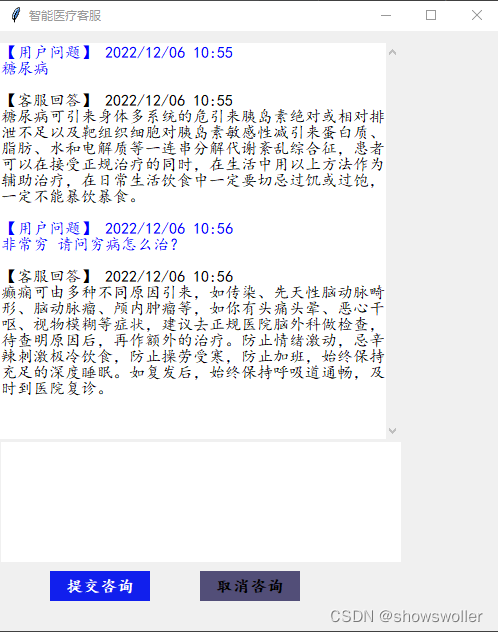
对于语料库中没有的问题会自动推断给出答案(通常不太准确)
三、代码
部分代码如下 全部代码和数据集请点赞关注收藏后评论区留言私信
# -*- coding:utf-8 -*-
from fuzzywuzzy import fuzz
import sys
import jieba
import csv
import pickle
print(sys.getdefaultencoding())
import logging
from fuzzywuzzy import fuzz
import math
from scipy import sparse
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from scipy.sparse import lil_matrix
from sklearn.naive_bayes import MultinomialNB
import warnings
from tkinter import *
import time
import difflib
from collections import Counter
import numpy as np
filename = 'label.csv'
def tokenization(filename):
corpus = []
label = []
question = []
answer = []
with open(filename, 'r', encoding="utf-8") as f:
data_corpus = csv.reader(f)
next(data_corpus)
for words in data_corpus:
word = jieba.cut(words[1])
tmp = ''
for x in word:
tmp += x
corpus.append(tmp)
question.append(words[1])
label.append(words[0])
answer.append(words[2])
with open('corpus.h5','wb') as f:
pickle.dump(corpus,f)
with open('label.h5','wb') as f:
pickle.dump(label,f)
with open('question.h5', 'wb') as f:
pickle.dump(question, f)
with open('answer.h5', 'wb') as f:
pickle.dump(answer, f)
return corpus,label,question,answer
def train_model():
with open('corpus.h5','rb') as f_corpus:
corpus = pickle.load(f_corpus)
with open('label.h5','rb') as f_label:
label = pickle.load(f_label,encoding='bytes')
vectorizer = CountVectorizer(min_df=1)
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
words_frequency = vectorizer.fit_transform(corpus)
word = vectorizer.get_feature_names()
saved = tfidf_calculate(vectorizer.vocabulary_,sparse.csc_matrix(words_frequency),len(corpus))
model = MultinomialNB()
model.fit(tfidf,label)
with open('model.h5','wb') as f_model:
pickle.dump(model,f_model)
with open('idf.h5','wb') as f_idf:
pickle.dump(saved,f_idf)
return model,tfidf,label
class tfidf_calculate(object):
def __init__(self,feature_index,frequency,docs):
self.feature_index = feature_index
self.frequency = frequency
self.docs = docs
self.len = len(feature_index)
def key_count(self,input_words):
keys = jieba.cut(input_words)
count = {}
for key in keys:
num = count.get(key, 0)
count[key] = num + 1
return count
def getTfidf(self,input_words):
count = self.key_count(input_words)
result = lil_matrix((1, self.len))
frequency = sparse.csc_matrix(self.frequency)
for x in count:
word = self.feature_index.get(x)
if word != None and word>=0:
word_frequency = frequency.getcol(word)
feature_docs = word_frequency.sum()
tfidf = count.get(x) * (math.log((self.docs+1) / (feature_docs+1))+1)
result[0, word] = tfidf
return result
if __name__=="__main__":
tokenization(filename)
train_model()
创作不易 觉得有帮助请点赞关注收藏~~~