Vortex: 一种基于RISC-V指令集自定义扩展的开源GPGPU架构
目录
2.1.1 Wavefront Control(波阵面控制): wspawn
2.1.2 Thread Control(线程控制): tmc
2.1.3 Control Divergence(控制发散): split / join
2.1.4 Synchronization(同步性):bar
2.1.5 Texture Filtering(纹理滤波):tex
2.2.2 Threads Masks and IPDOM Stack
1. 背景知识
1.1 RISC-V设计核心:RISC-V指令集ISA
1.1.1 精简指令集
基本的RISC-V(Reduced Instruction Set Computer)指令数目仅有47条(RV32I)
指令是处理器进行操作的最小单元(譬如加减乘除、读写寄存器数据),指令集就是一组指令的集合。有了指令集架构(ISA,Instruction Set Architecture),就可以使用不同的处理器硬件实现方案来实现不同性能的处理器。为了让软件程序员能够编写底层的软件,指令集架构不仅仅是一组指令的集合,它还要定义任何软件程序员需要了解的硬件信息,包括支持的数据类型、存储器、寄存器状态、寻址模式和存储器模型等。
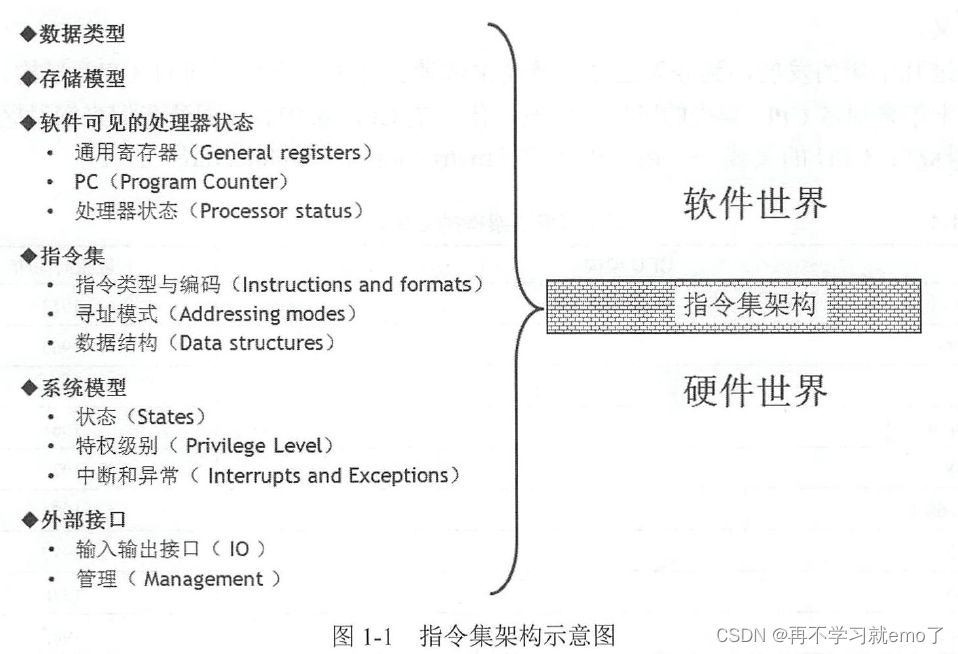
目前主流架构(譬如x86)是CISC(Complex Instruction Set Computer),极为复杂和冗杂,且不开源,专利授权费昂贵。
RISC-V 架构的目标:
• 成为一种完全开放的指令集,可以被任何学术机构或商业组织所自由使用。
• 成为一种真正适合硬件实现且稳定的标准指令集。
1.1.2 模块化指令集
RISC-V指令集使用模块化的方式进行组织,每一个模块使用一个英文字母来表示,除了I指令集是设计架构时强制要求实现的指令集,其他指令集均可供客户选择。
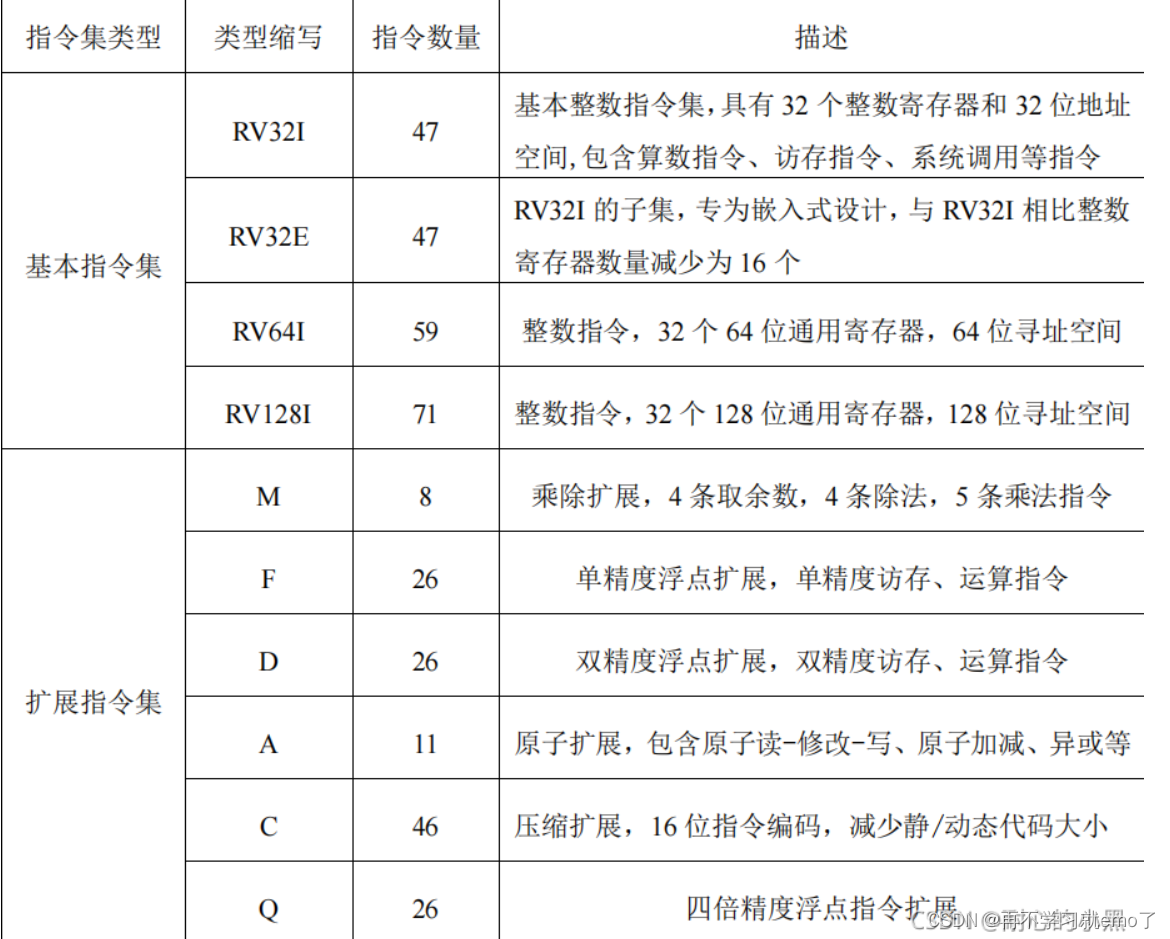
对比x86,光加减法就有很多条指令,但在RISC-V里面只有ADD,SUB,ADDI
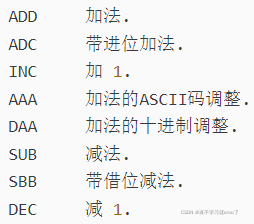
1.2 用户自定义指令集扩展
除了上述模块化指令子集可供客户扩展和选择(这一部分指令的功能和编码是官方定义好的,用户只需要选择要不要设计到架构里),RISC-V预留了大量指令编码空间以支持第三方扩展(自己编码自己定义功能)。目前的自定义扩展基于R-type指令。
(RISC-V稳定性体现之处:规整的指令编码—指令所需的通用寄存器的索引都放在固定的位置)
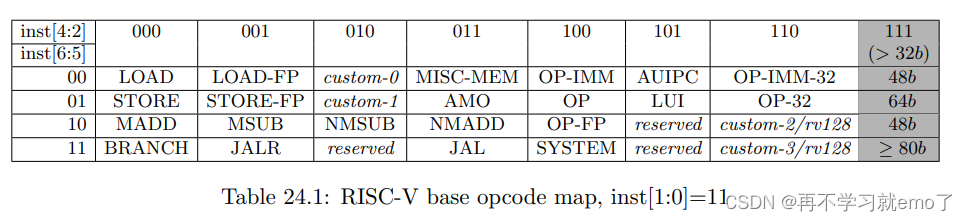

-指令的第0到6位为Opcode编码段,根据Opcode表规则,inst[1:0]=11,inst[6:2]=00010对应custom0指令组
-inst[31:25]为funct7区间,可作为额外的编码空间,因此一组custom指令组可以编码出128条指令
-xd、xs1、xs2是三个寄存器掩码,为分别代表是否读写rd、rs1、rs2寄存器
1.3 GPU层次结构
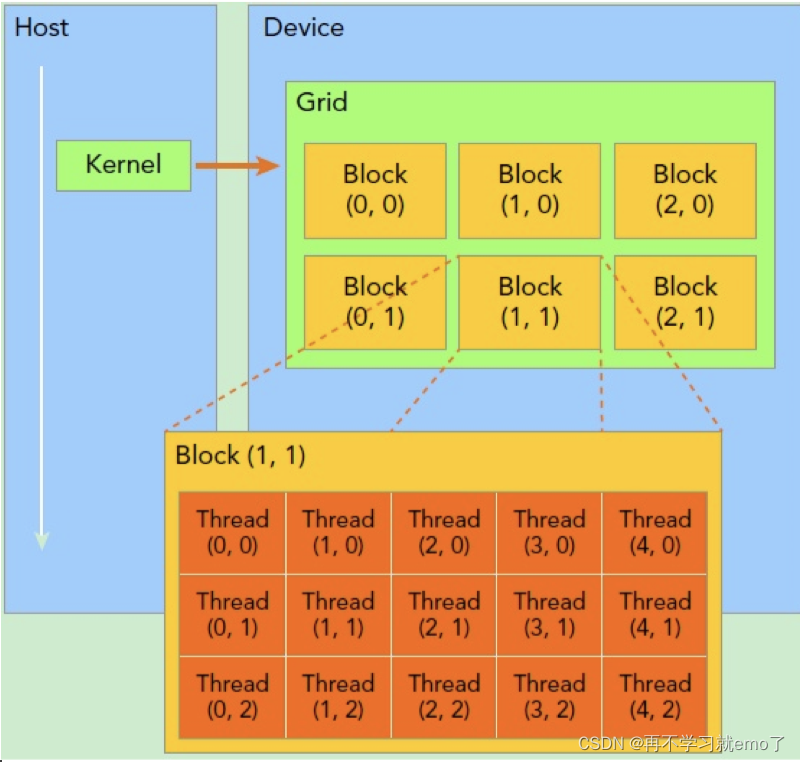
sp(streaming processor) : 最基本的处理单元,最后具体的指令和任务都是在sp上处理的。GPU进行并行计算,也就是很多个sp同时做处理。
sm(streaming multiprocessor):多个sp加上其他的一些资源组成一个sm。
warp:GPU执行程序时的调度单位,目前cuda一个warp有32个thread,同在一个warp的线程,以不同数据资源执行相同的指令。
grid、block、thread:在利用cuda进行编程时,一个grid分为多个block,而一个block分为多个thread.其中任务划分到是否影响最后的执行效果。划分的依据是任务特性和GPU本身的硬件特性。
一个sm只会执行一个block里的warp,当该block里warp执行完才会执行其他block里的warp。进行划分时,最好保证每个block里的warp比较合理,那样可以一个sm可以交替执行里面的warp,从而提高效率,此外,在分配block时,要根据GPU的sm个数,分配出合理的block数,让GPU的sm都利用起来,提利用率。分配时,也要考虑到同一个线程block的资源问题,不要出现对应的资源不够。
2. Vortex RISC-V GPGPU System
2.1 设计核心:扩展了一个自定义R指令集

2.1.1 Wavefront Control(波阵面控制): wspawn
![]()
在指定PC值到来时,启动%numW个wavefront,标志是这些wavefronts的tread0被激活。同时上一个正在进行的warp对应的src寄存器里的值会被复制到新warp对应的dst寄存器里。
我理解这里的wavefront就是其他论文里的warp,一个warp里包含32个tread
2.1.2 Thread Control(线程控制): tmc

对于每一个wavefront里的tread,有一个32位的CSR(Control and Status register状态控制寄存器),称为tread mask register,每一位代表对应tread的状态(字节掩码),1代表被激活,0代表未被激活。
tmc:%NumTread个tread会被激活(例如等于5时,tread0-4的字节掩码会被置1)
2.1.3 Control Divergence(控制发散): split / join
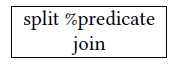
当同一个warp里的tread进入不同的跳转分支时,会出现控制发散现象(control divergence)
Divergence 是Warp中的一个概念,在同一个warp中有的线程走这个分支,有的线程走另外一个分支,称之为divergence。
一个Warp中的所有Thread执行同一指令。但是,由于不同Thread的数据不同,如果有基于数据的判断,就可能产生不同的结果。这时,就会产生多路径问题即发散,意味着Thread需要执行不同的指令。sm处理的方式是多次执行,每次沿着一条路径,直到所有路径都执行完毕。所以,控制发散直接关系到程序的性能。
Vortex对此的解决方式是加入了一个IPDOM Stack(下文会详细说)
当split指令来临时,代表要出现分支了,%predicate储存了预测将要执行的指令的信息。
当join指令来临时,代表要跳回出现split指令时的那个pc值继续运行。
2.1.4 Synchronization(同步性):bar
![]()
同步某一组wavefronts。可能这些wavefronts都在执行同一个操作,但是速度有快有慢。为了让这些wavefronts在某一个节点能同步,让执行快的wavefront等一等慢的,就会设置一个屏障快的wavefront,等到预设的%numW个wavefronts都达到这个屏障了,同步完成,就可以移除这个屏障,让它们进行下一步操作。
2.1.5 Texture Filtering(纹理滤波):tex
![]()
该指令用于纹理信息的查找。它有三个源操作数,即u、v、lod,用于查找源texel和纹理mipmap的规范化坐标。其他纹理状态(维度、格式、过滤模式、寻址模式和内存地址)可以通过csr进行配置。
2.2 Vortex GPGPU结构:32bit 五级流水
现有gpgpu架构的普遍特点:
规划了线程如何调度、如何同步以及如何分配内存层次结构
基础结构:取指—译码—执行—存储—写回
特征结构:在五级流水基础上新增模块:更合理高效地利用所有线程,提高计算速度
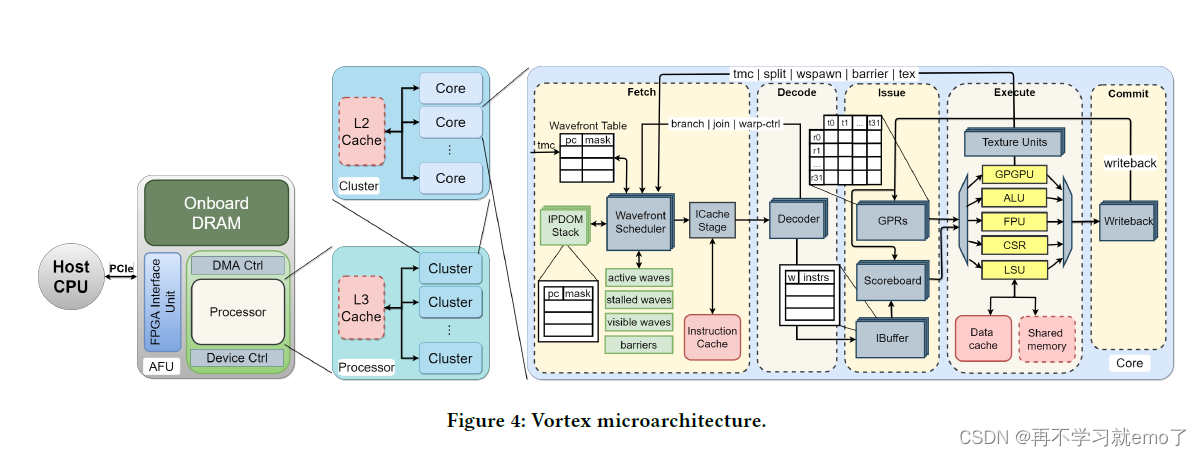
2.2.1 Wavefront Scheduler
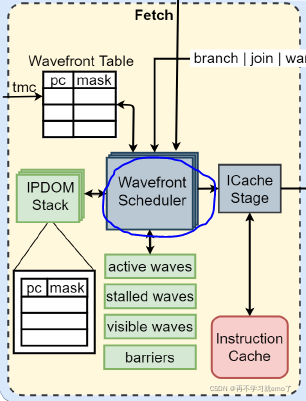
两个组成部分:
(1)wavefront masks: 调用哪个wavefront
(2)wavefront table: 储存每个wavefront的信息
四个线程掩码:
(1)active wavefront mask: 每个bit指出对应wavefront的状态
(2)stalled wavefront mask: 指出哪些wavefronts不能够被临时调用
(3)visible wavefront mask: 支持分层调度
(4)barrier mask: 每一个wavefront都有一个掩码,指示是否在等待bariier来同步
2.2.2 Threads Masks and IPDOM Stack
当分支指令来临时,会进行分支预测,每个线程会有两个预测结果(跳转或者不跳转)。线程会先根据预测true的结果执行,但是会将现在的thread mask和预测flase后下一个指令的thread mask和pc值存储在IPDOM中。当join指令来临时,会有两种情况(1)当前分支完成了,重新回到前面跳转的地方继续运算 (2) 分支预测结果错误,即应该是走false的分支但走了true,于是需要重新走false再执行一次
这样的设计可以减少流水线冲刷,节省计算时间
2.2.3 Wavefront Barriers
用来支持不同wavefront之间的同步。包括
(1) 计数器,统计还有多少个wavefront没有到达barrier,当计数器为0时,该barrier被释放,被同步的这些wavefront开始同时继续执行
(2) barrier mask(应该和wavefront scheduler里的barrier mask是一个东西)
2.2.4 Memory System
除了常规的data cache和instruction cache,增加了一个shared memory,可根据需求作为高速缓存或者堆栈。
不同的core可以聚合成一个集群与L2 cache进行读写,不同集群可以组合成一个处理器与L3 cache进行读写,分层读写可以大大提高存储效率。
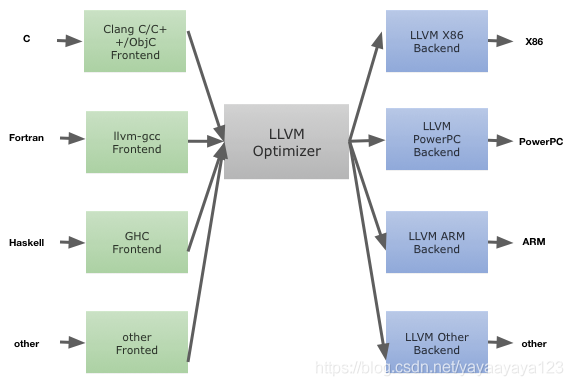
2.3 编译环境: LLVM编译器
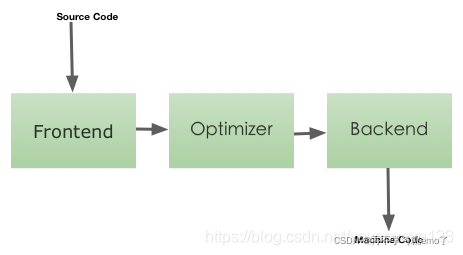
2.3.1 传统编译器(例如gcc)
前端(Frontend)-- 优化器(Optimizer)-- 后端(Backend)
前端负责分析源代码,可以检查语法级错误,并构建针对语言的抽象语法树(AST);抽象语法树可以进一步转换为优化,最终转为新的表示方式,然后再交给让优化器和后端处理;最终由后端生成可执行的机器码。
缺点:三个阶段冗杂在一起,不能独立,牵一发而动全身。如有N种语言(C、OC、C++、Swift...)的前端,同时也有M个架构(模拟器、arm64、x86...)的target,就需要N*M个编译器。
2.3.2 LLVM编译器
LLVM拥有各个阶段都很独立的三段式结构, LLVM不同的就是它的中间表示IR(intermediate representation)编写良好,对于不同的语言它都提供了同一种中间表示,即我们在前端新增一种语言,或者在后端新增一种类似RISC-V的硬件架构,我只需要对IR部分进行优化,但不用重新设计编译器。