NLP(六十三)使用Baichuan-7b模型微调人物关系分类任务
任务介绍
人物关系分类指的是对文本中的两个人物,在特定的关系列表中,判断他们之间的人物关系。以样本亲戚 1837年6月20日,威廉四世辞世,他的侄女维多利亚即位。为例,其中亲戚为人物关系,威廉四世为实体1,维多利亚为实体2。
笔者自己利用业余时间标注的样本数据有3881条,分布如下图:
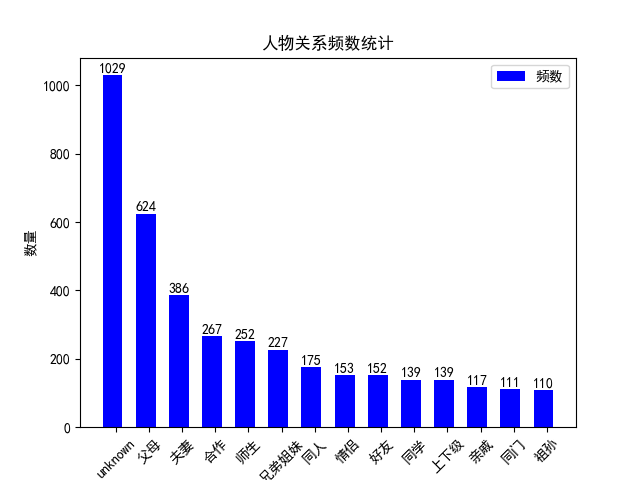
对上述数据集进行划分,训练集与测试集的比例为8:2,其中训练集3105条,测试集776条。
在文章NLP(二十一)人物关系抽取的一次实战中,当时的标注数据为2900多条,使用BERT向量提取+BiGRU+Attention模型,取得的平均F1值为78.97%.
在文章NLP(四十二)人物关系分类的再次尝试中,借助BERT微调(当作分类任务),取得的平均F1值为82.69%.
在文章NLP(四十五)R-BERT在人物关系分类上的尝试及Keras代码复现中,借助专用于关系分类任务的R-BERT模型,在Chinese Roberta模型上取得的F1值为85.35%.
在本文中,将尝试使用大模型(Large Language Model, LLM)中的中文模型代表Baichuan-7b, 对人物关系分类任务进行微调,看看它的表现。
好的提示
在开始模型微调之前,我们需要一个好的提示(Prompt),我们借助GPT-4:

别小看了Prompt的威力,笔者在使用微调模型过程中,发现自己写的Prompt与GPT-4给出的Prompt,在训练结果F1值上可能相差3-4%。可见Prompt工程的重要性!
模型微调
我们使用上述Prompt,加工数据集(当作多轮对话任务),格式如下:
{
"conversation_id": 1,
"category": "relation classification",
"conversation": [
{
"human": "给定以下标签:['不确定', '夫妻', '父母', '兄弟姐妹', '上下级', '师生', '好友', '同学', '合作', '同一个人', '情侣', '祖孙', '同门', '亲戚'],请在以下句子中分析并分类实体之间的关系:'与李源澄论戴东原书'在这个句子中,戴东原和李源澄之间的关系应该属于哪个标签?",
"assistant": "不知道"
}
]
}
使用Firefly框架进行模型微调,访问网址为:https://github.com/yangjianxin1/Firefly.本文基于Baichuan-7b为基座模型,采用QLora方式训练,训练参数如下:
{
"output_dir": "output/firefly-baichuan-7b-people",
"model_name_or_path": "/home/test/baichun_7b",
"train_file": "./data/train.jsonl",
"num_train_epochs": 5,
"per_device_train_batch_size": 8,
"gradient_accumulation_steps": 2,
"learning_rate": 2e-4,
"max_seq_length": 256,
"logging_steps": 100,
"save_steps": 100,
"save_total_limit": 1,
"lr_scheduler_type": "constant_with_warmup",
"warmup_steps": 100,
"lora_rank": 64,
"lora_alpha": 16,
"lora_dropout": 0.05,
"gradient_checkpointing": true,
"disable_tqdm": false,
"optim": "paged_adamw_32bit",
"seed": 42,
"fp16": true,
"report_to": "tensorboard",
"dataloader_num_workers": 0,
"save_strategy": "steps",
"weight_decay": 0,
"max_grad_norm": 0.3,
"remove_unused_columns": false
}
使用命令行torchrun --nproc_per_node=2 train_qlora.py --train_args_file train_args/qlora/baichuan-7b-sft-qlora.json进行训练,训练时间大约20分钟,最终的train loss为0.0273。
在Firefly框架中设置好merge_lora.py中的模型文件路径,将adapter的权重与Baichuan-7b模型合并,合并得到新文件firefly-baichuan-7b-people-merge。
在Firefly框架,仿造script/chat/single_chat.py文件,将其改写成API调用方式的文件single_chat_server.py,代码如下:
# -*- coding: utf-8 -*-
# @place: Pudong, Shanghai
# @file: single_chat_server.py
# @time: 2023/7/25 22:27
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 单轮对话web服务
from flask import Flask, request, jsonify
app = Flask("single_chat_server")
@app.route('/people_rel_cls', methods=['POST'])
def predict():
req_dict = request.json
text, people1, people2 = req_dict["text"], req_dict["people1"], req_dict["people2"]
text = text.strip()
content = f"给定以下标签:['不确定', '夫妻', '父母', '兄弟姐妹', '上下级', '师生', '好友', '同学', "
f"'合作', '同一个人', '情侣', '祖孙', '同门', '亲戚'],"
f"请在以下句子中分析并分类实体之间的关系:'{text}'"
f"在这个句子中,{people1}和{people2}之间的关系应该属于哪个标签?"
print(content)
input_ids = tokenizer(content, return_tensors="pt", add_special_tokens=False).input_ids.to(device)
with torch.no_grad():
outputs = model.generate(
input_ids=input_ids, max_new_tokens=max_new_tokens, do_sample=True,
top_p=top_p, temperature=temperature, repetition_penalty=repetition_penalty,
eos_token_id=tokenizer.eos_token_id
)
outputs = outputs.tolist()[0][len(input_ids[0]):]
response = tokenizer.decode(outputs)
print(outputs, response)
response = response.strip().replace(text, "").replace('</s>', "").replace('<s>', "").strip()
return jsonify({"result": response})
if __name__ == '__main__':
model_name = "/home/test/Firefly/script/checkpoint/firefly-baichuan-7b-people-merge"
max_new_tokens = 5
top_p = 0.9
temperature = 0.01
repetition_penalty = 1.0
device = 'cuda:0'
input_pattern = '<s>{}</s>'
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
).to(device).eval()
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True,
# llama不支持fast
use_fast=False if model.config.model_type == 'llama' else True
)
print("model loaded!")
app.run(host="0.0.0.0", port=5000, threaded=True)
使用API调用方式可以对测试集进行模型评估。
结果比对
不同模型(包括BERT时代前后的模型方法)的评估结果(均为当时模型的SOTA结果或接近SOTA结果)如下:
| 模型方法 | 基座模型 | F1值 | 说明 |
|---|---|---|---|
| BERT向量提取+BiGRU+Attention | BiGRU+Attention | 78.97% | BERT模型作为特征提取处理 |
| BERT cls finetuning | BERT | 82.69% | 当作文本分类任务处理 |
| R-BERT | chinese-roberta-wwm-ext | 85.35% | BERT时代的关系分类模型代表 |
| R-BERT | chinese-roberta-wwm-ext-large | 87.22% | BERT时代的关系分类模型代表 |
| QLora | Baichuan-7b | 88.25% | 其它参数上文给出,epoch=5 |
| QLora | Baichuan-7b | 89.15% | 其它参数上文给出,epoch=10 |
存在问题
在大模型时代中,大模型突破了以前NLP任务的范畴,走向了更加通用化,从上述结果中,我们也不难发现,大模型(Baichuan-7b)在传统的NLP任务(如笔者自己的人物关系数据集)上取得了更好的结果,达到了新的SOTA,这是符合我们的认知的。
但在笔者模型微调过程中,也发现了不少的问题或有待于进一步验证的地方,记录如下:
- Baichuan-7b模型取得了SOTA结果,但同样的训练框架和训练参数,Baichuan-13B-Base模型却表现惨淡,甚至很差
- 不同的Prompt对于训练结果的影响,比如笔者自己写的Prompt和GPT-4写的Prompt对于最终结果差距较大,相差3-4%
- 相同的模型,采用full, lora, qlora三种形式进行SFT,训练结果会有何不同
后续笔者将尝试使用不同的训练框架进行Baichuan-13B-Base的微调。
总结分享
本文主要介绍如何使用Baichuan-7b模型微调人物关系分类任务,并比BERT时代的模型取得了进步,达到了新的SOTA.
本文的想法很朴素,主要是想测试下LLM在传统NLP人物上的表现,也是对于笔者自己的人物关系数据集的一次效果提升,这也是笔者一直在关注和构建的数据集。这一次,大模型再一次让我震惊!
本文使用的人物关系数据集已开源至HuggingFace Datasets, 网址为: https://huggingface.co/datasets/jclian91/people_relation_classification .
本人的个人博客网址为:https://percent4.github.io/ ,欢迎大家关注~
参考文献
- NLP(二十一)人物关系抽取的一次实战: https://percent4.github.io/2023/07/08/NLP%EF%BC%88%E4%BA%8C%E5%8D%81%E4%B8%80%EF%BC%89%E4%BA%BA%E7%89%A9%E5%85%B3%E7%B3%BB%E6%8A%BD%E5%8F%96%E7%9A%84%E4%B8%80%E6%AC%A1%E5%AE%9E%E6%88%98/
- NLP(四十二)人物关系分类的再次尝试: https://percent4.github.io/2023/07/10/NLP%EF%BC%88%E5%9B%9B%E5%8D%81%E4%BA%8C%EF%BC%89%E4%BA%BA%E7%89%A9%E5%85%B3%E7%B3%BB%E5%88%86%E7%B1%BB%E7%9A%84%E5%86%8D%E6%AC%A1%E5%B0%9D%E8%AF%95/
- NLP(四十五)R-BERT在人物关系分类上的尝试及Keras代码复现: https://percent4.github.io/2023/07/10/NLP%EF%BC%88%E5%9B%9B%E5%8D%81%E4%BA%94%EF%BC%89R-BERT%E5%9C%A8%E4%BA%BA%E7%89%A9%E5%85%B3%E7%B3%BB%E5%88%86%E7%B1%BB%E4%B8%8A%E7%9A%84%E5%B0%9D%E8%AF%95%E5%8F%8AKeras%E4%BB%A3%E7%A0%81%E5%A4%8D%E7%8E%B0/
- 微调百川Baichuan-13B保姆式教程,手把手教你训练百亿大模型: https://mp.weixin.qq.com/s/ZBY6kbogHjbCQvZBzNEqag
- HuggingFace Dataset people_relation_classification: https://huggingface.co/datasets/jclian91/people_relation_classification