区块链世界的大数据入门之zkMapReduce简介
1. 引言
跨链互操作性的未来将围绕多链dapp之间的动态和数据丰富的关系构建。Lagrange Labs 正在构建粘合剂,以帮助安全地扩展基于零知识证明的互操作性。
2. ZK大数据栈
Lagrange Labs 的ZK大数据栈 为一种专有的证明结构,用于在任意动态分布式计算的同时生成大规模batch storage proof。ZK大数据堆栈可扩展到任何分布式计算框架,从MapReduce到RDD再到分布式SQL。
使用Lagrange Labs ZK大数据栈,可以从单个区块头生成证明,用于证明任意深度的历史storage slot 状态数组 和 对这些状态执行的分布式计算的结果。简而言之,每个证明都在一个步骤中结合了storage proof的验证 和 可验证的分布式计算。
在本文中,将讨论ZK-MapReduce(ZKMR)——Lagrange Labs ZK大数据栈 的第一个产品。
3. 何为MapReduce
在传统的顺序计算中,单个处理器按照线性路径执行整个程序,其中每条指令都按其在代码中出现的顺序执行。使用MapReduce和类似的分布式计算范式(如RDD),计算被划分为多个小任务,这些小任务可以在多个处理器上并行执行。
MapReduce的工作原理是将一个大数据集分解成更小的块,并将它们分布在一个机器集群中。大体上,这种计算遵循三个不同的步骤:
- 1)Map:每台机器对其数据块执行map操作,将其转换为一组键值(key-value)对。
- 2)Shuffle:对Map操作生成的键值对按键(key)进行shuffle和排序。
- 3)Reduce:Shuffle的结果被传递给Reduce操作,Reduce操作聚合数据并产生最终输出。
MapReduce的主要优点在于其可扩展性。由于计算分布在多台机器上,因此它可以处理无法按顺序处理的大规模数据集。此外,MapReduce的分布式特性允许计算在更多的机器上水平扩展,而不是在计算时间方面垂直扩展。
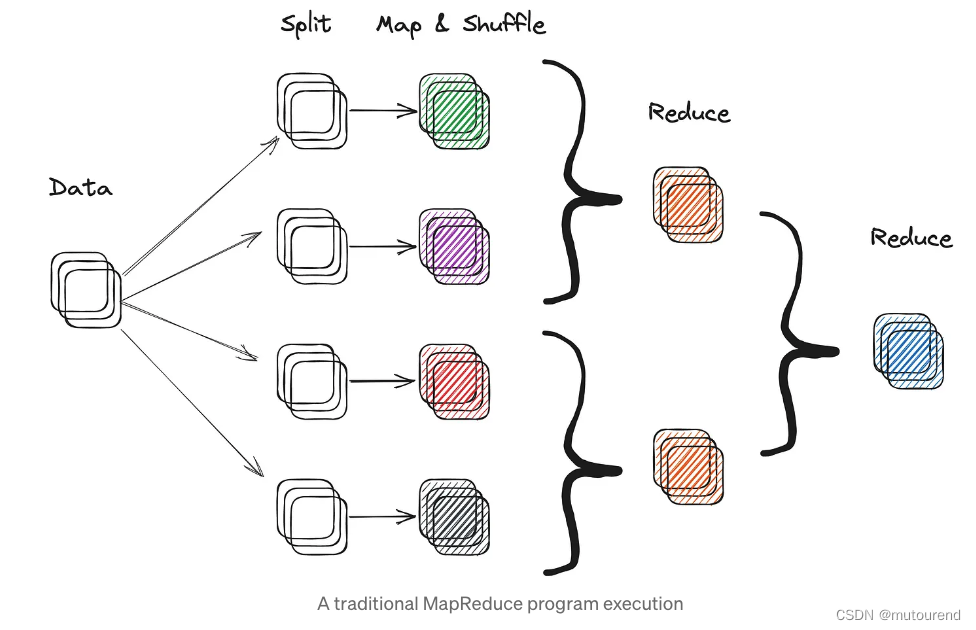
分布式计算范例(如MapReduce或RDD)通常用于Web 2.0架构中,用于处理和分析大型数据集。大多数大型web 2.0公司,如谷歌、亚马逊和脸书,都在很大程度上利用分布式计算来处理PB级的搜索数据和用户数据集。用于分布式计算的现代框架包括Hive、Presto和Spark。
3. zkMapReduce介绍
Lagrange的zkMapReduce(zkMR)为MapReduce的扩展,其利用递归证明来证明基于大量链上状态数据的分布式计算的正确性。通过在分布式计算作业的Map或Reduce步骤期间为每个给定worker生成计算正确性的证明来实现的。这些证明可以递归组合,构建整个分布式计算工作流有效性的单一证明。换句话说,可以将较小计算的证明组合起来,以创建整个计算的证明。
将worker computation的多个sub-proofs组合成单个zkMR proof的能力使其能够更有效地扩展到大型数据集上的复杂计算。
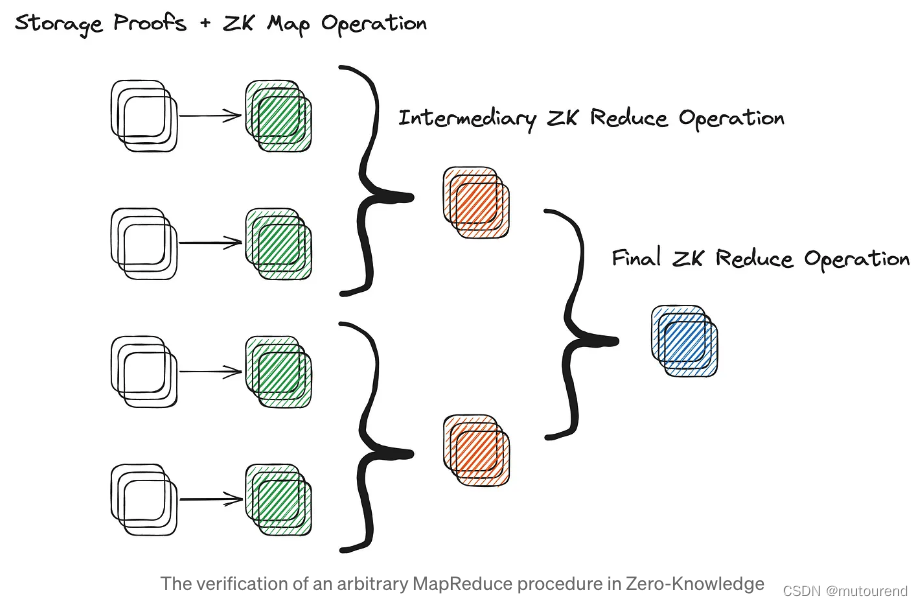
与zkVM相比,zkMR的主要优势之一在于,其能在合约现有和历史storage state基础之上执行动态计算。无需:
- 分别跨越一系列区块来证明storage inclusion
- 再基于aggregated data set之上证明一系列计算
zkMR(以及Lagrange的其它ZK大数据产品)支持将以上2者组合为单个proof。与其他设计相比,这样可大幅降低生成zkMR proof的证明时长。
3.1 zkMR示例
为理解递归证明的组合原理,先举个简单的例子。假设需计算某DEX内某资产对 在指定期间内的平均流动性。为此,必须:
- 对于每个区块,必须展示其correctness of an inclusion proof on the state root,以证明该DEX内的流动性数量。
- 必须对每个区块的流动性求和,再除以区块数。
这样的顺序计算类似为:
# Sequential Execution
func calculate_avg_eth_price_per_block(var mpt_paths, var liquidity_per_block){
var sum = 0;
for(int i=0; i<len(liquidity_per_block); i++){
verify_inclusion(liquidity_per_block[i], mpt_path[i])
sum += liquidity_per_block[i]
}
var avg_liquidity = sum / num_blocks
// return the average liquidity
return avg_liquidity
}
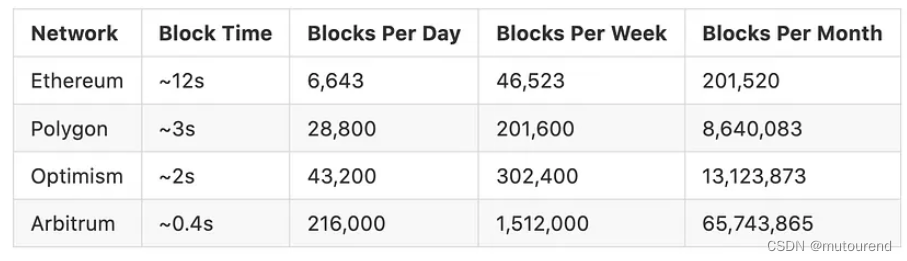
但是,随着所包含state数量的增加,该程序的性能将急速下降。以下图为例,展示每个链单位时间内的区块数。以Arbitrum上的单个DEX一个月内某单一DEX的平均流动性为例,其需要的数据需横跨约6500万个rollup区块。
但是,借助zkMR,可将该dataset切分为更小的chunks,并分发给多个处理器。每个机器执行map操作——计算Merkle-Patricia Trie(MPT)proof 并基于其chunk of data对流动性求和。该map操作会生成key-value pair,其中key为某constant string(如average_liquidity),value为a tuple containing the sum and count。
该map操作输出的为一组key-value pairs,可shuffled and sorted by key,然后传递给reduce操作。reduce接收的为key-value pair,其中key为average_liquidity,value为a list of tuples containing the sum and count of the liquidity from each map操作。该reduce操作将通过对单个sums和counts求和来聚合数据,然后将final sum除以final count,以获得最终的平均流动性。
示例代码为:
# Map step
func map(liquidity_data_chunk,mpt_path_chunk){
var sum = 0
for(int i=0; i<len(liquidity_data_chunk); i++){
verify_inclusion(liquidity_data_chunk[i], mpt_path_chunk[i])
sum += liquidity_data_chunk[i]
}
return ("average_liquidity", (sum, len(liquidity_data_chunk)))
}
# Reduce step
func reduce(liquidity_data_chunk){
var sum = 0
var count = 0
for(int i=0; i<len(liquidity_data_chunk); i++){
sum += value[0]
count += value[1]
}
return ("average_liquidity", sum/count)
}
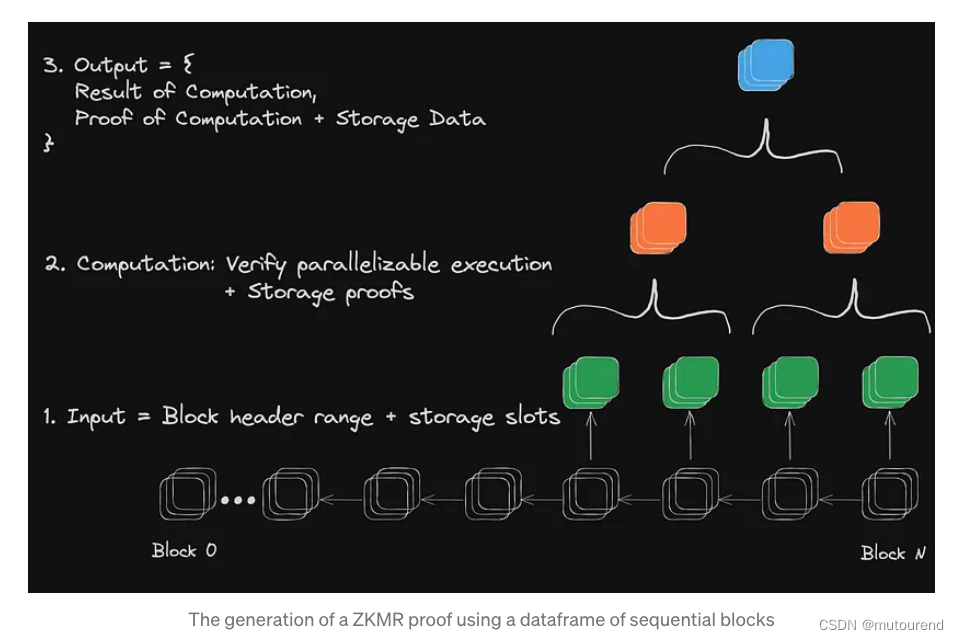
广义上来说,可将开发者定义和消费zkMR proof的流程分为三步:
- 1)定义dataframe和computations:zkMR proof基于某dataframe来执行,所谓dataframe是指一定范围的区块,以及这些区块内的特定memory slots。如上例中,dataframe是指流动性求平均的区块方位,memory slot对应某DEX内某资产的流动性。
- 2)为batched storage生成证明 并 分发计算:zkMR proof会验证某特定dataframe input的计算结果。每个dataframe对应某个特定的区块头。组委验证计算的一部分,每个proof必须证明现有底层状态数据存在的同时,还需证明基于这些数据的动态计算结果。如上例中,所谓的动态计算设置求平均操作。
- 3)Proof verification:zkMR proof可提交并在任意EVM兼容链上验证(后续将支持更多的虚拟机)。
3.2 增加不可知传输层
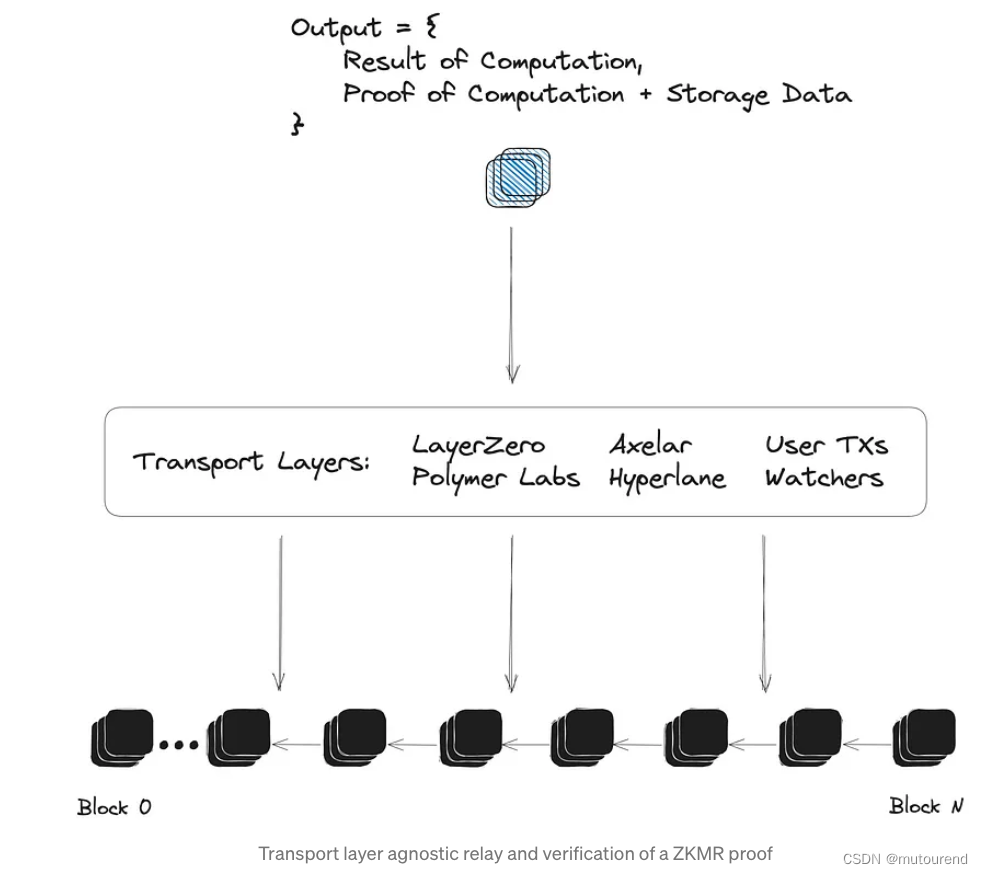
zkMR proof(以及其他zk Big Data proof)的强大特性之一是其可实现传输层不可知。由于proof是基于初始的区块头input生成的,任何现有的传输层都可用于生成和relay zkMR proof。现有的传输层包含有;
- messaging protocol
- oracle
- bridge
- watcher/cron job
- 甚至untrusted or incentivized用户机制
zkMR proof的灵活性可大幅增加链间state的表达性,而不需要与现有的高性能传输基础设施竞争。
Lagrange SDK提供了简单的接口来将zk Big Data proof集成进任何现有的跨链messaging或bridging协议中。通过简单的函数调用,某协议可简单请求某指定区块头内某特定dataframe的任意计算结果的proof。
当与现有协议集成时,zkMR不设计为对用作proof input的区块头的有效性做assertion。通常当传输消息时,传输协议可证明或断言某区块头的有效性,也可额外包含基于某dataframe历史状态之上的动态计算。
值得指出的是,zkMR proof还支持将多个链的proof合并为单个final computation。
4. zkMR性能改进
现有的zkMR看起来要比传统的线性计算更复杂,其性能可随并行处理器/机器而水平扩展,而不是随时间垂直扩展。
最大并行化情况下,证明某zk MapReduce流程的时间复杂度为 O ( log ( n ) ) O(log (n)) O(log(n)),而顺序执行需要的run-time为 O ( n ) O(n) O(n)。
例如,计算以太坊区块数据1天内的平均流动性。顺序执行需要循环6643 steps。具有recursive proof的分布式方式,仅需要单个map操作,高达6643个并行线程以及12个recursive reduction steps。从而可将rum-time复杂度reduce 约523倍。
对于扩容方案间的state storage碎片,如app chains、app rollup L3s、alt-L2s,链上数据以指数级增长并碎片化。很快就有关于:如何处理部署在100个不同app rollups上的某DEX的1周TWAP数据?
总之,zkMR是在分布式计算环境下、在zero-knowledge上下文中处理大规模数据集的强大范例。虽然顺序计算在通用应用程序开发中效率很高,表达能力很强,但在分析和处理大型数据集时,它的优化效果很差。分布式计算的效率使其成为主流Web2的许多大数据处理的标准。在zero-knowledge上下文中,可扩展性和容错性使其成为处理不可信大数据应用程序的理想支柱,如复杂的链上定价、波动性和流动性分析。
参考资料
[1] Lagrange Labs 2023年5月博客 A Big Data Primer: Introducing ZK MapReduce