单图换脸roop源码与环境配置
前言
1.roop是新开源了一个单图就可以进行视频换脸的项目,只需要一张所需面部的图像。不需要数据集,不需要训练。
2.大概的测试了一下,正脸换脸效果还不错,融合也比较自然。但如果人脸比较大,最终换出的效果可能会有些模糊。侧脸部分的幅度不宜过大,否则会出现人脸乱飘的情况。在多人场景下,也容易出现混乱。
3.使用简单,在处理单人视频和单人图像还是的换脸效果还是可以的,融合得也不错,适合制作一些小视频或单人图像。
4.效果如下:

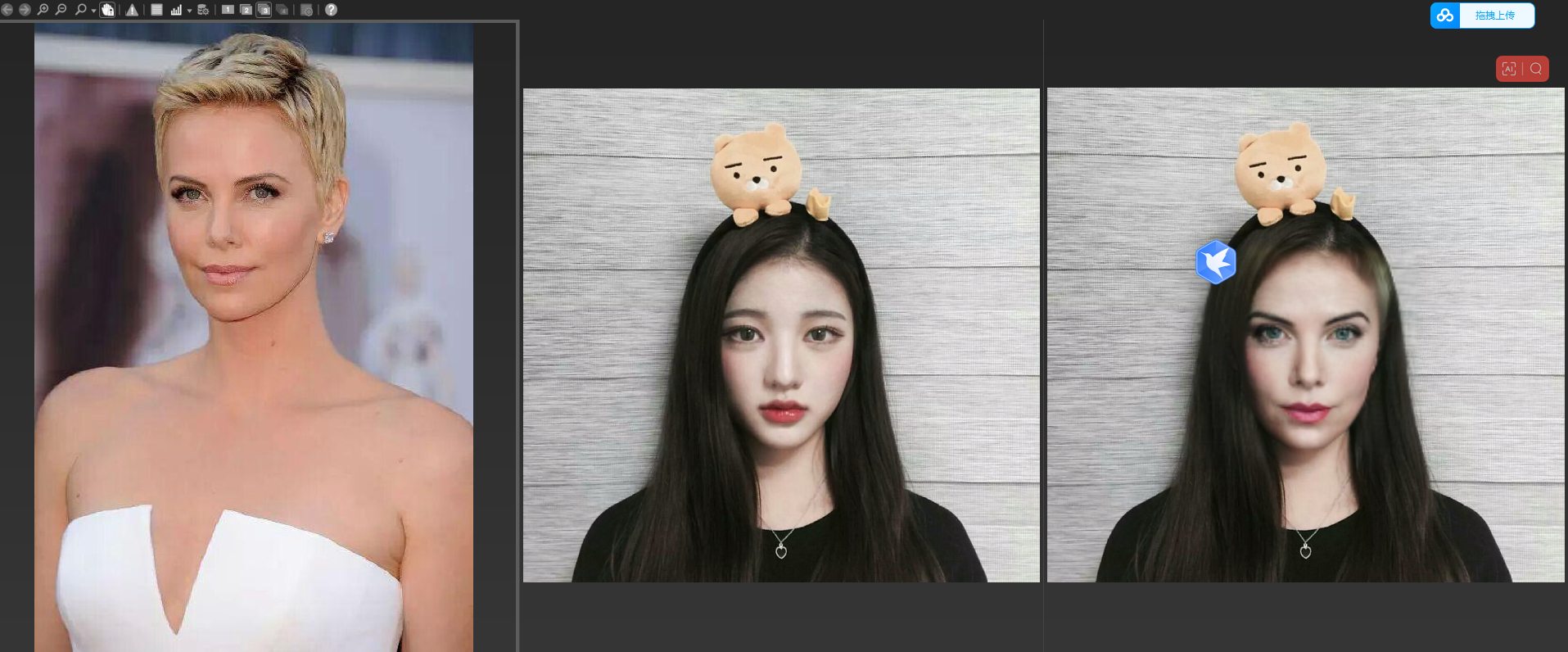
环境安装
1.我这里部署部署环境是win 10、cuda 11.7、cudnn 8.5、GPU是N卡的3060(6G显存),加anaconda3.
2.源码下载,如果用不了git,可以下载打包好的源码和模型。
git clone https://github.com/s0md3v/roop.git
cd roop3.创建环境
conda create --name roop python=3.10
activate roop
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
pip install -r requirements.txt

4.安装onnxruntime-gpu推理库
pip install onnxruntime-gpu5.运行程序
python run.py运行,它会下载一个500多m的模型,国内的网可能下载得很慢,也可以单独下载之后放到roop根目录下。

7.报错
ffmpeg is not installed!这个是缺少了FFmpeg,FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。简单说来就是我们可以用它来进行视频的编解码,可以将视频文件转化为视频流,也可以将视频流转存储为视频文件。还有一个重点就是它是开源的。去官网下载后,加到环境变量就可以了。
8.如果在本地的机子跑起来很慢,把它做成服务器的方式运行,这样就可以在网页或者以微信公众 号或者小程序的方式访问,服务器端代码:
#!/usr/bin/env python3
import os
import sys
# single thread doubles performance of gpu-mode - needs to be set before torch import
if any(arg.startswith('--gpu-vendor') for arg in sys.argv):
os.environ['OMP_NUM_THREADS'] = '1'
import platform
import signal
import shutil
import glob
import argparse
import psutil
import torch
import tensorflow
from pathlib import Path
import multiprocessing as mp
from opennsfw2 import predict_video_frames, predict_image
from flask import Flask, request
# import base64
import numpy as np
from gevent import pywsgi
import cv2, argparse
import time
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
import roop.globals
from roop.swapper import process_video, process_img, process_faces, process_frames
from roop.utils import is_img, detect_fps, set_fps, create_video, add_audio, extract_frames, rreplace
from roop.analyser import get_face_single
import roop.ui as ui
signal.signal(signal.SIGINT, lambda signal_number, frame: quit())
parser = argparse.ArgumentParser()
parser.add_argument('-f', '--face', help='use this face', dest='source_img')
parser.add_argument('-t', '--target', help='replace this face', dest='target_path')
parser.add_argument('-o', '--output', help='save output to this file', dest='output_file')
parser.add_argument('--keep-fps', help='maintain original fps', dest='keep_fps', action='store_true', default=False)
parser.add_argument('--keep-frames', help='keep frames directory', dest='keep_frames', action='store_true', default=False)
parser.add_argument('--all-faces', help='swap all faces in frame', dest='all_faces', action='store_true', default=False)
parser.add_argument('--max-memory', help='maximum amount of RAM in GB to be used', dest='max_memory', type=int)
parser.add_argument('--cpu-cores', help='number of CPU cores to use', dest='cpu_cores', type=int, default=max(psutil.cpu_count() / 2, 1))
parser.add_argument('--gpu-threads', help='number of threads to be use for the GPU', dest='gpu_threads', type=int, default=8)
parser.add_argument('--gpu-vendor', help='choice your GPU vendor', dest='gpu_vendor', default='nvidia', choices=['apple', 'amd', 'intel', 'nvidia'])
args = parser.parse_known_args()[0]
if 'all_faces' in args:
roop.globals.all_faces = True
if args.cpu_cores:
roop.globals.cpu_cores = int(args.cpu_cores)
# cpu thread fix for mac
if sys.platform == 'darwin':
roop.globals.cpu_cores = 1
if args.gpu_threads:
roop.globals.gpu_threads = int(args.gpu_threads)
# gpu thread fix for amd
if args.gpu_vendor == 'amd':
roop.globals.gpu_threads = 1
if args.gpu_vendor:
roop.globals.gpu_vendor = args.gpu_vendor
else:
roop.globals.providers = ['CPUExecutionProvider']
sep = "/"
if os.name == "nt":
sep = "\"
def limit_resources():
# prevent tensorflow memory leak
gpus = tensorflow.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tensorflow.config.experimental.set_memory_growth(gpu, True)
if args.max_memory:
memory = args.max_memory * 1024 * 1024 * 1024
if str(platform.system()).lower() == 'windows':
import ctypes
kernel32 = ctypes.windll.kernel32
kernel32.SetProcessWorkingSetSize(-1, ctypes.c_size_t(memory), ctypes.c_size_t(memory))
else:
import resource
resource.setrlimit(resource.RLIMIT_DATA, (memory, memory))
def pre_check():
if sys.version_info < (3, 9):
quit('Python version is not supported - please upgrade to 3.9 or higher')
if not shutil.which('ffmpeg'):
quit('ffmpeg is not installed!')
model_path = os.path.join(os.path.abspath(os.path.dirname(__file__)), '../inswapper_128.onnx')
if not os.path.isfile(model_path):
quit('File "inswapper_128.onnx" does not exist!')
if roop.globals.gpu_vendor == 'apple':
if 'CoreMLExecutionProvider' not in roop.globals.providers:
quit("You are using --gpu=apple flag but CoreML isn't available or properly installed on your system.")
if roop.globals.gpu_vendor == 'amd':
if 'ROCMExecutionProvider' not in roop.globals.providers:
quit("You are using --gpu=amd flag but ROCM isn't available or properly installed on your system.")
if roop.globals.gpu_vendor == 'nvidia':
CUDA_VERSION = torch.version.cuda
CUDNN_VERSION = torch.backends.cudnn.version()
if not torch.cuda.is_available():
quit("You are using --gpu=nvidia flag but CUDA isn't available or properly installed on your system.")
if CUDA_VERSION > '11.8':
quit(f"CUDA version {CUDA_VERSION} is not supported - please downgrade to 11.8")
if CUDA_VERSION < '11.4':
quit(f"CUDA version {CUDA_VERSION} is not supported - please upgrade to 11.8")
if CUDNN_VERSION < 8220:
quit(f"CUDNN version {CUDNN_VERSION} is not supported - please upgrade to 8.9.1")
if CUDNN_VERSION > 8910:
quit(f"CUDNN version {CUDNN_VERSION} is not supported - please downgrade to 8.9.1")
def get_video_frame(video_path, frame_number = 1):
cap = cv2.VideoCapture(video_path)
amount_of_frames = cap.get(cv2.CAP_PROP_FRAME_COUNT)
cap.set(cv2.CAP_PROP_POS_FRAMES, min(amount_of_frames, frame_number-1))
if not cap.isOpened():
print("Error opening video file")
return
ret, frame = cap.read()
if ret:
return cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
cap.release()
def preview_video(video_path):
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print("Error opening video file")
return 0
amount_of_frames = cap.get(cv2.CAP_PROP_FRAME_COUNT)
ret, frame = cap.read()
if ret:
frame = get_video_frame(video_path)
cap.release()
return (amount_of_frames, frame)
def status(string):
value = "Status: " + string
if 'cli_mode' in args:
print(value)
else:
ui.update_status_label(value)
def process_video_multi_cores(source_img, frame_paths):
n = len(frame_paths) // roop.globals.cpu_cores
if n > 2:
processes = []
for i in range(0, len(frame_paths), n):
p = POOL.apply_async(process_video, args=(source_img, frame_paths[i:i + n],))
processes.append(p)
for p in processes:
p.get()
POOL.close()
POOL.join()
def select_face_handler(path: str):
args.source_img = path
def select_target_handler(path: str):
args.target_path = path
return preview_video(args.target_path)
def toggle_all_faces_handler(value: int):
roop.globals.all_faces = True if value == 1 else False
def toggle_fps_limit_handler(value: int):
args.keep_fps = int(value != 1)
def toggle_keep_frames_handler(value: int):
args.keep_frames = value
def save_file_handler(path: str):
args.output_file = path
def create_test_preview(frame_number):
return process_faces(
get_face_single(cv2.imread(args.source_img)),
get_video_frame(args.target_path, frame_number)
)
app = Flask(__name__)
@app.route('/face_swap', methods=['POST'])
def face_swap():
if request.method == 'POST':
args.source_img=request.form.get('source_img')
args.target_path = request.form.get('target_path')
args.output_file = request.form.get('output_path')
keep_fps = request.form.get('keep_fps')
if keep_fps == '0':
args.keep_fps = False
else:
args.keep_fps = True
Keep_frames = request.form.get('Keep_frames')
if Keep_frames == '0':
args.Keep_frames = False
else:
args.Keep_frames = True
all_faces = request.form.get('all_faces')
if all_faces == '0':
args.all_faces = False
else:
args.all_faces = True
if not args.source_img or not os.path.isfile(args.source_img):
print("n[WARNING] Please select an image containing a face.")
return
elif not args.target_path or not os.path.isfile(args.target_path):
print("n[WARNING] Please select a video/image to swap face in.")
return
if not args.output_file:
target_path = args.target_path
args.output_file = rreplace(target_path, "/", "/swapped-", 1) if "/" in target_path else "swapped-" + target_path
target_path = args.target_path
test_face = get_face_single(cv2.imread(args.source_img))
if not test_face:
print("n[WARNING] No face detected in source image. Please try with another one.n")
return
if is_img(target_path):
if predict_image(target_path) > 0.85:
quit()
process_img(args.source_img, target_path, args.output_file)
# status("swap successful!")
return 'ok'
seconds, probabilities = predict_video_frames(video_path=args.target_path, frame_interval=100)
if any(probability > 0.85 for probability in probabilities):
quit()
video_name_full = target_path.split("/")[-1]
video_name = os.path.splitext(video_name_full)[0]
output_dir = os.path.dirname(target_path) + "/" + video_name if os.path.dirname(target_path) else video_name
Path(output_dir).mkdir(exist_ok=True)
# status("detecting video's FPS...")
fps, exact_fps = detect_fps(target_path)
if not args.keep_fps and fps > 30:
this_path = output_dir + "/" + video_name + ".mp4"
set_fps(target_path, this_path, 30)
target_path, exact_fps = this_path, 30
else:
shutil.copy(target_path, output_dir)
# status("extracting frames...")
extract_frames(target_path, output_dir)
args.frame_paths = tuple(sorted(
glob.glob(output_dir + "/*.png"),
key=lambda x: int(x.split(sep)[-1].replace(".png", ""))
))
# status("swapping in progress...")
if roop.globals.gpu_vendor is None and roop.globals.cpu_cores > 1:
global POOL
POOL = mp.Pool(roop.globals.cpu_cores)
process_video_multi_cores(args.source_img, args.frame_paths)
else:
process_video(args.source_img, args.frame_paths)
# status("creating video...")
create_video(video_name, exact_fps, output_dir)
# status("adding audio...")
add_audio(output_dir, target_path, video_name_full, args.keep_frames, args.output_file)
save_path = args.output_file if args.output_file else output_dir + "/" + video_name + ".mp4"
print("nnVideo saved as:", save_path, "nn")
# status("swap successful!")
return 'ok'
if __name__ == "__main__":
print('Statrt server----------------')
server = pywsgi.WSGIServer(('127.0.0.1', 5020), app)
server.serve_forever()
9.客户端代码
import requests
import base64
import numpy as np
import cv2
import time
source_img = "z1.jpg" #要换的脸
target_path= "z2.mp4" #目标图像或者视频
output_path = "zface2.mp4" #保存的目录和文件名
keep_fps = '0' #视频,是否保持原帧率
Keep_frames = '0'
all_faces = '0' #
data = {'source_img': source_img,'target_path' : target_path,'output_path':output_path,
'keep-fps' : keep_fps,'Keep_frames':Keep_frames,'all_faces':all_faces}
resp = requests.post("http://127.0.0.1:5020/face_swap", data=data)
print(resp.content)