Rust之自动化测试(一):如何编写测试
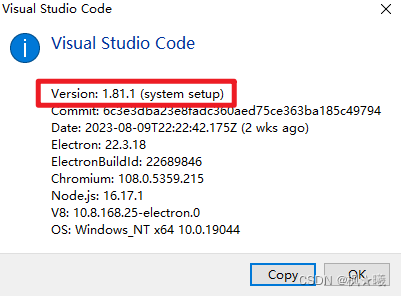
开发环境
- Windows 10
- Rust 1.71.1

- VS Code 1.81.1
项目工程
这里继续沿用上次工程rust-demo
编写自动化测试
Edsger W. Dijkstra在他1972年的文章《谦逊的程序员》中说,“程序测试可以是一种非常有效的方法来显示错误的存在,但它对于显示它们的不存在是完全不够的。”这并不意味着我们不应该尽可能多地尝试测试!
我们程序的正确性是指我们的代码在多大程度上做了我们想要它做的事情。Rust的设计高度关注程序的正确性,但正确性很复杂,不容易证明。Rust的类型系统承担了这个负担的很大一部分,但是类型系统不能捕获所有的东西。因此,Rust包含了对编写自动化软件测试的支持。
假设我们编写了一个函数add_two,它将传递给它的任何数字加2。这个函数的签名接受一个整数作为参数,并返回一个整数作为结果。当我们实现和编译这个函数时,Rust会进行所有的类型检查和借用检查,就像你到目前为止所学的那样,以确保我们不会向这个函数传递一个String值或一个无效的引用。但是Rust不能检查这个函数是否能准确地达到我们的目的,即返回参数加2,而不是参数加10或参数减50!这就是测试的由来。
我们可以编写一些测试来断言,例如,当我们将3传递给add_two函数时,返回值是5。每当我们对代码进行更改时,我们都可以运行这些测试,以确保任何现有的正确行为都没有改变。
测试是一项复杂的技能:虽然我们无法在一章中涵盖如何编写好的测试的每个细节,但我们将讨论Rust测试工具的机制。我们将讨论编写测试时可用的注释和宏,为运行测试提供的默认行为和选项,以及如何将测试组织成单元测试和集成测试。
如何编写测试
测试是Rust函数,它验证非测试代码是否以预期的方式运行。测试函数的主体通常执行这三个动作:
- 设置任何需要的数据或状态。
- 运行您想要测试的代码。
- 断言结果是你所期望的。
让我们来看看Rust专门为编写执行这些操作的测试提供的特性,包括test属性、一些宏和should_panic属性。
测试函数的剖析
最简单地说,Rust中的测试是一个用test属性注释的函数。属性是关于Rust代码片段的元数据;一个例子是我们在第5章中对结构使用的derive属性。要将函数更改为测试函数,请在fn之前的行中添加#[test]。当您使用cargo test命令运行您的测试时,Rust会构建一个测试运行二进制文件,运行带注释的函数并报告每个测试函数是通过还是失败。
每当我们用Cargo创建一个新的库项目时,就会自动为我们生成一个包含测试功能的测试模块。这个模块为您提供了一个编写测试的模板,这样您就不必在每次开始一个新项目时都去查找精确的结构和语法。您可以添加任意多的额外测试函数和测试模块!
在实际测试任何代码之前,我们将通过模板测试来探索测试工作的某些方面。然后,我们将编写一些真实世界的测试,调用我们编写的一些代码,并断言其行为是正确的。
让我们创建一个名为adder的新库项目,它将添加两个数:
$ cargo new adder --lib
Created library `adder` project
$ cd adder
adder库中src/lib.rs文件的内容应该如示例11-1所示。
文件名:src/lib.rs
#[cfg(test)]
mod tests {
#[test] // 测试
fn it_works() {
let result = 2 + 2;
assert_eq!(result, 4);
}
}示例11-1:由cargo new自动生成的测试模块和函数
现在,让我们忽略上面两行,把注意力集中在函数上。注意#[test]注释:这个属性表明这是一个测试函数,所以测试运行人员知道将这个函数视为一个测试。在tests模块中,我们还可能有非测试函数来帮助设置常见的场景或执行常见的操作,所以我们总是需要指出哪些函数是测试。
示例函数体使用了assert_eq!宏来断言包含2和2相加result的结果等于4。这个断言作为一个典型测试格式的例子。让我们运行它来看看这个测试是否通过。
cargo test命令运行我们项目中的所有测试,如示例11-2所示。
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.57s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
示例11-2:运行自动生成的测试的输出
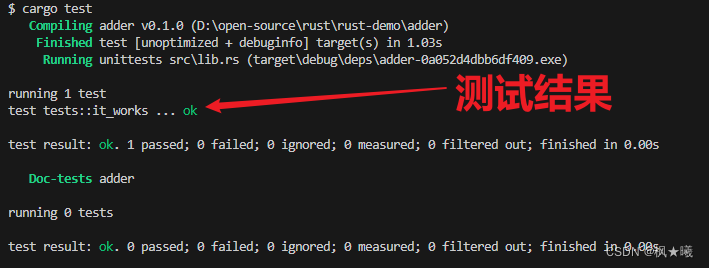
Cargo编译并运行了测试。我们看到runing1 test的行。下一行显示了生成的测试函数的名称,名为it_works,运行该测试的结果是ok的。总体总结test result: ok。意味着所有的测试都通过了,而写着1 passed; 0 failed总计测试通过或失败的次数。
0 measured测量统计值用于测量性能的基准测试。在撰写本文时,基准测试只在夜间Rust中可用。
从Doc-tests adder开始的测试输出的下一部分是任何文档测试的结果。我们还没有任何文档测试,但Rust可以编译任何出现在我们API文档中的代码示例。这个特性有助于保持您的文档和代码同步!现在,我们将忽略Doc-tests输出。
让我们开始根据自己的需要定制测试。首先将it_works函数的名称改为不同的名称,例如exploration,如下所示:
文件名:src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn exploration() {
assert_eq!(2 + 2, 4);
}
}然后再次运行cargo test。现在输出显示的是exploration而不是it_works:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.59s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::exploration ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
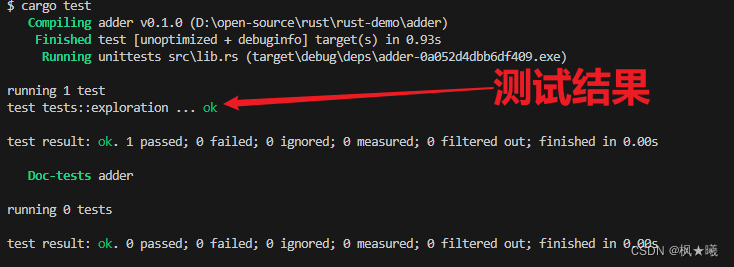
现在我们将添加另一个测试,但这次我们将做一个失败的测试!当测试函数出现问题时,测试就会失败。每个测试都在一个新线程中运行,当主线程发现一个测试线程已经死亡时,该测试就会被标记为失败。在第9章中,我们谈到了恐慌的最简单的方法是如何打电话给panic!宏观。输入新的测试作为一个名为another的函数,这样你的src/lib.rs文件看起来如示例11-3所示。
文件名:src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn exploration() {
assert_eq!(2 + 2, 4);
}
#[test]
fn another() {
panic!("Make this test fail");
}
}示例11-3:添加第二个测试,该测试将失败,因为我们称之为panic!宏指令
使用cargo test再次运行测试。输出应该如示例11-4所示,这表明我们的exploration测试通过了,而another测试失败了。
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.72s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::another ... FAILED
test tests::exploration ... ok
failures:
---- tests::another stdout ----
thread 'tests::another' panicked at 'Make this test fail', src/lib.rs:10:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::another
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
示例11-4:当一个测试通过而另一个测试失败时的测试结果
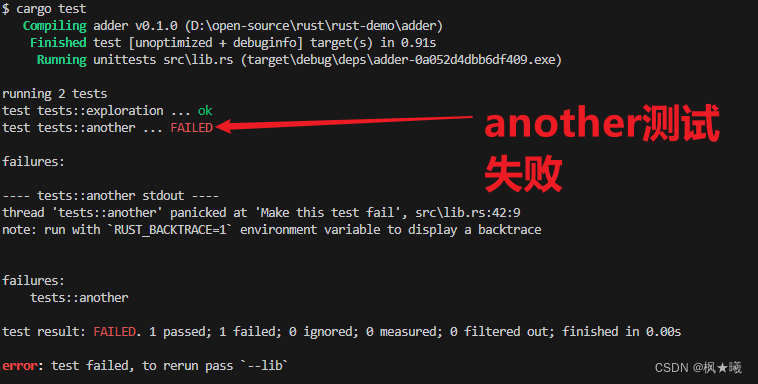
行test tests::another显示FAILED,而不是ok。在单独的结果和总结之间出现两个新的部分:第一部分显示每个测试失败的详细原因。在这种情况下,我们获得another失败的详细信息,因为它在src/lib.rs文件的第10行panicked at 'Make this test fail'时死机。
总结行显示在最后:总的来说,我们的测试结果是FAILED的。我们有一个测试通过,一个测试失败。
现在您已经看到了不同场景下的测试结果,让我们来看看除了panic!之外的一些宏在测试中很有用。
用assert!宏检查结果
assert!当您希望确保测试中的某个条件评估为真时,标准库提供的宏非常有用。我们给出assert!计算结果为布尔值的参数。如果该值为true,则什么都不会发生,测试通过。如果值为false,则assert!调用panic!导致测试失败。使用assert!帮助我们检查我们的代码是否按照我们想要的方式运行。
在第五章的示例5-15中,我们使用了一个Rectangular结构和一个can_hold方法,它们在示例11-5中重复出现。让我们将这段代码放到src/lib.rs文件中,然后使用assert!为它编写一些测试。
文件名:src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}示例11-5:使用第5章中的Rectangular结构及其can_hold方法
can_hold方法返回一个布尔值,这意味着它是assert!的完美用例。在示例11-6中,我们编写了一个测试,通过创建一个宽度为8、高度为7的Rectangular实例,并断言它可以容纳另一个宽度为5、高度为1的Rectangular实例,来练习can_hold方法。
文件名:src/lib.rs
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
}示例11-6:对can_hold的测试,检查一个较大的矩形是否可以容纳一个较小的矩形
注意,我们在tests模块中添加了新的一行:use super::*;。tests模块是一个常规的模块,它遵循我们在第7章节中提到的常见的可见性规则。因为tests模块是一个内部模块,我们需要将外部模块中的测试代码放到内部模块的范围内。我们在这里使用了一个glob,所以我们在外部模块中定义的任何东西都可以用于这个tests模块。
我们将我们的测试命名为llarger_can_hold_smaller,并且创建了我们需要的两个矩形实例。然后我们调用了assert!宏,并将调用larger.can_hold(&smaller)的结果传递给它。这个表达式应该返回true,所以我们的测试应该通过。让我们来了解一下!
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 1 test
test tests::larger_can_hold_smaller ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
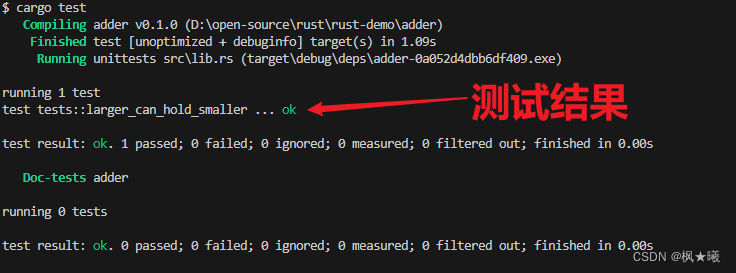
确实测试通过了!让我们添加另一个测试,这次断言较小的矩形不能容纳较大的矩形:
文件名:src/lib.rs
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
// --snip--
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}因为在这种情况下can_hold函数的正确结果是false,所以我们需要在将结果传递给assert!之前对其求反。因此,如果can_hold返回false,我们的测试将通过:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... ok
test tests::smaller_cannot_hold_larger ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
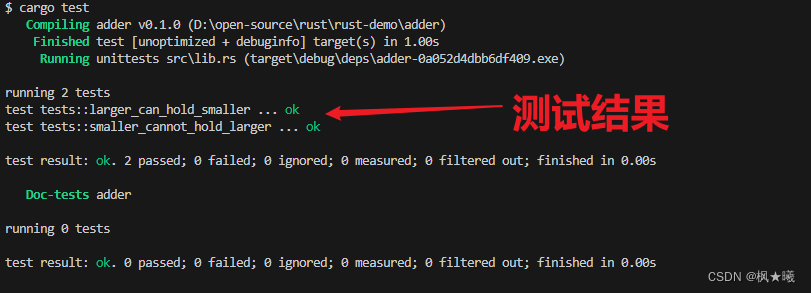
两项测试通过!现在让我们看看当我们在代码中引入一个bug时,测试结果会发生什么。我们将更改can_hold方法的实现,在比较宽度时用小于号替换大于号:
// --snip--
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width < other.width && self.height > other.height
}
}
运行测试现在会产生以下结果:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... FAILED
test tests::smaller_cannot_hold_larger ... ok
failures:
---- tests::larger_can_hold_smaller stdout ----
thread 'tests::larger_can_hold_smaller' panicked at 'assertion failed: larger.can_hold(&smaller)', src/lib.rs:28:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::larger_can_hold_smaller
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
我们的测试发现了漏洞!因为larger.width是8,smaller.width是5,所以can_hold中的宽度比较现在返回false: 8不小于5。
用宏assert_eq!和assert_ne!测试相等性
验证功能的一种常见方法是测试被测代码的结果与您期望代码返回的值之间是否相等。您可以使用assert!来做到这一点,并使用==运算符向其传递一个表达式。然而,这是一个非常常见的测试,标准库提供了一对宏——assert_eq!和assert_eq!—为了更方便地执行该测试。这些宏分别比较相等或不相等的两个参数。如果断言失败,它们还会打印这两个值,这更容易看出测试失败的原因;反之,assert!只指示它为==表达式获得了一个false,而不打印导致false的值。
在示例11-7中,我们编写了一个名为add_two的函数,将2加到它的参数中,然后我们使用assert_eq!测试这个函数。
文件名:src/lib.rs
pub fn add_two(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
assert_eq!(4, add_two(2));
}
}示例11-7:使用assert_eq!测试函数add_two
让我们检查它是否通过!
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
我们将4作为参数传递给assert_eq!,等于调用add_two(2)的结果。这个测试的代码行是test tests::it_adds_two...ok,ok文本表示我们的测试通过了!
让我们在代码中引入一个bug,看看assert_eq!是什么看起来当它失败时。将add_two函数的实现改为添加3:
pub fn add_two(a: i32) -> i32 {
a + 3
}
再次运行测试:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... FAILED
failures:
---- tests::it_adds_two stdout ----
thread 'tests::it_adds_two' panicked at 'assertion failed: `(left == right)`
left: `4`,
right: `5`', src/lib.rs:11:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_adds_two
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
我们的测试发现了bug!it_adds_two测试失败,消息告诉我们失败的断言是assertion failed: `(left == right)`以及left 和right值是什么。这条消息帮助我们开始调试:left的参数是4,但是right的参数是5,这里我们有add_two(2)。你可以想象,当我们有很多测试正在进行时,这将特别有帮助。
注意,在一些语言和测试框架中,等式断言函数的参数被称为expected和actual,我们指定参数的顺序很重要。然而,在Rust中,它们被称为left和right,我们指定我们期望的值和代码产生的值的顺序并不重要。我们可以把这个测试中的断言写成assert_eq!(add_two(2), 4),这将导致显示断言失败的相同assertion failed::`(left == right)`。
assert_ne!如果我们给它的两个值不相等,将通过,如果相等,将失败。当我们不确定一个值是什么,但是我们知道这个值绝对不应该是什么时,这个宏是最有用的。例如,如果我们正在测试一个函数,它肯定会以某种方式改变它的输入,但是改变输入的方式取决于我们在一周中的哪一天运行测试,那么最好的断言可能是函数的输出不等于输入。
表面之下,是assert_eq!和assert_ne!宏使用运算符==和!=,分别为。当断言失败时,这些宏使用调试格式打印它们的参数,这意味着被比较的值必须实现PartialEq和Debug特征。所有基本类型和大多数标准库类型都实现了这些特征。对于您自己定义的结构和枚举,您需要实现PartialEq来断言这些类型的相等性。当断言失败时,您还需要实现Debug来打印值。因为这两个特征都是可派生的特征,正如第5章示例5-12中提到的,这通常就像在你的结构或枚举定义中添加#[derive(PartialEq,Debug)]注释一样简单。请参阅附录C,“可衍生特征”,了解有关这些和其他可衍生特征的更多详细信息。
添加自定义失败消息
您还可以添加一个自定义消息,作为assert!的可选参数,与失败消息一起打印,assert_eq!,和assert_ne!。所需参数之后指定的任何参数都将传递给format!宏(在第8章的“用+运算符串联or格式!宏”部分),因此您可以传递一个包含{}占位符和要放入这些占位符的值的格式字符串。自定义消息对于记录断言的含义非常有用;当一个测试失败时,您会对代码的问题有更好的了解。
例如,假设我们有一个用名字问候别人的函数,我们想测试我们传递给函数的名字是否出现在输出中:
文件名:src/lib.rs
pub fn greeting(name: &str) -> String {
format!("Hello {}!", name)
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}对这个程序的要求还没有达成一致,我们很确定开头的Hello文本会改变。我们决定,当需求改变时,我们不需要更新测试,所以我们不检查greeting函数返回的值是否完全相等,而是断言输出包含输入参数的文本。
现在让我们通过将greeting改为排除name来引入一个bug,看看默认测试失败是什么样子的:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
运行该测试会产生以下结果:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished test [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at 'assertion failed: result.contains("Carol")', src/lib.rs:12:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
这个结果只是表明断言失败了,以及断言在哪一行。更有用的失败消息是打印greeting函数的值。让我们添加一个定制的失败消息,该消息由一个格式字符串组成,该格式字符串带有一个占位符,占位符中填充了我们从greeting函数中获得的实际值:
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(
result.contains("Carol"),
"Greeting did not contain name, value was `{}`",
result
);
}
现在,当我们运行测试时,我们将得到一个更具信息性的错误消息:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished test [unoptimized + debuginfo] target(s) in 0.93s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at 'Greeting did not contain name, value was `Hello!`', src/lib.rs:12:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
我们可以在测试输出中看到我们实际得到的值,这将帮助我们调试发生了什么,而不是我们预期会发生什么。
使用should_panic检查panic
除了检查返回值,检查我们的代码是否如我们所期望的那样处理错误情况也很重要。例如,考虑我们在第9章示例9-13中创建的猜测类型。其他使用Guess的代码依赖于Guess实例只包含1到100之间的值的保证。我们可以编写一个测试,确保试图创建一个值在该范围之外的Guess实例时会出错。
我们通过向测试函数添加属性should_panic来实现这一点。如果函数内部的代码出现混乱,则测试通过;如果函数内部的代码没有死机,测试就会失败。
示例11-8显示了一个测试,它检查Guess::new的错误条件是否在我们期望的时候发生。
文件名:src/lib.rs
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {}.", value);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}示例11-8:测试一个条件会导致一个panic!
我们将#[should_panic]属性放在#[test]属性之后,它所应用的测试函数之前。让我们看看测试通过后的结果:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished test [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests guessing_game
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
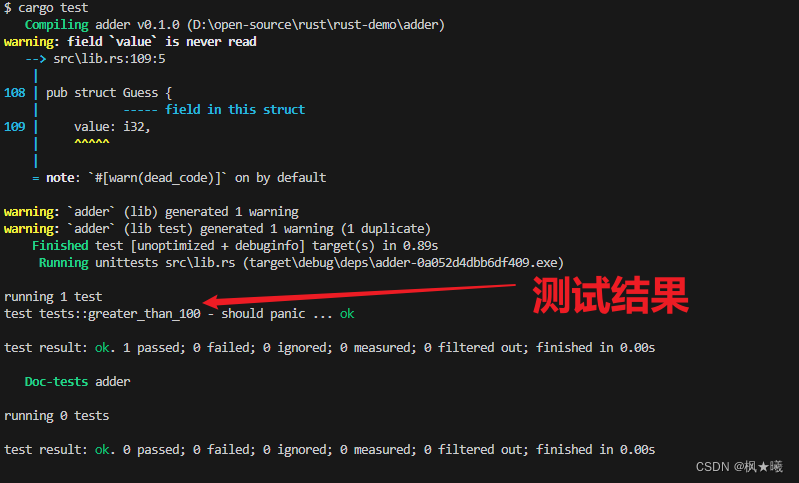
看起来不错!现在,让我们在代码中引入一个错误,删除如果值大于100,new将会死机的条件:
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!("Guess value must be between 1 and 100, got {}.", value);
}
Guess { value }
}
}
当我们运行示例11-8中的测试时,它会失败:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished test [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
note: test did not panic as expected
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
在这种情况下,我们没有得到非常有用的消息,但是当我们查看测试函数时,我们看到它被注释为#[should_panic]。我们得到的失败意味着测试函数中的代码没有导致死机。
使用should_panic的测试可能不精确。should_panic测试将会通过,即使测试因不同于我们预期的原因而死机。为了使should_panic测试更加精确,我们可以向should_panic属性添加一个可选的预期参数。测试工具将确保失败消息包含所提供的文本。例如,考虑示例11-9中Guess的修改代码,其中new根据值是太小还是太大而出现不同的消息。
文件名:src/lib.rs
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {}.",
value
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {}.",
value
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}示例11-9:测试panic!带有包含指定子字符串的紧急消息
这个测试将会通过,因为我们在should_panic属性的expected参数中输入的值是Guess::new函数出错的消息的子字符串。我们可以指定我们期望的整个紧急消息,在本例中,Guess value must be less than or equal to 100, got 200.。您选择指定的内容取决于恐慌消息中有多少是独特的或动态的,以及您希望测试有多精确。在这种情况下,紧急消息的子字符串足以确保测试函数中的代码执行else if value > 100的情况。
为了查看当带有expected消息的should_panic测试失败时会发生什么,让我们通过交换if value < 1和else if value > 100块的主体,再次在代码中引入一个bug:
if value < 1 {
panic!(
"Guess value must be less than or equal to 100, got {}.",
value
);
} else if value > 100 {
panic!(
"Guess value must be greater than or equal to 1, got {}.",
value
);
}
这一次,当我们运行should_panic测试时,它将失败:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
thread 'tests::greater_than_100' panicked at 'Guess value must be greater than or equal to 1, got 200.', src/lib.rs:13:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: `"Guess value must be greater than or equal to 1, got 200."`,
expected substring: `"less than or equal to 100"`
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
失败消息表明该测试确实如我们预期的Result<T,E >那样死机,但是死机消息不包括预期的字符串'Guess value must be less than or equal to 100'。在这种情况下,我们得到的紧急消息是Guess value must be greater than or equal to 1, got 200。现在我们可以开始找出我们的错误在哪里了!
在测试中使用Result< T,E >
到目前为止,我们的测试失败时都会惊慌失措。我们也可以编写使用Result<T,E >的测试!下面是示例11-1中的测试,重写后使用Result<T,E >并返回一个Err而不是死机:
#[cfg(test)]
mod tests {
#[test]
fn it_works() -> Result<(), String> {
if 2 + 2 == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}it_works函数现在有了Result <(),String >返回类型。在函数体中,而不是调用assert_eq!,当测试通过时,我们返回Ok(()),当测试失败时,返回一个包含String的Err。
编写返回Result<T,E >的测试使您能够在测试体中使用问号操作符,这是一种编写测试的便捷方式,如果测试中的任何操作返回Err变量,测试就会失败。
不能在使用Result<T,E >的测试上使用#[should_panic]批注。要断言一个操作返回一个EErrrr变量,不要在Result<T,E >值上使用问号运算符。而是使用assert!(value.is_err())。
现在您已经知道了编写测试的几种方法,让我们看看运行测试时会发生什么,并探索我们可以使用cargo test的不同选项。
本章重点
- 自动化测试的概念
- 如何编写测试用例
- assert!在测试用例中如何使用
- assert_eq!和assert_ne!在测试用例中如何使用
- 添加自定义失败信息
- 使用should_panic检查panic
- 使用Result<T, E>