【Golang】DFA算法过滤敏感词Golang实现
什么是DFA算法
DFA全称:Deterministic Finite Automaton,翻译过来就是确定性有限自动机,其特征是,有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态,但是确定性有穷自动机不会从同一状态触发的两个边标志由相同的符号。
通俗的讲DFA算法就是把你要匹配的做成一颗字典树,然后对你输入的内容进行匹配的过程
如何构建这颗字典树呢
这是一颗简单字典树的,我们的第一步就是构建出一个这样的包含敏感词的树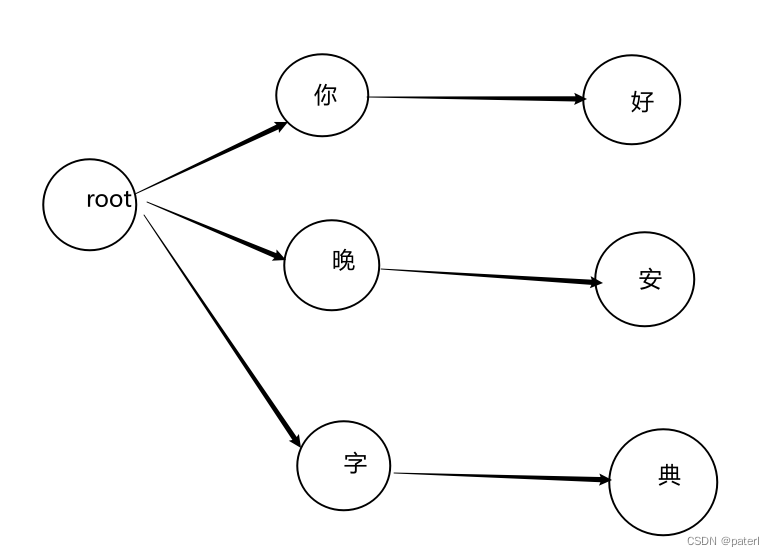
下面我说一下构建过程
每个节点的结构
// 定义一个Node结构体,代表DFA的一个节点。
type Node struct {
End bool // End字段表示是否为一个单词的结束。
Next map[rune]*Node // Next字段是一个映射,用于存储此节点的所有子节点。
}
// 定义一个DFAMatcher结构体,代表一个完整的DFA。
type DFAMatcher struct {
replaceChar rune // replaceChar字段是替换敏感词的字符。
root *Node // root字段是DFA的根节点。
}
我们要先创捷出一个root节点,在root节点中是不存放数据的
//创建出一个DFA树的根节点实例
func NewDFAMather() *DFAMatcher {
return &DFAMatcher{
root: &Node{
End: false,
},
}
}
在确定完节点的结构后,我们需要跟据敏感词来构建这颗字典树
// Build方法用于构建DFA,它会将提供的所有单词添加到DFA中。
func (d *DFAMatcher) Build(words []string) {
for _, item := range words { // 遍历提供的所有单词。
d.root.AddWord(item) // 将每一个单词添加到DFA的根节点。
}
}
// AddWord方法用于向当前节点添加一个单词。
// 这个方法会遍历单词的每一个字符,并为每一个字符添加一个子节点。
func (n *Node) AddWord(word string) {
node := n // 从当前节点开始。
chars := []rune(word) // 将字符串转化为rune类型的切片,以便处理Unicode字符。
for index, _ := range chars { // 遍历单词的每一个字符。
node = node.AddChild(chars[index]) // 递归地为每一个字符添加子节点。
}
node.End = true // 设置最后一个节点为单词的结束。
}
// AddChild方法向当前节点添加一个子节点。
// 如果子节点已经存在,它将不会被重复添加。
func (n *Node) AddChild(c rune) *Node {
if n.Next == nil { // 如果Next字段为nil,则初始化一个映射。
n.Next = make(map[rune]*Node)
}
//检查字符c是否已经是当前节点的子节点。
if next, ok := n.Next[c]; ok { // 如果ok为true,则字符c已经是当前节点的子节点,直接返回该子节点。
return next
} else { // 否则,创建一个新的节点,并将其设置为当前节点的子节点。
n.Next[c] = &Node{
End: false,
Next: nil,
}
return n.Next[c] // 返回新创建的子节点。
}
}
根据上面的代码就可一构建出一颗包含你传入的敏感词的树,在这颗树种根节点不存放数据
过滤关键词
下面就是跟据你传入的内容来过滤敏感词了,你可以把敏感词替换成其他字符,也可以统计敏感词的个数,这就看你自己需要什么了
下面是代码实现
// Match方法用于在文本中查找并替换敏感词。
// 它返回找到的敏感词列表和替换后的文本。
func (d *DFAMatcher) Match(text string) (sensitiveWords []string, replaceText string) {
if d.root == nil { // 如果DFA是空的,直接返回原始文本。
return nil, text
}
textChars := []rune(text) // 将文本转化为rune类型的切片,以便处理Unicode字符。
textCharsCopy := make([]rune, len(textChars)) // 创建一个文本字符的副本,用于替换敏感词。
copy(textCharsCopy, textChars) // 复制原始文本字符到副本。
length := len(textChars) // 获取文本的长度。
for i := 0; i < length; i++ { // 遍历文本的每一个字符。
// 在DFA树中查找当前字符对应的子节点
temp := d.root.FindChild(textChars[i])
if temp == nil {
continue // 如果不存在匹配,继续检查下一个字符
}
j := i + 1
// 遍历文本中的字符,查找匹配的敏感词,第一个匹配上了,就进行后面的向下匹配
for ; j < length && temp != nil; j++ {
if temp.End {
// 如果找到一个敏感词,将其添加到结果列表中,并在副本中替换为指定字符
sensitiveWords = append(sensitiveWords, string(textChars[i:j]))
replaceRune(textCharsCopy, '*', i, j) //替换敏感词
}
temp = temp.FindChild(textChars[j])
}
// 处理文本末尾的情况,如果末尾是一个完整的敏感词,添加到结果列表中,并在副本中替换为指定字符
if j == length && temp != nil && temp.End {
sensitiveWords = append(sensitiveWords, string(textChars[i:length]))
replaceRune(textCharsCopy, '*', i, length)
}
}
return sensitiveWords, string(textCharsCopy) // 返回匹配到的敏感词列表和替换后的文本
}
// FindChild方法用于在当前节点的子节点中查找一个特定的子节点。
func (n *Node) FindChild(c rune) *Node {
if n.Next == nil { // 如果Next字段为nil,则直接返回nil。
return nil
}
//检查字符c是否是当前节点的子节点。
if _, ok := n.Next[c]; ok { // 如果ok为true,则字符c是当前节点的子节点,返回该子节点。
return n.Next[c]
}
return nil // 否则,返回nil。
}
//替换掉文章中出现的关键词
func replaceRune(chars []rune, replaceChar rune, begin int, end int) {
for i := begin; i < end; i++ {
chars[i] = replaceChar
}
}
以上就是使用Golang代码实现了一个简单的DFA算法过滤敏感词的一个算法,这个算法相对于其他的性能更好,匹配更快。