中国模式识别与计算机视觉大会|多模态模型及图像安全的探索及成果

目录
前言
随着人工智能技术的不断演进,多模态大模型已是当下比较热的研究方向,它可以同时理解和生成多种输入和输出模态,如文本、图像、语音等,能够更好地模拟人类的多感知能力,给文档图像的分析处理带来了新的机遇和挑战!
近期,中国模式识别与计算机视觉大会在厦门举办,是国内顶级的模式识别和计算机视觉领域学术盛会。大会汇聚了国内国外模式识别和计算机视觉理论与应用研究的广大科研工作者及工业界同行,分享我国模式识别与计算机视觉领域的最新理论和技术成果。通过此次会议,进一步加强本领域的同行与东南沿海地区的学者和企业进行学术交流和技术碰撞,从而促进模式识别与计算机视觉领域的协同合作与融合创新。
合合信息是人工智能及大数据领域的领先企业。在本次大会中合合信息智能技术平台事业部副总经理郭丰俊博士分享了文档图像前沿技术中的成果及探索,主要包括多模态模型以及图像安全,让我们一起来了解一下吧。
一、多模态模型进展与探索
多模态大模型可以用于提高文档图像的处理和分析能力,使文档变得更易于管理、检索和理解。而文档图像是多模态天然的一个属性,它们能够为文档管理、信息提取和文档分析等任务提供有力支持。
1、GPT-4V (多模态)测试
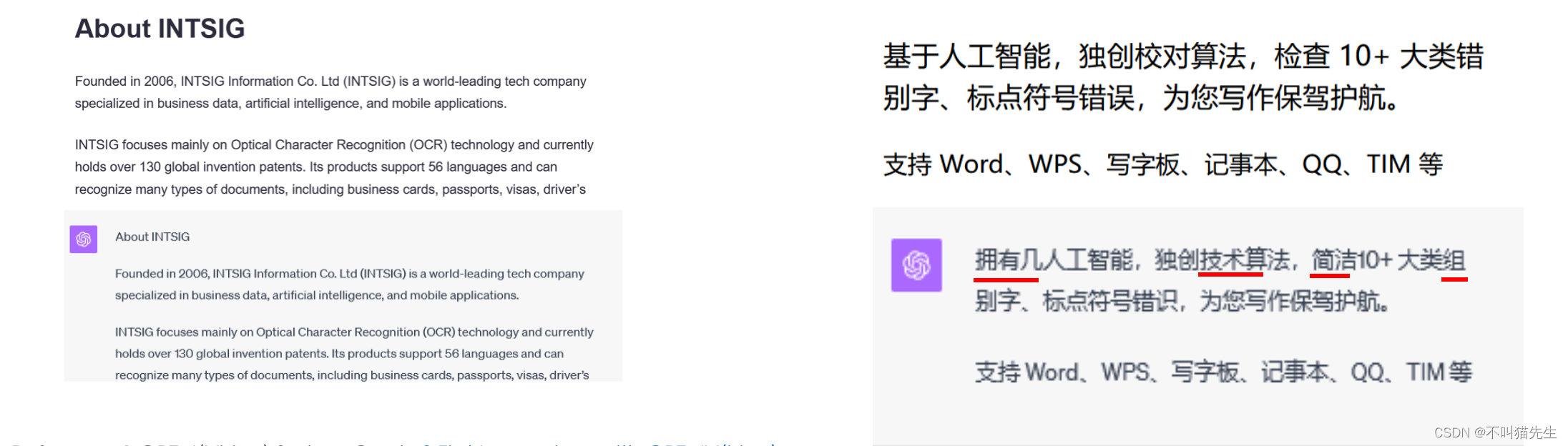
随着 GPT-4V 到来,多模态能力发生了跃迁,不仅能理解文本,还能理解图像。经过初步的测试发现它对英文 OCR 较好,但是对中文 OCR 不理想。GPT-4V 有时会错误地将图像中的两串文字组合在一起,创造出一个虚构的术语。它还会遗漏文字或字符、忽略数学符号,以及无法识别相当明显的物体和地点设置。下图展示了 GPT-4V 的错误识别:
2、LLM时代文档图像处理技术趋势
LLM 时代,文档图像处理技术在不断演进,郭丰俊博士从三个方面来介绍文档图像处理技术趋势:
- 输入:在输入端主要使用多模态的方法,这些方法允许系统同时处理不同的数据模态,如文本、图像和语音,从而提高了系统对多种感知信息的综合理解和处理能力
- 架构:使用通用的
Transformer Encoder / Decoder架构,它使多模态模型能够处理各种数据类型,实现综合的多模态理解和生成。 - 数据:对于多模态的
Transformer模型,需要大规模且高质量的数据来训练模型,以获得最佳性能。
3、LLM时代文档图像技术机会
GPT-4V 的到来,是否会对会对正在做 OCR、NLP 领域的研究者造成危机感呢?郭丰俊博士提出虽然新技术的诞生会引起更多的关注,但是 OCR 依然是一个很重要的技术。如今我们想要训练一个大模型,不管是参与人的模型还是像 GPT-4V,都需要大规模的数据,而 OCR 在提供数据方面是一个非常好的工具,OCR 不仅能够高效录入数据,并且还能够处理不同格式的的数据。
4、MLLM时代文档图像处理技术趋势
下面是一些在文档图像处理方面比较知名的系统。
- BLIP2 – Saleforce:Q-Former连接图像编码器(ViT)和LLM解码器; 仅需训练Q-Former部分
- Flamingo – DeepMind:在LLM中增加Gated Attention层引入视觉信息
- LLaVA – Miscrosoft:将CLIP ViT-L和LLaMA采用全连接层连接; 使用GPT-4和Self-Instruct生成高质量的158k instruction following数据
- MiniGPT – Vision CAIR Group, KAUST:ViT+ Q-Former + Vicuna
- Nougat – Meta:Swin Transformer + Transformer Decoder 图像到序列范式; 820万页文档的数据集
- Kosmos-2.5:Swin Transformer + Transformer Decoder 范式; 3.2亿的数据和1.3B的模型达到远超Nougat等Sota指标
- Donut – NAVER:无需OCR, 用于文档理解的Transformer模型
5、知名文档图像大模型OCR性能分析
经过系统测评显示系统性能还需要进一步提高,郭丰俊博士提出可能是以下原因:
-
视觉编码器的分辨率限制: OCR 系统中的视觉编码器通常用于处理文档图像,从中提取文本信息。如果视觉编码器的分辨率不足,可能导致文本识别的准确性下降。提高视觉编码器的分辨率和图像处理能力可能是提升性能的一种途径。
-
训练数据限制: OCR 系统的性能通常受到训练数据的质量和多样性的影响。如果训练数据不足或不具代表性,系统可能难以应对各种文档类型、字体和排版风格。增加训练数据的数量和多样性可以改善性能。

二、图像安全
随着生成式的人工智能快速发展,越来越多的系统都能够生成图像,图像的真伪以及安全也越发重要。AI 图像安全为 AIGC 健康发展、规模化应用保驾护航,解决负面社会问题。
下图展示了 AI 图像安全在文档图像的篡改以及人脸真伪具体案例:
1、篡改种类
图像篡改指的是对数字图像的未经授权或欺骗性修改,以改变图像的内容或意义。分为四种类型:复制移动、拼接、擦出、重打印。下面给出证件照原始图,对图像篡改的四种类型一一解释,以身份证背面图为例,具体如下:

2、系统架构
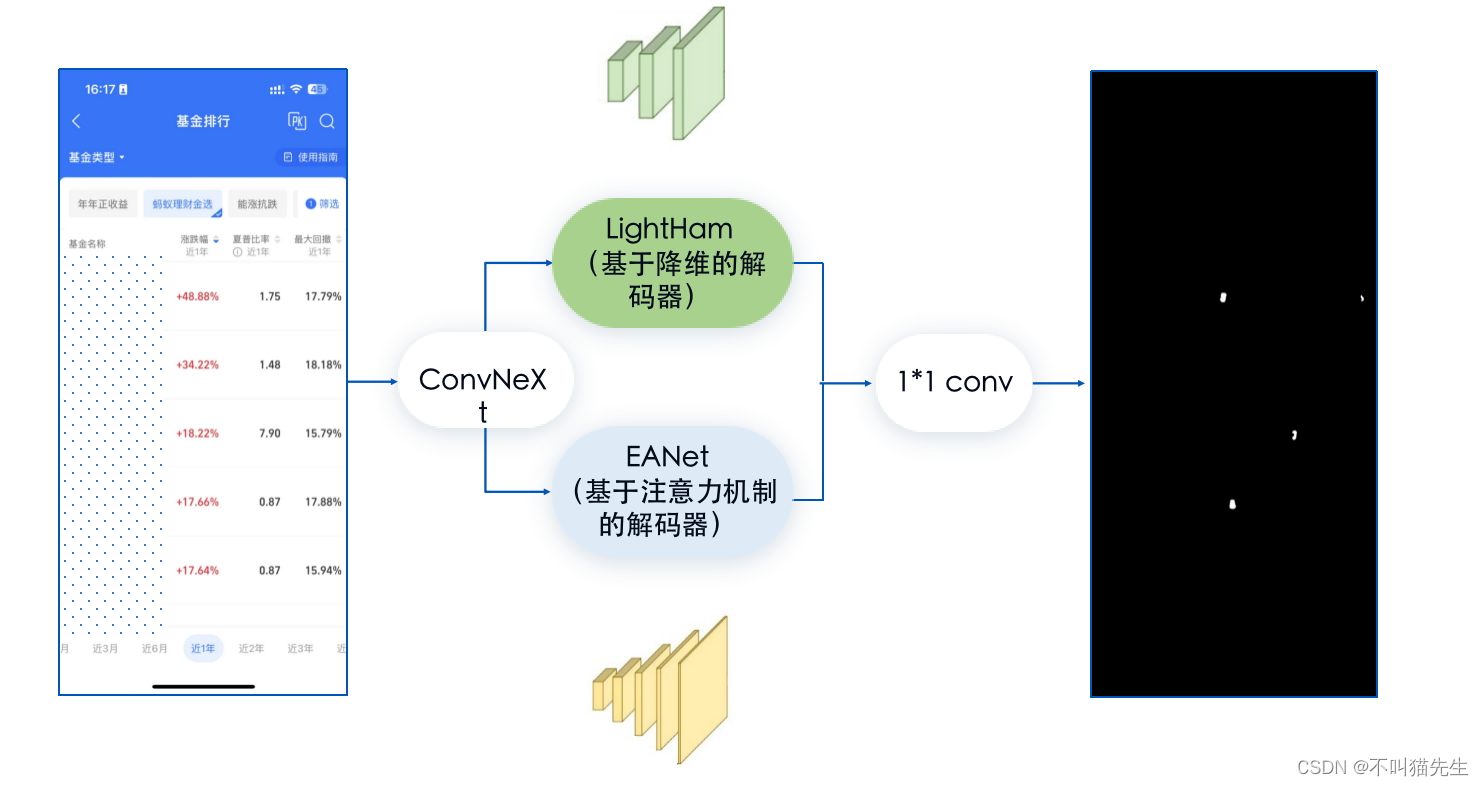
合合信息在处理图像篡时基于分割模型的图像处理,Backbone使用ConvNeXt作为编码器,使用LightHam和EANet两个网络并行作为解码器。充分利用了编码器-解码器结构,其中编码器负责提取特征,解码器负责还原图像并执行分割。并行使用两个不同的解码器可以提供更多的特征表示和捕获能力,从而增强了分割性能。
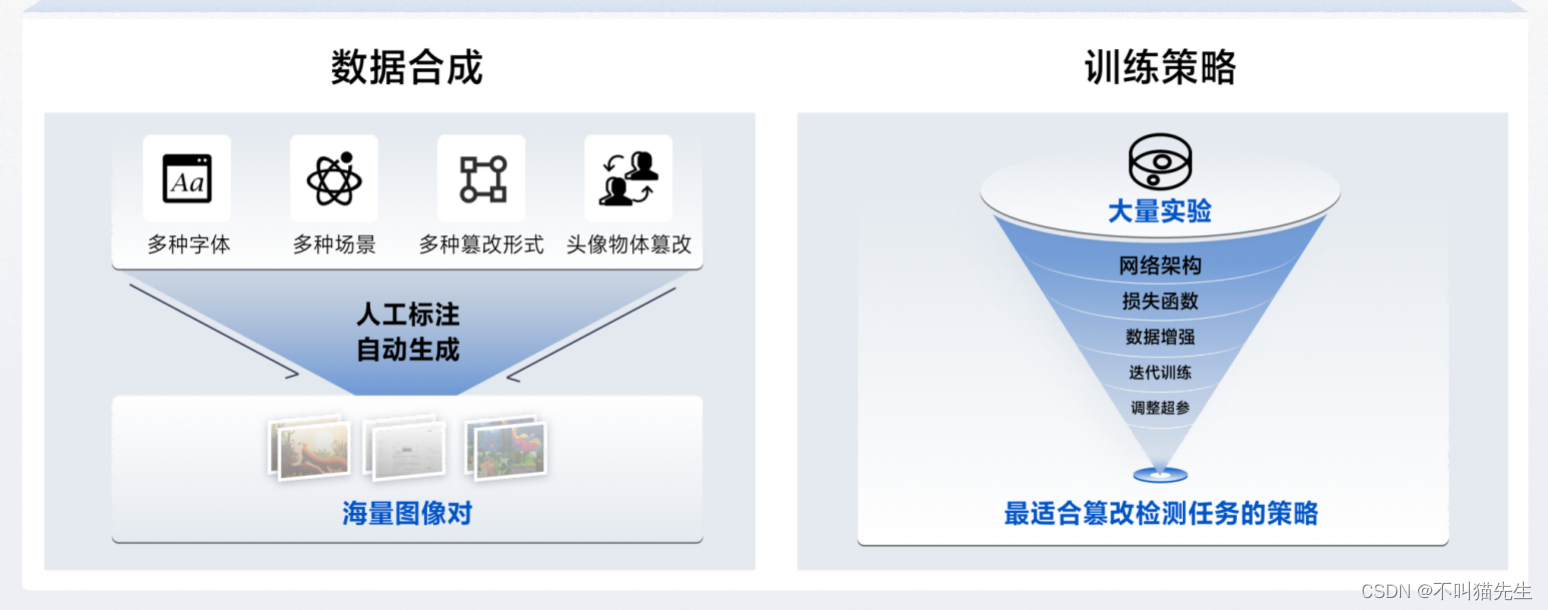
在文档图像处理时,郭丰俊博士提到有两个挑战的方面:一个是大量数据的构建,构建大规模且高质量的数据集对于训练文档图像处理模型至关重要。这些数据集应该包括多种字体、多种场景、多种篡改形式、头像物体篡改,以覆盖各种应用场景;另一个是训练策略,需要不断进行优化调整。 在深度学习中,选择合适的训练策略对于模型性能至关重要。这包括超参数的调整、学习率的优化、数据增强方法的选择以及模型的选择。不断调整和优化这些策略可以帮助提高模型的性能,使其在文档图像处理任务中更加强大和可靠。
3、文档图像处理开放平台
合合信息针对文档图像处理,提供了PS检测开放平台,供开发者进行免费测试。基于自研篡改检测系统,可以判断图片是否被篡改,支持包含身份证、护照、驾驶证、行驶证、教师资格证,港澳通行证、海外身份证等证照,及增值税发票、普通发票、小票、合同等文档。该产品具有独特的优势:
- 准确率高:基于海量的图片样本训练模型,针对图片模糊、倾斜、翻转等情况进行专项优化,鲁棒性强,总体识别准确率行业靠前。
- 服务稳定:提供高可靠性、弹性可伸缩、高并发承载的云端服务,扩展性好,算法的持续迭代优化对用户使用稳定性无影响。
- 多样部署:提供公有云 API 以及私有化部署两种方式。
4、AIGC假图鉴别
在安全领域,合合信息紧跟时代步伐做了生成式AI的鉴别工作,主要包括身份验证与访问控制、移动设备的安全检测、数字图像真实鉴定。比如我们现在有些手机、电脑、门禁等的解锁或可以使用人脸就可以解密,还有一些 ToB 的业务, 比如银行的很多业务都需要面临生成式 AI 造假带来的压力。
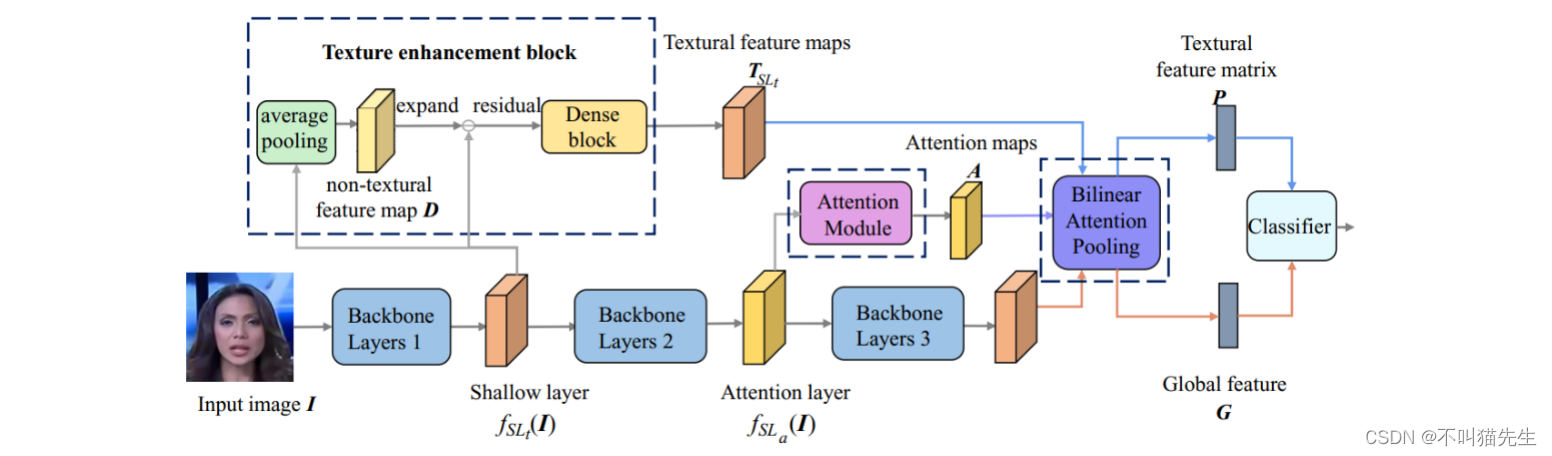
它的系统架构师怎么实现的呢?郭丰俊博士以人脸鉴别场景为例,提出该鉴别体系的架构是通过通过多个空间注意力头来关注空间特征,并使用纹理增强模块放大浅层特征中的细微伪影,增强模型对真实人脸和伪造人脸的感知与判断准确度,其中纹理的细节变化是人脸鉴别的一个非常重要的依据。
5、图像篡改检测标准制定
关于图像篡改检测标准,合合信息将与中国信通院、中国图象图形学学会、中国科学技术大学一起共建并推动图像篡改监测标准,为文档图像内容安全提供可靠保障,提高图像篡改检测的一致性,推动技术创新,助力新时代AI安全体系建立。通过推动这一标准的制定和实施将有助于构建更可靠的 AI 安全体系,不仅对文档图像内容的安全具有重要意义,还可以在广泛的应用领域中推动数字安全和隐私保护。
最后
多模态模型的发展呈现出巨大的潜力,这些模型在深度学习领域中变得越来越重要。合合信息深耕智能文字识别以及商业大数据领域,结合模式识别、图像处理、神经网络、深度学习、STR、NLP打造智能文字识别服务平台,结合隐私计算、知识图谱打造商业大数据技术与资产平台,产品覆盖B端、C端,深受全球用户的喜爱。未来期待可以看到合合信息更多关于多模态模型在金融、零售、证券等领域的创新和应用,用技术方案服务更多的人群。