Kafka与Spark案例实践
1.概述
Kafka系统的灵活多变,让它拥有丰富的拓展性,可以与第三方套件很方便的对接。例如,实时计算引擎Spark。接下来通过一个完整案例,运用Kafka和Spark来合理完成。
2.内容
2.1 初始Spark
在大数据应用场景中,面对实时计算、处理流数据、降低计算耗时等问题时,Apache Spark提供的计算引擎能很好的满足这些需求。
Spark是一种基于内存的分布式计算引擎,其核心为弹性分布式数据集(Resilient Distributed Datasets简称,RDD),它支持多种数据来源,拥有容错机制,数据集可以被缓存,并且支持并行操作,能够很好的地用于数据挖掘和机器学习。
Spark是专门为海量数据处理而设计的快速且通用的计算引擎,支持多种编程语言(如Java、Scala、Python等),并且拥有更快的计算速度。
提示: 据Spark官方数据统计,通过利用内存进行数据计算,Spark的计算速度比Hadoop中的MapReduce的计算速度快100倍左右。
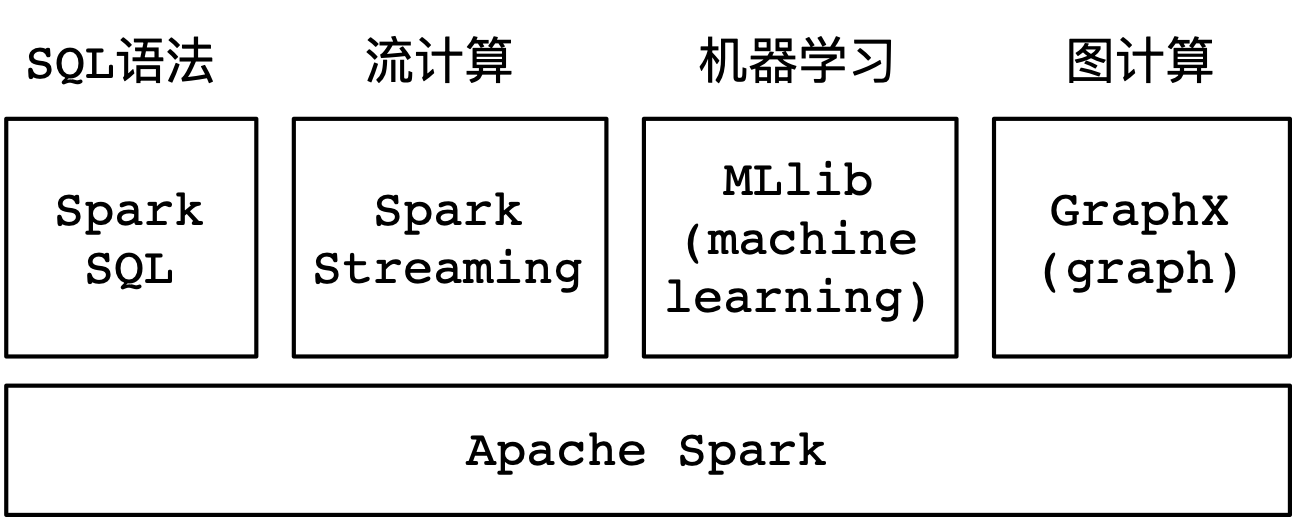
另外,Spark提供了大量的库,其中包含Spark SQL、Spark Streaming、MLlib、GraphX等。在项目开发的过程当中,可以在同一个应用程序中轻松地组合使用这些类库,如下图所示:
2.2 Spark SQL
Spark SQL是Spark处理结构化数据的一个模块,。与Spark的RDD应用接口不同,Spark SQL提供的接口更加偏向于处理结构化的数据。在使用相同的执行引擎时,不同的应用接口或者编程语言在做计算时都是相互独立的,。这意味着,用户在使用时,可以很方便的地在不同的应用接口或编程语言之间进行切换。
Spark SQL很重要的一个优势就是,可以通过SQL语句来实现业务功能,。Spark SQL可以读取不同的存储介质,例如Kafka、Hive、HDFS等。
在使用编程语言执行一个Spark SQL语句时,执行后的结果会返回一个数据集,用户可以通过使用命令行、JDBC、ODBC的方式与Spark SQL进行数据交互。
提示: JDBC是一个面向对象的应用程序接口,通过它可以访问各类关系型数据库。 ODBC是微软公司开放服务结构中有关数据库的一个组成部分,它制定并提供了一套访问数据库的应用接口。
2.3 Spark Streaming
Spark Streaming是Spark核心应用接口的一种扩展,它可以用于进行大规模数据处理、高吞吐量处理、容错处理等场景。同时,Spark Streaming支持从不同的数据源中读取数据,并且能够使用聚合函数、窗口函数等这类复杂算法来处理数据。
处理后的数据结果可以保存到本地文件系统(如文本)、分布式文件系统(如HDFS)、关系型数据库(如MySQL)、非关系型数据库(如HBase)等存储介质中。
2.4 MLlib
MLlib是Spark的机器学习(Machine Learning)类库,目的在于简化机器学习的可操作性和易扩展性。
MLlib由一些通用的学习算法和工具组成,其内容包含分类、回归、聚类、协同过滤等。
2.5 GraphX
GraphX是构建在Spark之上的图计算框架,它使用RDD来存储图数据,并提供了实用的图操作方法。
由于RDD的特性,GraphX高效的地实现了图的分布式存储和处理,可以应用于社交网络这类大规模的图计算场景。
3.操作Spark命令
在$SPARK_HOME/bin目录中,提供了一系列的脚本,例如spark-shell、spark-submit等。
进入到Hadoop集群,准备好数据源并将数据源上传Hadoop分布式文件系统(HDFS)中。然后使用Spark Shell的方式读取HDFS上的数据,并统计单词出现的频率,具体操作步骤如下。
1.准备数据源
(1)在本地创建一个文本文件,并在该文本文件中添加待统计的数据,具体操作命令如下。
# 新建文本文件 [hadoop@dn1 tmp]$ vi wordcount.txt
(2)然后,在wordcount.txt文件中添加待统计的单词,内容如下。
kafka spark hadoop spark kafka hadoop kafka hbase
2.上传数据源到HDFS
(1)将本地准备好的wordcount.txt文件上传到HDFS中,具体操作命令如下。
# 在HDFS上创建一个目录 [hadoop@dn1 tmp]$ hdfs dfs -mkdir -p /data/spark # 上传wordcount.txt到HDFS指定目录 [hadoop@dn1 tmp]$ hdfs dfs -put wordcount.txt /data/spark
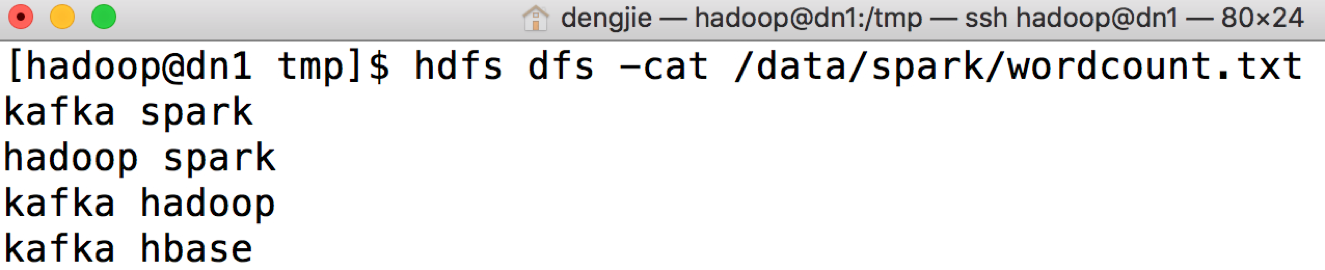
(2)然后,执行HDFS查看命令,验证本地文件是否上传成功,具体操作命令如下。
# 查看上传的文件是否成功 [hadoop@dn1 tmp]$ hdfs dfs -cat /data/spark/wordcount.txt
若查看命令执行成功,输出结果如图所示:
3.使用Spark Shell统计单词出现频
(1)进入到$SPARK_HOME/bin目录,然后运行./spark-shell脚本进入到Spark Shell控制台。
提示: 如果直接执行该脚本,则表示以本地模式单线程方式启动。 如果执行./spark-shell local[n]命令,则表示以多线程方式启动,其中变量n代表线程数。
(2)通过本地模式运行,等待Spark加载配置文件,加载完成后,输出结果
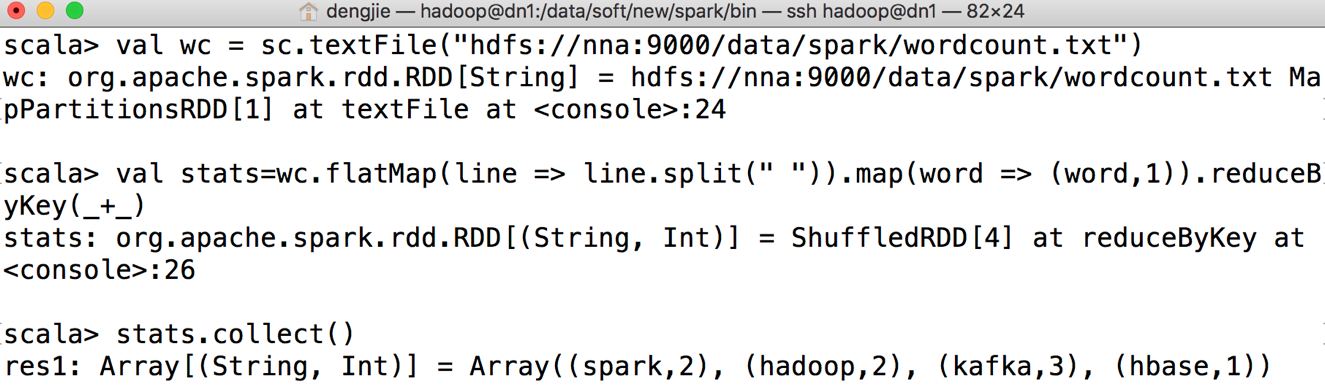
(3)统计单词出现的频率,具体实现如下:
![]()
val wc = sc.textFile("hdfs://nna:9000/data/spark/wordcount.txt")
val stats=wc.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
stats.collect()
提示:
第一行代码表示,读取HDFS上待统计单词的原始数据;
第二行代码表示,实现统计单词出现频率的具体业务逻辑;
第三行代码表示,从弹性分布式数据集(RDD)中获取数据,并以数组的形式展示统计结果。
![]()
(4)执行上述代码后,Spark Shell控制台输出结果如图所示:
4.案例实践
Kafka是一种实时消息队列技术,通过Kafka中间件,可以构建实时消息处理平台来满足企业的实时类需求。
本案例以Kafka为核心中间件,以Spark作为实时计算引擎,来完成对游戏明细数据的实时统计。
以本项目为例,需要实时描绘当天游戏用户的行为轨迹,例如用户订单、用户分布、新增用户等指标数据。针对这类需求,可以将游戏用户实时产生的业务数据上报到Kafka消息队列系统进行存储,然后通过Spark流计算的方式来统计应用指标。最后,将统计后的业务结果形成报表或者趋势图进行展示,为制作数据方案者提供数据支持。
4.1 背景和价值
1. 背景
在实时应用场景中,与离线统计任务有所不同。它对时延的要求比较高,需要缩短业务数据计算的时间。对于离线任务来说,通常是计算前一天或者更早的业务数据。
现实业务场景中,很多业务场景需要实时查看统计结果。流计算能够很好的弥补这一不足之处,对于当天变化的流数据可以通过流计算(比如Flink、Spark Streaming、Storm等)后,及时呈现报表数据或趋势图。
2. 价值
这样一个实时计算项目能够实时掌握游戏用户的行为轨迹、活跃度。具体涉及的内容如下:
- 通过对游戏用户实时产生的业务数据进行实时统计,可以分析出游戏用户在各个业务模块下的活跃度、停留时间等。将这些结果形成报表或者趋势图,让以便能够实时地准确的掌握游戏用户的行为轨迹;
- 按小时维度将当天的实时业务数据进行统计,那么可以知道游戏用户在哪个时间段具有最高的访问量。利用这些数据可以针对这个时间段做一些推广活动,例如道具“秒杀”活动、打折优惠等,从而刺激游戏用户去充值消费。
- 将实时计算产生的结果,去发挥它应有的价值。在高峰时间段推广一些优惠活动后,通过实时统计的数据结果分析活动的效果,例如促销的“秒杀”活动、道具打折等这些活动是否受到游戏用户的喜爱。针对这些反馈效果,可以做出快速合理的反应。
4.2 实现流程
架构体系可以分为数据源、数据采集、数据存储、流计算、结果持久化、服务接口、数据可视化等,实现流程图如图所示:
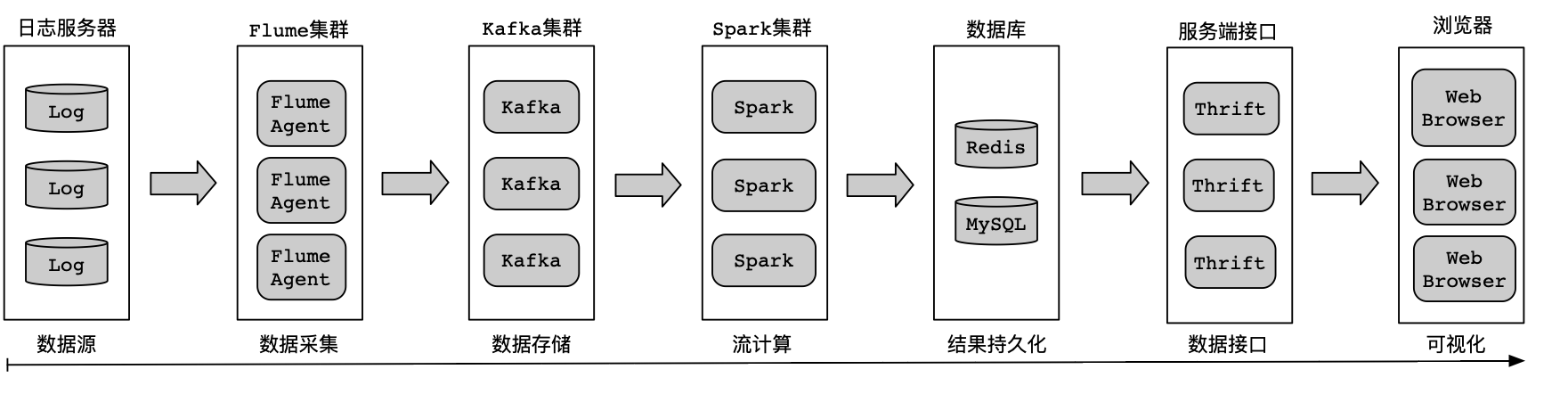
1. 数据源
游戏用户通过移动设备或者浏览器操作游戏产生的记录,会实时上报到日志服务器进行存储,数据格式会封装成JSON对象进行上报,便于后续消费解析。
2. 数据采集
在日志服务器中部署Flume Agent来实时监控上报的业务日志数据,。当业务日志数据有更新(可通过文件MD5值、文件日期等来判断文件的变动)时,由Flume Agent启动采集任务,通过Flume Sink组件配置Kafka集群连接地址进行数据传输。
3. 数据存储
利用Kafka的消息队列特性来存储消息记录。将接收的数据按照业务进行区分,以不同的Topic来存储各种类型的业务数据。
4. 流计算
Spark拥有实时计算的能力,使用Spark Streaming将Spark和Kafka关联起来。
通过消费Kafka集群中指定的Topic来获取业务数据,并将获取的业务数据利用Spark集群来做实时计算。
5. 结果持久化
通过Spark计算引擎,将统计后的结果存储到数据库,方便可视化系统查询展示。
选用Redis和MySQL来作为持久化的存储介质,在Spark代码逻辑中使用对应的编程接口(如Java Redis API或Java MySQL API)将计算后的结果存储到数据库。
6. 数据接口
数据库中存储的统计结果需要对外共享,可以通过统一的接口服务对外提供访问。
可以选择Thrift框架来实现数据接口,编写RPC服务供外界访问。
提示: Apache Thrift是一个软件框架,用来进行可扩展且跨编程语言服务的开发工作。 Apache Thrift结合了功能强大的软件堆栈和代码生成引擎,可以与Java、Go、Python、Ruby等编程语言进行无缝连接。
7. 可视化
从RPC服务中获取数据库中存储的统计结果。然后,在浏览器中将这些结果进行渲染,以报表和趋势图表的形式进行呈现。
5.核心逻辑实现
通过读取Kafka系统Topic中的流数据,对平台号进行分组统计。每隔10秒钟,将相同平台号下用户金额进行累加计算,并将统计后的结果写入到MySQL数据库。
5.1 MySQL工具类实现
![]()
/**
* 实现一个MySQL工具类.
*
* @author smartloli.
*
* Created by Jul 15, 2022
*/
public class MySQLPool {
private static LinkedList<Connection> queues; // 声明一个连接队列
static {
try {
Class.forName("com.mysql.jdbc.Driver"); // 加载MySQL驱动
} catch (ClassNotFoundException e) {
e.printStackTrace(); // 打印异常信息
}
}
/** 初始化MySQL连接对象. */
public synchronized static Connection getConnection() {
try {
if (queues == null) { // 判断连接队列是否为空
queues = new LinkedList<Connection>(); // 实例化连接队列
for (int i = 0; i < 5; i++) {
Connection conn = DriverManager
.getConnection("jdbc:mysql://nna:3306/game", "root", "123456");
queues.push(conn); // 初始化连接队列
}
}
} catch (Exception e) {
e.printStackTrace(); // 打印异常信息
}
return queues.poll(); // 返回最新的连接对象
}
/** 释放MySQL连接对象到连接队列. */
public static void release(Connection conn) {
queues.push(conn); // 将连接对象放回到连接队列
}
}
![]()
5.2 Spark逻辑实现
实现按平台号分组统计用户金额,具体实现见代码:
![]()
/**
* 使用Spark引擎来统计用户订单主题中的金额.
*
* @author smartloli.
*
* Created by Jul 14, 2022
*/
public class UserOrderStats {
public static void main(String[] args) throws Exception {
// 设置数据源输入参数
if (args.length < 1) {
System.err.println("Usage: GroupId <file>"); // 打印提示信息
System.exit(1); // 退出进程
}
String bootStrapServers = "dn1:9092,dn2:9092,dn3:9092"; // 指定Kafka连接地址
String topic = "user_order_stream"; // 指定Kafka主题名
String groupId = args[0]; // 动态获取消费者组名
SparkConf sparkConf = new SparkConf()
.setMaster("yarn-client")
.setAppName("UserOrder"); // 实例化Spark配置对象
// 实例化一个SparkContext对象, 用来打印日志信息到控制台, 便于调试
JavaSparkContext sc = new JavaSparkContext(sparkConf);
sc.setLogLevel("WARN");
// 创建一个流对象, 设置窗口时间为10秒
JavaStreamingContext jssc = new JavaStreamingContext(sc, Durations.seconds(10));
JavaInputDStream<ConsumerRecord<Object, Object>> streams =
KafkaUtils.createDirectStream(jssc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(Arrays.asList(topic),
configure(groupId, bootStrapServers))); // 获取流数据集
// 将Kafka主题(user_order_stream)中的消息转化成键值对(key/value)形式
JavaPairDStream<Integer, Long> moneys =
streams.mapToPair(new PairFunction<ConsumerRecord<Object, Object>,
Integer, Long>() {
/** 序列号ID. */
private static final long serialVersionUID = 1L;
/** 执行回调函数来处理业务逻辑. */
@Override
public Tuple2<Integer, Long> call(ConsumerRecord<Object, Object> t)
throws Exception {
JSONObject object = JSON.parseObject(t.value().toString());
return new Tuple2<Integer, Long>(object.getInteger("plat"),
object.getLong("money"));
}
}).reduceByKey(new Function2<Long, Long, Long>() {
/** 序列号ID. */
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2; // 通过平台号(plat)进行分组聚合
}
});
// 将统计结果存储到MySQL数据库
moneys.foreachRDD(rdd -> {
Connection connection = MySQLPool.getConnection(); // 实例化MySQL连接对象
Statement stmt = connection.createStatement(); // 创建一个操作MySQL的实例
rdd.collect().forEach(line -> {
int plat = line._1.intValue(); // 获取平台号
long total = line._2.longValue(); // 获取用户总金额
// 将写入到MySQL的数据,封装成SQL语句
String sql = String.format("insert into `user_order` (`plat`, `total`)
values (%s, %s)", plat, total);
try {
// 调用MySQL工具类, 将统计结果组装成SQL语句写入到MySQL数据库
stmt.executeUpdate(sql);
} catch (SQLException e) {
e.printStackTrace(); // 打印异常信息
}
});
MySQLPool.release(connection); // 是否MySQL连接对象到连接队列
});
jssc.start(); // 开始计算
try {
jssc.awaitTermination(); // 等待计算结束
} catch (Exception ex) {
ex.printStackTrace(); // 打印异常信息
} finally {
jssc.close(); // 发生异常, 关闭流操作对象
}
}
/** 初始化Kafka集群信息. */
private static Map<String, Object> configure(String group, String brokers) {
Map<String, Object> props = new HashMap<>(); // 实例化一个配置对象
props.put("bootstrap.servers", brokers); // 指定Kafka集群地址
props.put("group.id", group); // 指定消费者组
props.put("enable.auto.commit", "true"); // 开启自动提交
props.put("auto.commit.interval.ms", "1000"); // 自动提交的时间间隔
// 反序列化消息主键
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
// 反序列化消费记录
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
return props; // 返回配置对象
}
}
![]()
5.3 执行提交
将打包好的应用程序上传到Spark集群的其中一个节点,然后通过spark-submit脚本来调度应用程序,具体操作命令如下。
# 执行应用程序 [hadoop@dn1 bin]$ ./spark-submit --master yarn-client --class org.smartloli.kafka.game.x.book_11.jubas.UserOrderStats --executor-memory 512MB --total-executor-cores 2 /data/soft/new/UserOrder.jar ke6
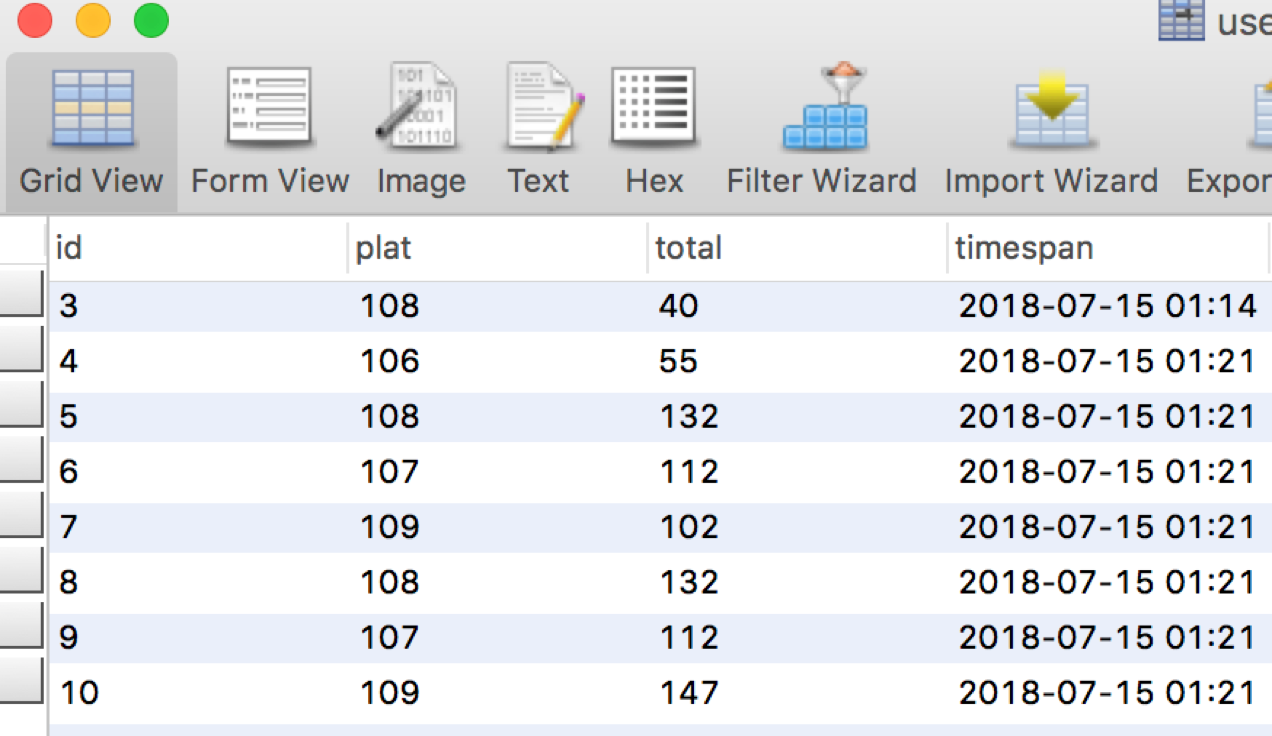
5.4 结果预览